論文要約: GraphCodeBERT - コードの変数の依存関係を入力して事前学習したモデル
概要
テキスト、コードに加え、コードの変数の依存関係を表す有向グラフ(=データフロー)の情報を入力し、グラフの構造を加味した2つのタスクで事前学習を行うことで、4つの下位タスクでCodeBERTを抜いてSOTAを達成した。
Abstract: https://arxiv.org/abs/2009.08366v4
研究の特徴
CodeBERTはコードを一方向のシーケンスとして捉えるためコードの構造を意識しない。
例えばv = max_value - min_valueという式において、変数名のみから変数vの役割を推定するのは困難だが、「vが2つの変数max_value, min_valueに依存する」という情報を用いると、変数vの役割を知る手がかりとなる。
先行研究には構文木を利用した研究があるが、本研究では構文木を直接利用せず、そこから抽出したデータフロー(=変数どうしの依存関係を示す有効グラフ)を利用する。このようにすることで、不必要に複雑な構造を持ち込むことを回避している。
アーキテクチャ
データフローの生成プロセスと、入力シーケンスの構造をそれぞれ図に示す。データフローは「変数がどの変数に由来するか」を示した有向グラフで表される。Transformerにはテキスト、コードに加えてデータフローの頂点(=変数)を入力する。
図1
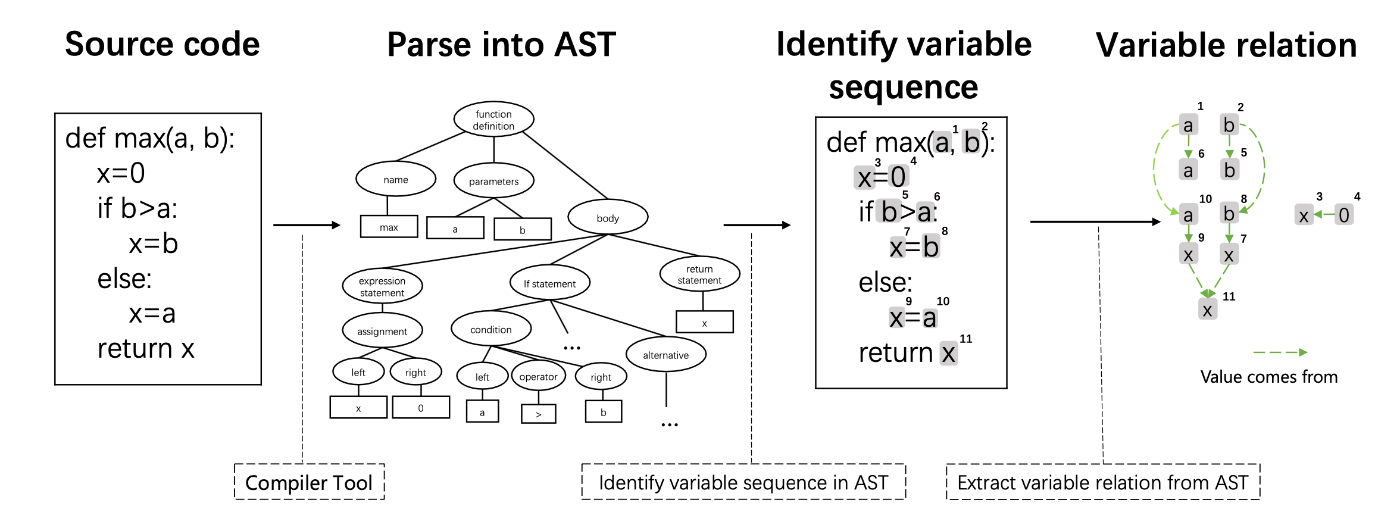
図2
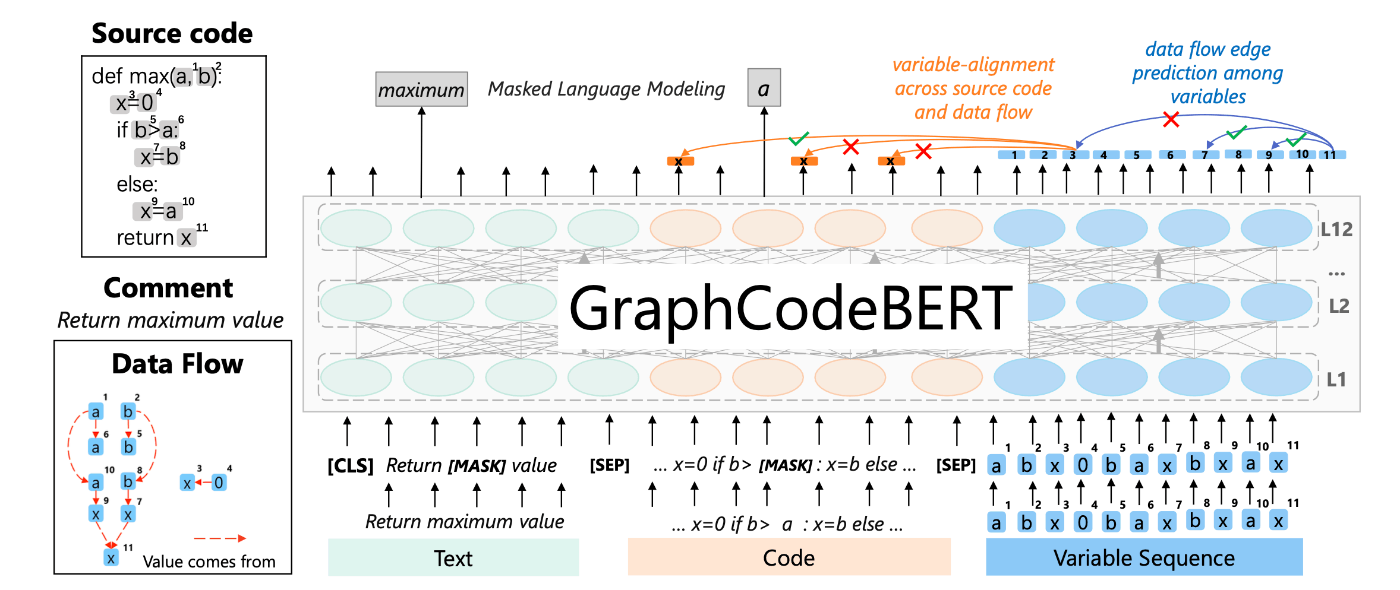
事前学習タスク
本研究で用いられている事前学習タスクは以下の3つ
- Masked Language Modeling: CodeBERTと同じ
- Edge Prediction: ランダムに選択した頂点に隣接する辺のAttention maskを-∞とし、隣接する頂点の確率を予測する(図2)
- Node Alignment: データフロー中の頂点が、コード中のどの変数に対応するかを予測する(図3)
図3
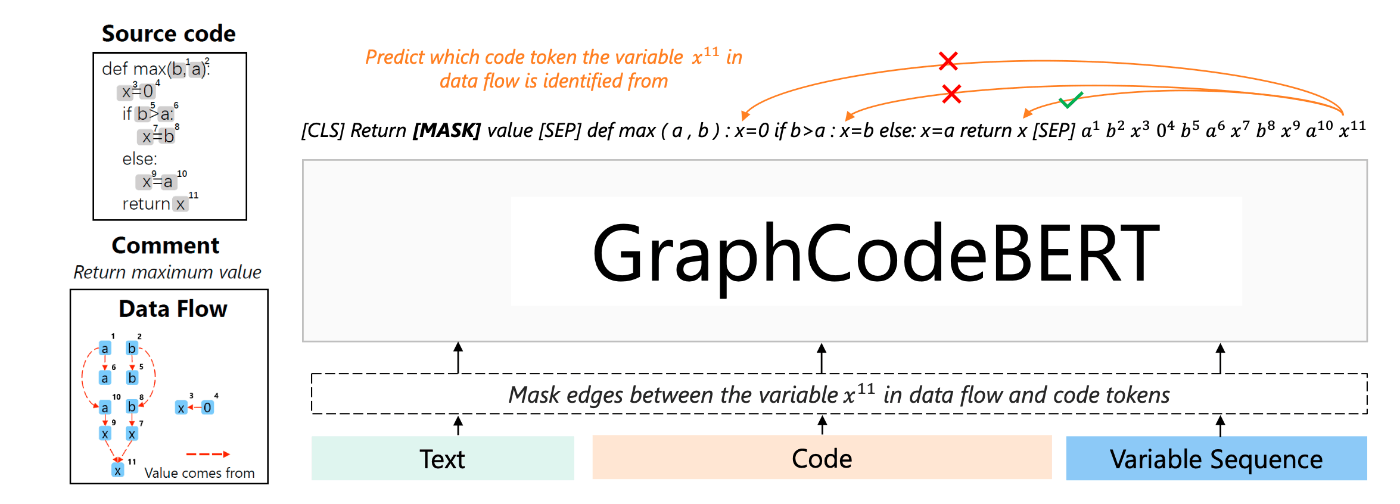
なお、上記の事前学習タスクにおいて、コード及びグラフのattention maskは以下のように定義する。
i. グラフ-グラフ: 隣接辺が存在する頂点以外を
ii. コード-グラフ: 対応が存在する頂点と変数以外を
性能評価
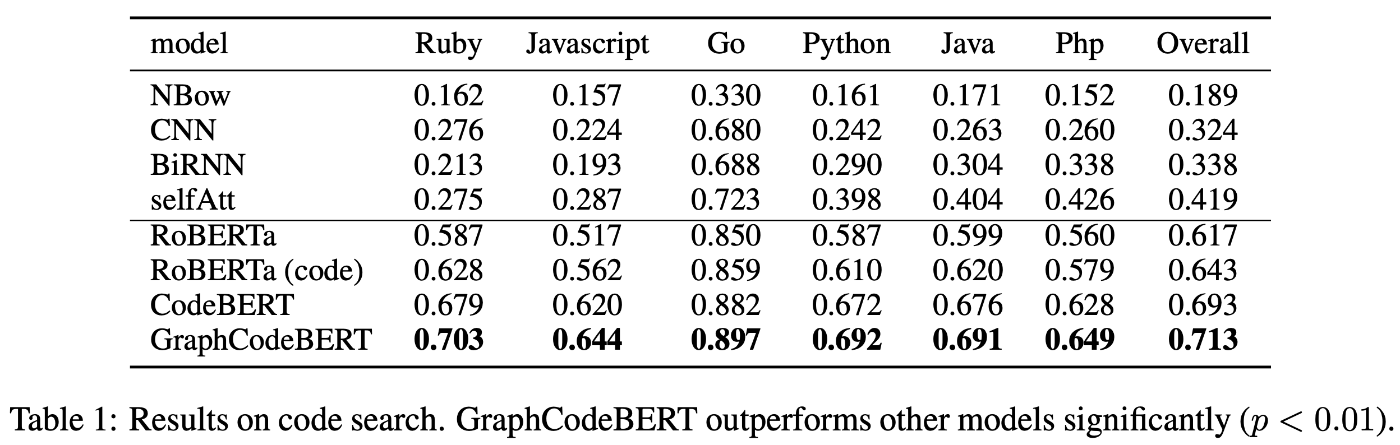
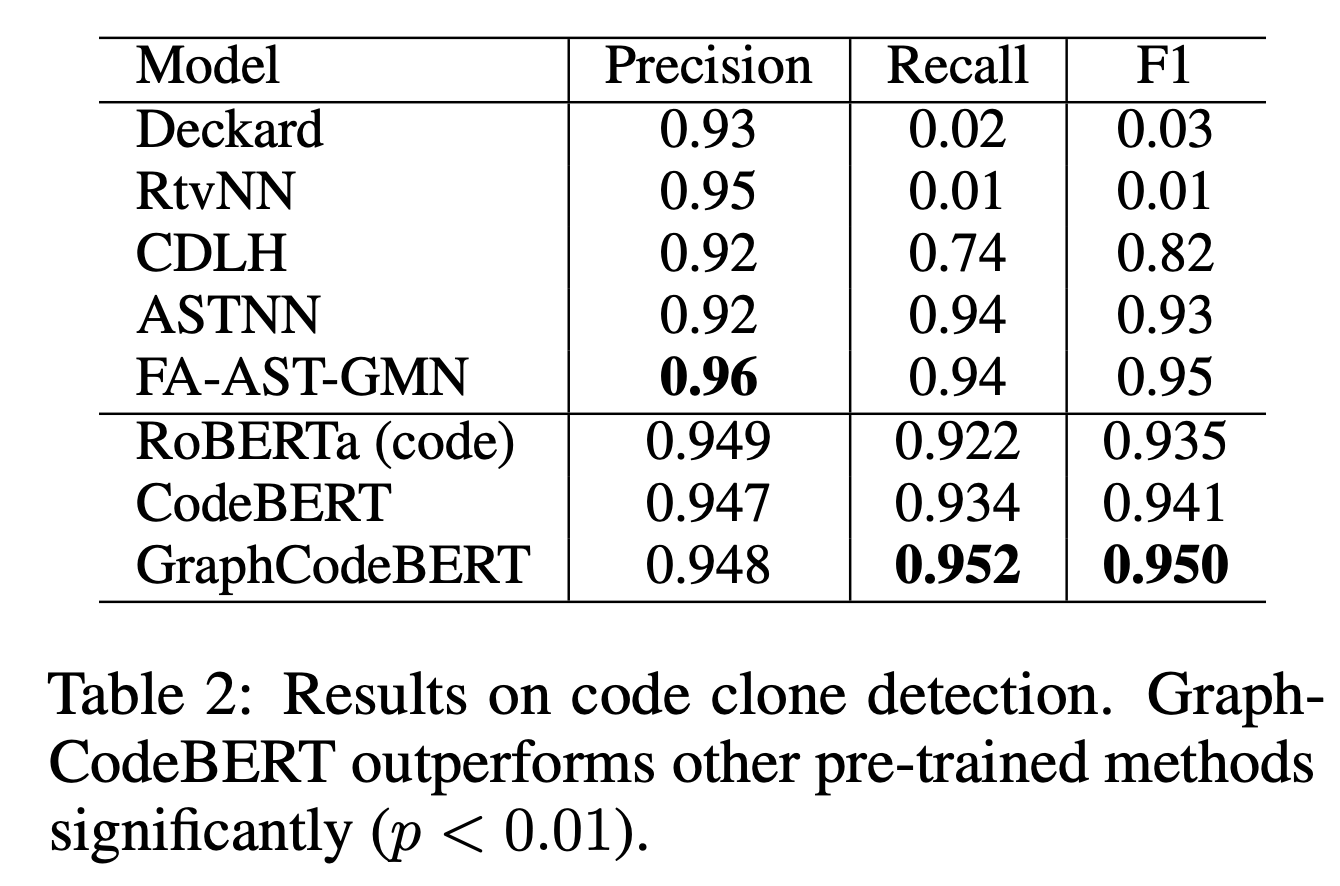
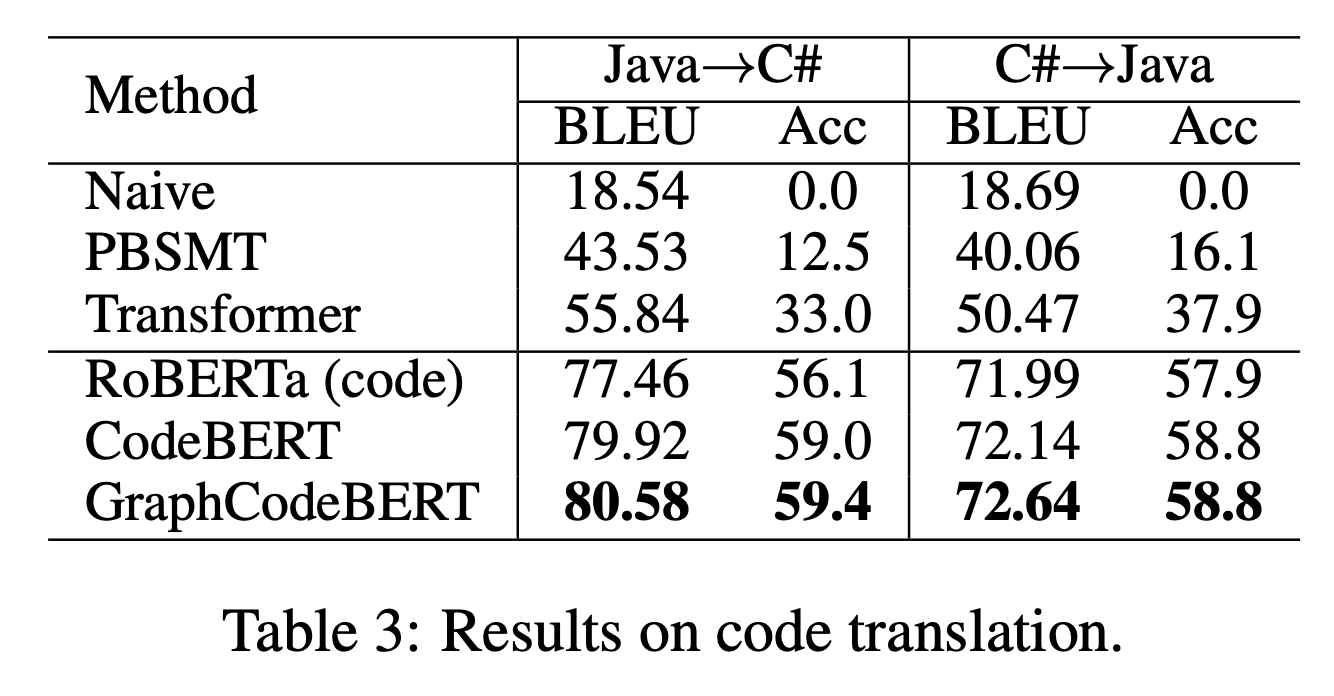
4つの下位タスクでの結果を表に示す。
- Natural Language Code Search
- Code Clone Detection
- Code Translation
- Code Refinement
いずれのタスクにおいてもCodeBERTを凌ぎ、SOTAを達成している。

筆者の感想:
個人的にはCodeBERT->GraphCodeBERTのパフォーマンスゲインがもっとあっても良いのかな?と思ったが、CodeBERTは事前学習にReplaced Token Detectionというよりサンプル効率の良いタスクを採用しているので、その違いかもしれない。
Discussion