Attentionと類似度は異なるという話

はじめに
「Transformerのattentionはトークン間の類似度をモデリングしている」という説明をよく聞くが、この表現は適切でないことを示す。
なお、このような説明がよくされる背景としては、Transformerのdot-product attentionは内積で計算され、コサイン類似度も正規化されたベクトルの内積で計算される点によるものと思われる。しかしながら両者は正規化の有無に違いがあり、ベクトル空間に埋め込んだ時の数学的性質はかなり異なるということを本稿では指摘する。
TL; DR
- Attention(dot-product attention)は類似度とは異なる数学的性質を持つ
- 類似度はトークン間の近接関係はモデリングできるが、それ以外の多様な関連をモデリングするには適さない。
- dot-product attentionはトークン間の近接関係を含むさまざまな関連をモデリングするのに適する。
前提知識
AttentionはKernel関数の一種である
Transformerのdot product attentionはKernel関数によって定式化できる。Kernel関数とは、2つの
なお、機械学習の文脈で数学的に扱いやすい性質を持つkernel関数として正定値(positive definite)という性質のものがよく用いられるが、ここでは分かりやすさを重視して非負の値を持つものとして定義した。
Kernelの具体的な構成方法
具体的なKernel関数の構成方法について示す。
距離に基づくKernel
このカテゴリのKernelはベクトル同士の距離が近いものほど大きな値をとるという性質を持つ。すなわち、ベクトルの類似度の一種と言える。
Gaussian Kernel
内積に基づくKernel
距離ではなく内積によってもKernelを構成できる。dot product Attentionは以下で定義されるExponential Kernelをコンテクスト内の全トークンで正規化して確率にしたものである。
Exponential Kernel
Dot-product Attentionと類似度の違いについて
異なるKernel関数のベクトル空間上での数学的な性質の違いについて議論する。
距離に基づくKernel(類似度)の場合
Fig1は2次元ベクトル空間においてGaussian Kernelの値の等高線を示したものである。これによると、関連性の高いベクトルのペアの埋め込みについて以下の性質を持つ(この性質はGaussian Kernelに限らず、ベクトルの距離に基づいて定義されるkernel全般に成り立つことに注意)。
- Kernelが最大値を取るのは2つの入力ベクトルが一致する場合で、その時に限る。
学習が進につれて関連性の高いトークンはベクトル空間内で1点に収束しようとする。従って、初期状態でさまざまな方向を向いていた関連トークンの埋め込みは学習の進行とともに多様性を失い、多様な関連の情報を空間内に埋め込む余地がなくなると考えられる。
この性質は時系列タスクにおけるトークン間の多様な特徴を捉えるには向いていないと言える。
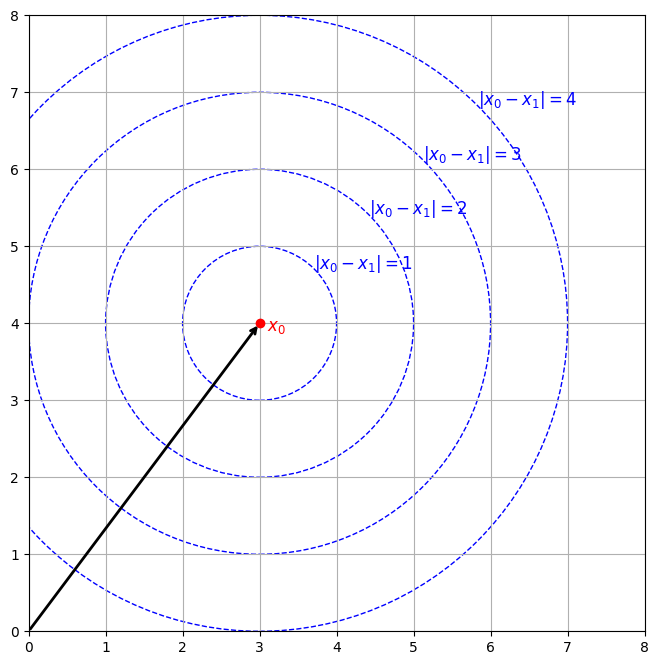
Fig.1 L2距離の等高線: L2距離が最小になる点は1点のみ
内積に基づくKernel(dot product attention)の場合
Fig2は2次元ベクトル空間におけるExponential Kernelの値の等高線を示したものである。これによると、
- Kernelの値に最大値や最小値はない
- 同じベクトル同士のペアがKernelの最大値を取る訳ではない(
k(x_0, x_0) < k(x_0, x_1) x_1
距離に基づくKernelの場合と異なり、学習が進んでも関連性の高いトークンのベクトルは
なお、cosine類似度のように正規化された内積の場合はL2距離に基づくKernelと同様な性質を示すので、こちらも時系列タスクのAttentionの候補としては向いていないと言える。
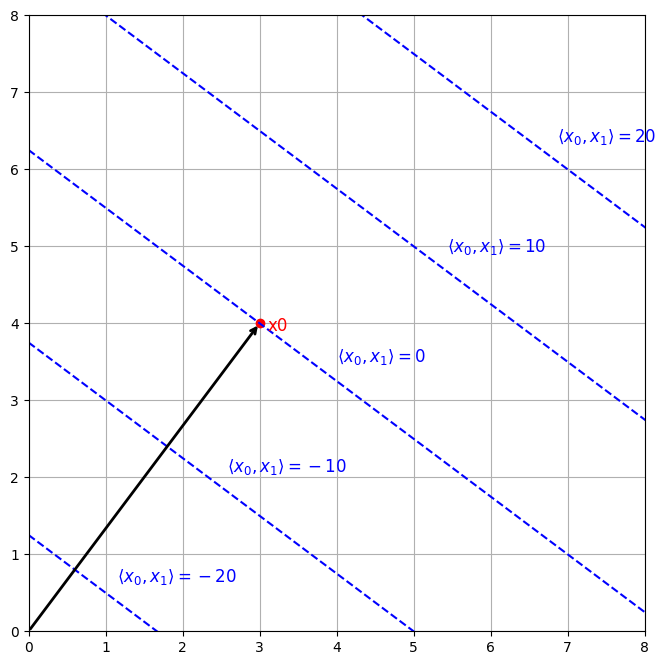
Fig.2 dot productの等高線: dot productが同じになる点は無数に存在する
関連研究
[1]はtransformerのdot-product attentionがカーネル関数によって定式化できることを示した先駆的な研究。
後続の研究として、[2, 3]ではSoftmax(Exponential Kernel)とは異なるkernelによってTransformer blockの代替を提案した。これらの研究では正定値Kernelを仮定することで、2変数入力のKernel関数を1変数関数の積に分解できるという定理を用いてQKV積の計算順序を(QK)VからQ(KV)に変換することでコンテキスト長が長い場合にメモリ消費と計算量を減らせるという実用的なメリットを提示した。具体的にはコンテキスト長を
参考文献
- Transformer Dissection: A Unified Understanding of Transformer's Attention via the Lens of Kernel
- cosFormer: Rethinking Softmax in Attention
- DiJiang: Efficient Large Language Models through Compact Kernelization
- Skyformer: Remodel Self-Attention with Gaussian Kernel and Nyström Method
- Query-Key Normalization for Transformers
Discussion
拝見しました! 素敵な記事でした!
「内積は類似度である」っていう考え方は、私も結構推してきた自覚があるのですが、こういうカウンターが出てくるのは極めて嬉しいです!
少なくとも私がこの説明を使うときは、「ホントは長さの議論ないがしろにしてるよな、、、」と若干の後ろめたさを抱いていたので、そこを堂々と突いていただいて、流石だなと感じています!
記事公開後に発見されたという論文は、読んだことがなかったので、私も勉強してみようと思います。
それ以外の観点があるとすれば、高次元ベクトルの球面集中現象も面白いと思います。
次元が高いベクトルはだいたい長さが揃ってしまう減少があるので、(その仮定のもとでは)内積と距離はかなり同じものになると思います。
また、Transformer の場合、Layer Normalization があるので、これもやはり、長さをかなり揃える作用があると思います。(もっとも、Multi-Head Attention では、Dot-Product Attention に突っ込む前に巨大な行列で変換しているので、特異値分布のばらつきの分くらいは長さも散っており、あまり長さは揃っていないような気もしますが。)
Aiciaさん、コメントありがとうございます。
指摘されている通り、TransformerはQ, Kを計算する前に入力ベクトルに線形変換を施すので入力前に正規化されていても線形変換によって再び長さにばらつきが生じると思います。
参考文献によると、実用的な観点からは「TransformerではQ, Kを正規化してもしなくても対して変わらない」という結果だと思いますが、この記事で議論したようなベクトル空間上でのkernelの値の空間上での分布の差異がなぜ性能に反映されないのか?というのが個人的に腑に落ちてない点です。
P.S.
以前YouTubeの動画をいくつか参考にさせていただいていました。学部生時代に思い悩まれていた話が印象に残ってます。
そのあたりは私もよく分かっていないです、、、。
数式の設計思想は追いかけるのですが、
実際どう動いているか、どう変えても大丈夫かは、かなり実験科学だと思うので、なかなか食指が伸びなくて、、、。
動画もご視聴いただきありがとうございます!
あの動画見たのですね、、、(笑)
結構ちゃんと黒歴史を包み隠さず話したら、結構見られてびっくりしています(笑)