🌊
論文メモ: WaveFlow - 2次元畳み込みによる軽量なFlowベースの会話生成モデル
論文
WaveFlow: A Compact Flow-based Model for Raw Audio
一言で
WaveGlow[1]と同様のFlowベースの会話生成モデル。WaveGlowの1次元畳み込みを2次元畳み込みにしたり、アフィン変換レイヤの受容野を広げることで、精度を保ちつつパラメータ数を小さくすることに成功した。
何がすごいか?
- 音声品質を保ったまま、モデルのパラメータ数の削減を実現(WaveGlowの1/15)
- 既存の提案手法(WaveGlow, WaveNet/autoregressive flow (AF))を統一的に解釈する枠組みを示した
- 高効率で会話生成が可能(22.05 kHzのサンプルレートの高音質の音源をリアルタイムの40倍の速度で生成可能)
既存の研究に対する提案手法の位置付け
Flowベースの会話生成モデル
各層における変換処理の違いによって以下のように分類できる
Autoregressinve transform
- Autoregressive flow (AF): 学習は並列処理が可能だが、生成時は直列処理で遅い。
- Inverce Autoregressive flow (IAF): 生成時は並列処理が可能だが、学習時は直列処理で遅い。
bipartile transform
- RealNVP
- WaveGlow: 学習時、生成時ともに並列処理が可能だが、過去の情報を限定的にしか利用しない(図1)ため、1層の処理が単純である。このため、十分な精度を出すためにはネットワークの層を増やす必要がある。
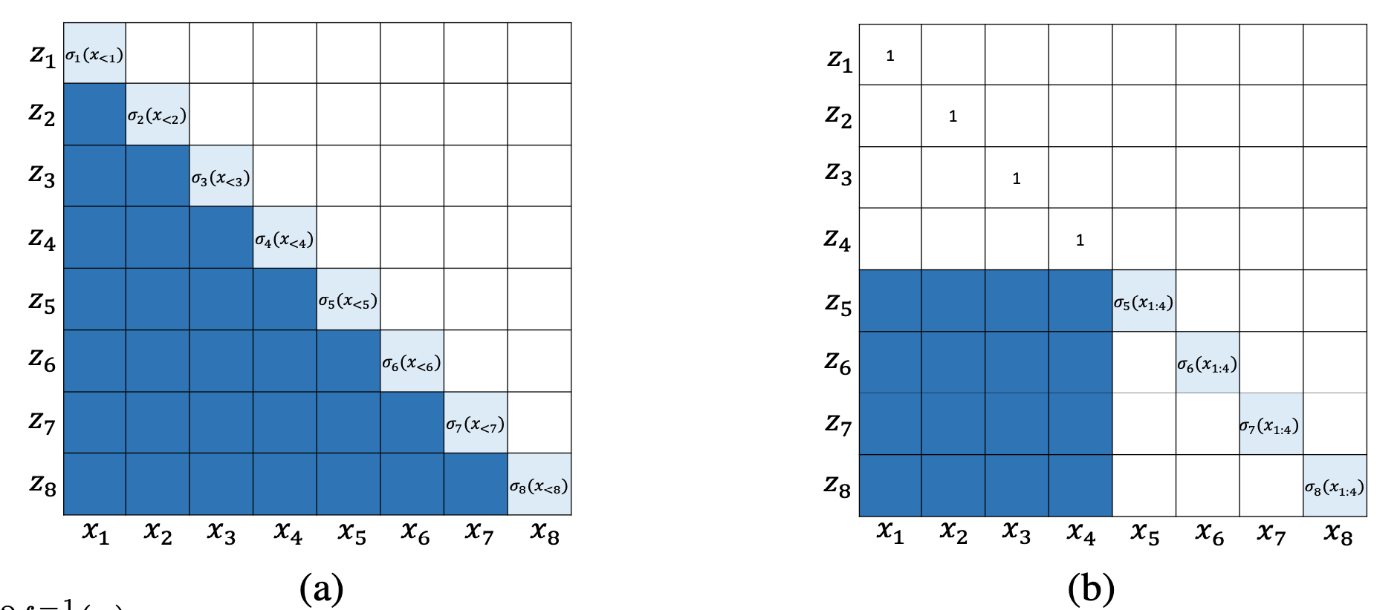
図1: 既存手法のヤコビアン: a) autoregressive transform, b) bipartile transform。自己回帰モデルの場合は過去の時点の全ての情報を参照するため
列方向にAutoregressiveだが行方向は並列処理可能なモデル
- WaveFlow(提案手法): WaveGlowに比べて過去の情報を多く用いること(図2)、また、2次元畳み込みによってより広い範囲の情報の相関を学習することで、WaveGlowと同じ精度を実現するためのパラメータ数が小さくてすむ。
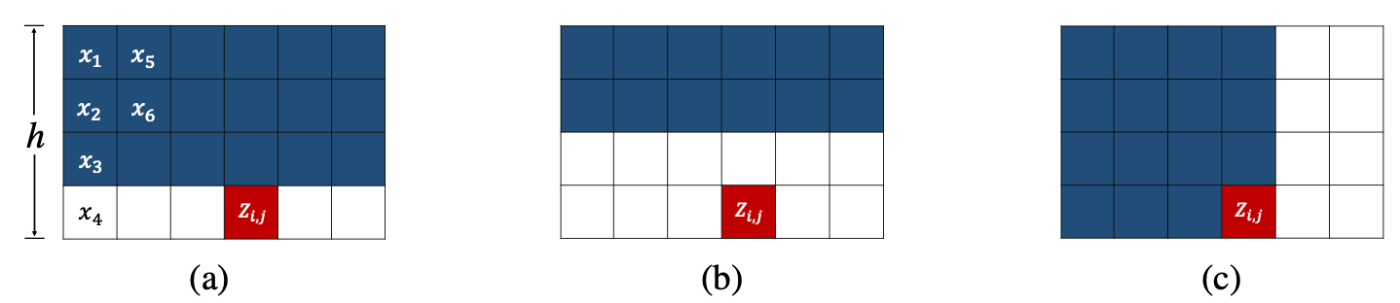
図2: Squeeze処理後の入力テンソルの受容野: a) WaveFlow, b) WaveGlow, c) AF。WaveGlowは常に半分の受容野しか利用しないのに対し、WaveFlowでは列方向に上にある情報を全て利用する。これらはともに過去だけでなく未来の情報も参照する。
所感
- 既存のFlowベースのモデルを統一的な説明を与えていて、関連手法をまとめて理解するのに役立った。
- WaveGlowのモデルとの比較が不十分に思える。WaveFlowはhを可変にしているのにWaveGlowは固定にしている。
- WaveGlowは図2において
h - 2次元畳み込みのアルゴリズムとアフィン変換のアルゴリズムを両方変えているので、パラメータ数を大きく減らすのに貢献したのがどちらか気になった。
Discussion