論文要約: DAIL - 顔認識タスクにおける複数データセットを使った学習手法
はじめに
顔認識において複数のデータセットを結合して豊富なデータで学習を行う手法を提案した論文。
異なるデータセットを結合する時の問題として、ID重複の問題がある。これは例えば有名な顔認識のデータセットはセレブの顔を扱ったものが多いため、異なるデータセットに同じ人物の顔が一定の割合で現れる。これらの人物を別々の人物として扱うと正しいembeddingを学習できず、性能が低下する。
一方で手動でデータクリーニングするのはデータセットの規模が大きくなるにつれてコストが甚大になる。そこで本論文では、1) ID重複による同一人物のembeddingを異なるembeddingとして学習することを緩和し、2) さらにデータセットによらない普遍なembeddingを学習する手法を提案する。
1) Dataset-aware loss
まず、IDについては全てのdatasetについて固有のにとる(従って同じ人物が異なるdatasetに存在する場合は異なるIDとなる)。softmax損失を計算する際に「同じデータセット内のサンプルのみを集約する」。
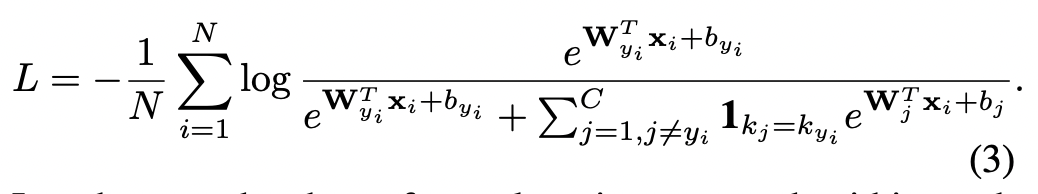
このようにすることで、同じ人物が異なるデータセットに現れる場合であっても、負例としてカウントされ、誤った学習がされることがなくなる。なお、この損失計算はsoftmaxベースの他の損失関数にも拡張できる(例としてArcFace lossの場合を4式に示す)。
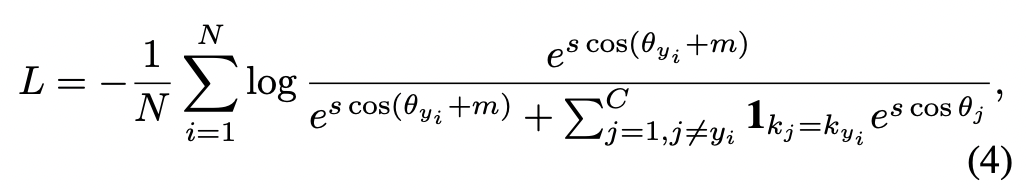
2) GRL(gradient reversal layers)
dataset aware lossのみでも単純な合成に比べるとパフォーマンスが高いが、さらに本論文ではGRL(gradient reversal layers)という手法を使ってdomain adaptationを試みる。
まず、前提としてアーキテクチャについて述べる。図に示したような3つのコンポーネントからなる。
- embedding network
- ID classification network
- Dataset classification network

このアーキテクチャを使ってデータセットによらない普遍な表現を学習するために、(7-8)式に示す敵対的学習を行う。概念的な説明としては、embedding networkはdatasetによらない普遍的な表現であることが要請されるためdataset classifierを欺くように学習する。従って(7)式においてL_dはマイナスの符号がつく。

ただし初期の重みからこのスキームを使っても学習が安定しないため、2段階のアプローチを取る。すなわち、1st stageにおいてembedding layer, ID/dataset classification layerの各コンポーネントを(9-10)式によって個別に学習し、2nd-stageにおいて(7-8)式で示した敵対的学習でfinetuneする。
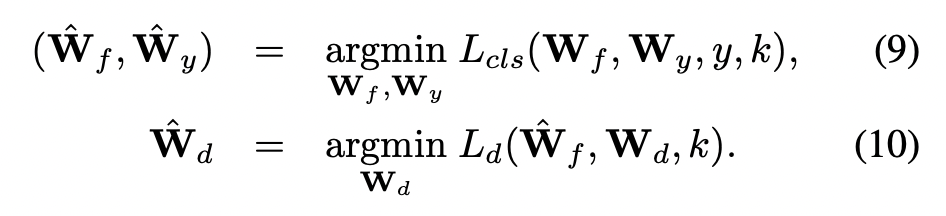
評価
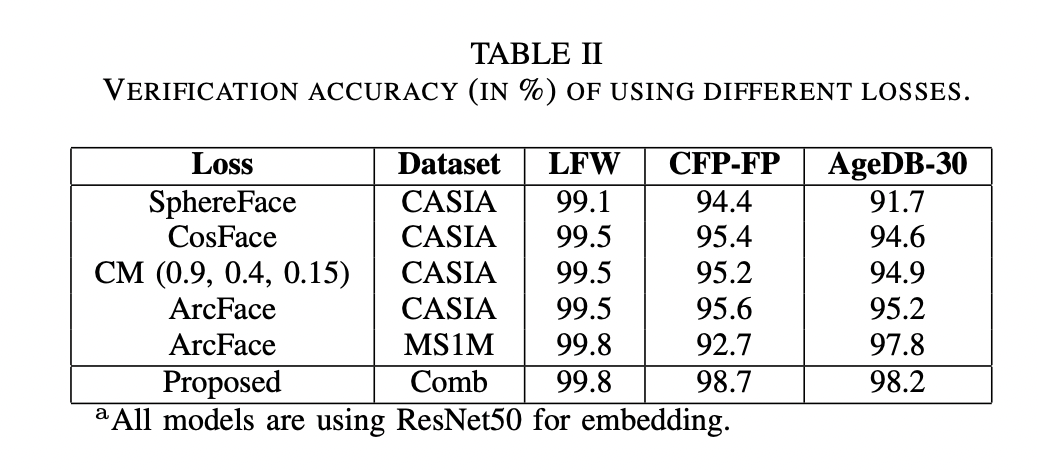
提案手法はLFW, CFP-FP, AgeDB-30データセットを使ったベンチマークにおいて、従来手法よりも優れたパフォーマンスを発揮した。特に、顔のアングルの多様性が大きいCFP-FPと年齢の多様性の大きいAgeDB-30においてパフォーマンスゲインが大きい。
アブレーションの結果では、dataset-aware loss, GRLのそれぞれでパフォーマンスゲインがあることがわかる。dataset-aware lossのゲインが特に大きい。
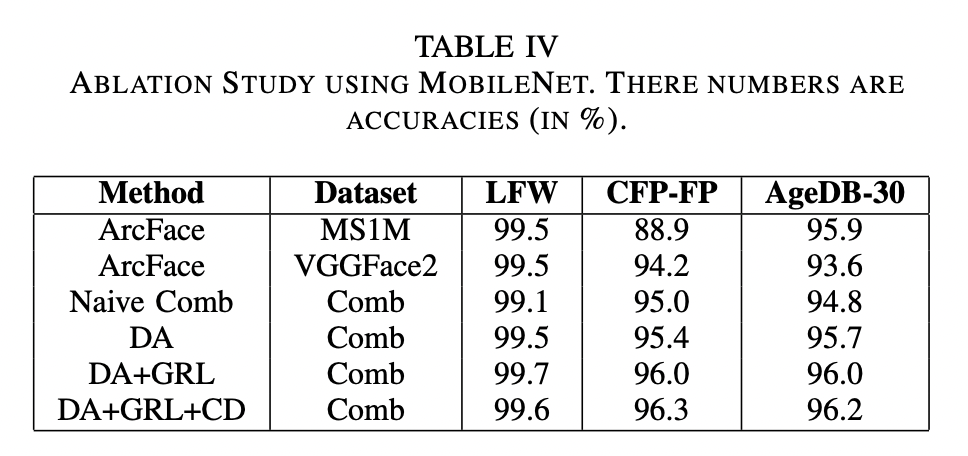
また、dataset-aware lossを拡張し、softmaxを計算する際に、異なるデータセットのサンプルをわずかに混入させる(crossing dropout)ことによって性能向上することがわかった。これは、わずかなサンプル(p=0.0001)ではID重複する確率が小さいため、性能低下よりもゲインが上回るという説明ができる。
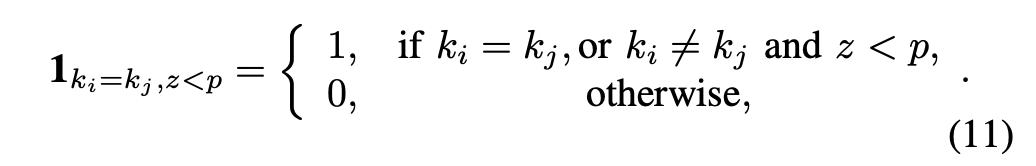
Discussion