[論文要約] URT: Self-AttentionによるFew-Shot画像分類のための普遍表現の学習
論文
A Universal Representation Transformer Layer for Few-Shot Image Classification
概要
Few-Shot画像分類タスクでは、通常1つのドメインに対して最適化した表現を学習するが、本研究では複数のドメインに対して普遍的に適用できる表現の学習を目指す。本研究はSelf-Attensionを使って学習ずみの普遍表現からドメイン固有の表現を生成する手法を提案する。
問題設定
サポートセット、クエリセットの定義など基本的な問題設定は[1]と同じである。
一方で、これまでの一般的なFew-Shot学習では「N-Way-K-shot」というように、クラス数Nとサンプル数Kが学習過程を通して固定の値を用いていた。この設定は現実のタスク設定とは乖離していることから、異なるドメインのデータセットからなるMeta-Dataset[2]というデータセットが提案された。
このベンチマークではクラス数N及びサンプル数Kは学習課程において変化しうる。なお、既存のFew-Shot学習同様、訓練用データと評価用データではクラス数の重複は存在しない。
普遍表現
提案手法は既存の手法SUR[3]を発展させたものである。
Vedaldiらは複数のドメインに対して良いパフォーマンスを得られるような表現として、普遍表現[4]という用語を導入した。
これを素朴に実現しようとすると、個々のドメインに対して最適化した特徴抽出ネットワークの個々の出力を結合することが考えられる。別の実現方法は、個々の特徴抽出ネットワーク間で重みをシェアすることであり、Feature-wise Linear Module(FiLM)[5]がそれにあたる。
SURでは個々の特徴抽出ネットワークの出力に対して異なる重みを設定することで、目的のタスクに最適な表現を手動でチューニングする手法を提案した。SURはMeta-Datasetのいくつかで最善のパフォーマンスを達成した。本研究では、SURの手動のチューニングプロセスをメタ学習手法で置き換えることで、SURの代替が可能かどうかを示したものである。
アーキテクチャ
提案モデルのアーキテクチャを図1に示す。
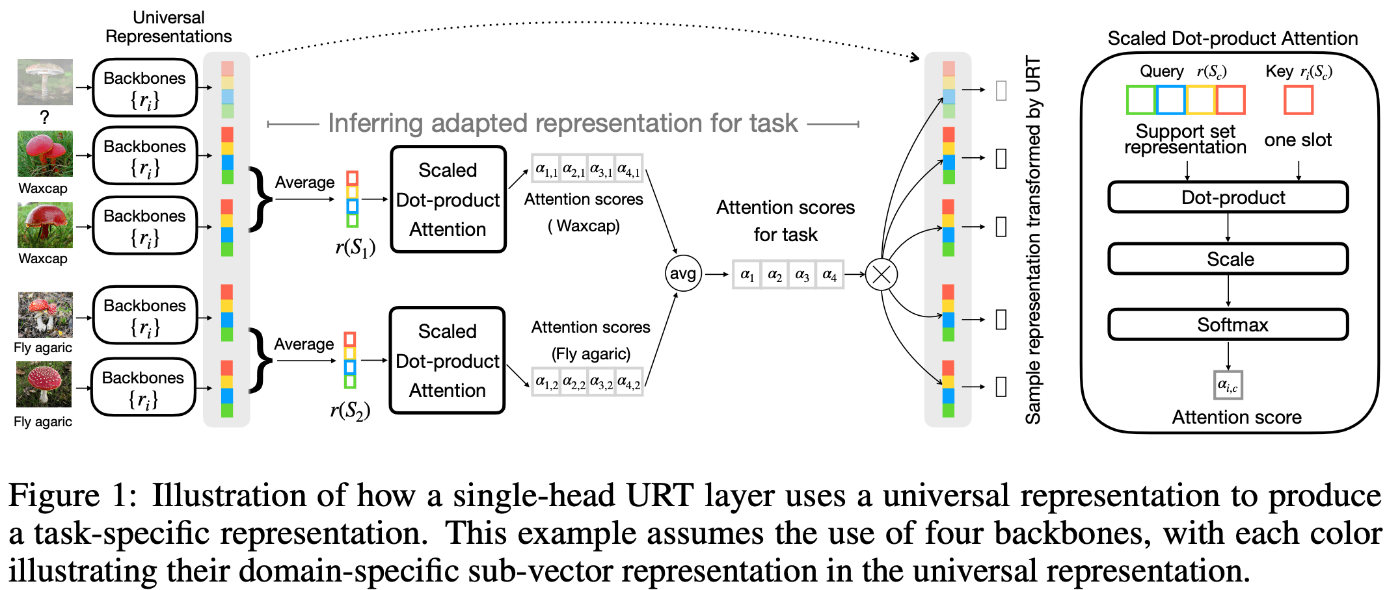
図1: 提案モデルのアーキテクチャ
出力表現の重みの学習
提案手法の目的は、個々のドメインのタスク(ImageNet, Omniglot etc.)に最適化した特徴抽出ネットワークの出力表現の重み(=重要度)を自動で学習することにある。
重みの選択方法として、提案手法ではTransformerで使われているSelf-Attention機構、つまり、key, queryの内積を採用した。
学習方法
本提案手法ではメタ学習を使って表現の重みを学習する。
具体的には、強化学習で用いられるエピソード学習を用いてAlgorithm 1のように実装する(引用にある式の内容については元論文を参照)。

Algorithm 1: メタ学習アルゴリズム
実験結果
提案手法は既存のSOTAであるSURとタイあるいは上回る精度を実現した。
また、推論速度はSURの約10倍を実現した。
所感
- 以下がよくわからなかった
- メタラーニングの部分は結局何を学習しているのか?(数理的なイメージがいまいち掴めていない)
Discussion