RNNが学習できるコンテクスト長についての考察
概要
本稿ではRNNが学習できるコンテクスト長について考察する。
「LSTMやGRUは素のRNNと比べて長期的なコンテクストを学習しやすい」と一般的に言われているが、具体的にどのような構造によってそのような性質を持つのか、また、どの程度「長期的な」コンテクストを学習できるのかについて数学的形式に基づいた洞察を得ることを目的とする。
本稿の成果は以下である。
- 各種RNNのアーキテクチャの特徴と各構成要素の機能について直感的な解釈を示した
- LSTMやGRUが素のRNNに比べて「長期的なコンテクストを学習しやすい」とする根拠について定義式に基づき議論した
RNNの各種アーキテクチャについて
まず、各種RNNのアーキテクチャごとの違いを整理する。
数学的表現および表記については[1]を参照した。
表記:
-
t -
x_t -
o_t -
h_t -
c_t
bare-RNN
本稿ではゲート構造を持たないRNNを後続のアーキテクチャと区別するためにbare-RNNと呼称する。
特徴:
-
hidden state (
h_i - 現在のhidden stateは現在の系列と直前のhidden stateに応じて決まる。
- 一般的に「長期にわたるコンテクストは学習できない」とされている。
数学的表現:
ダイヤグラム:
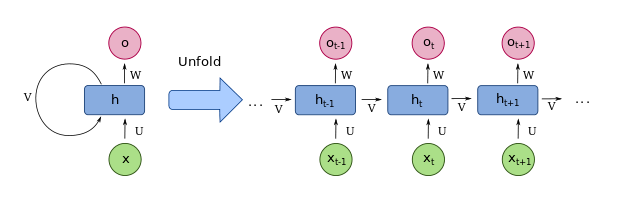
Attribution: fdeloche, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons
LSTM
特徴:
bare-RNNの長期的なコンテクストを学習できない問題に対処するために提案された。
伝搬させる信号そのものと制御信号(gate)を分離したことで過去の信号の影響の減衰に関してbare-RNNよりも解釈性が高いアーキテクチャになっている。
過去の系列を保持する変数として hidden state (
また、以下の3つのgateで過去の系列と現在の系列の伝搬量をコントロールする:
-
forget gate (
f_t -
input gate (
i_t -
output gate (
o_t
数学的表現:
ダイヤグラム:
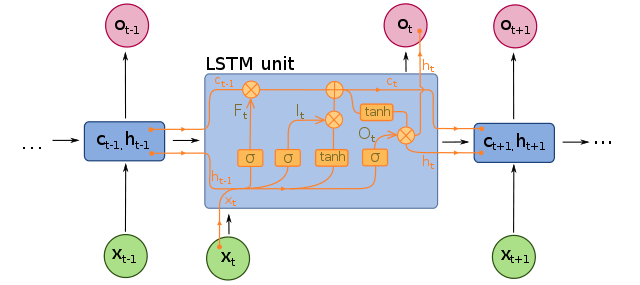
Attribution: fdeloche, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons
GRU
特徴:
状態変数とゲートの数を減らしてLSTMを簡素化したもの。
以下の2つのgateでコンテクストと現系列それぞれの伝搬量をコントロールする:
-
reset gate (
r_t -
update gate (
u_t
数学的表現:
ダイヤグラム:

Attribution: fdeloche, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons
RNNが学習できるコンテクスト長について
RNNが学習できるコンテクスト長について議論する。
最初に概念的・直感的な考察を示し、最後に定義式に基づいたより厳密な議論をする。
基本となるアイデア
以降では「RNNが学習できるコンテクスト長」について議論を進めるが、前提として、「back propagationの計算において目的関数の勾配がどの程度初期の時系列ステップに対応するブロックに伝搬するか」を考える。すなわち、対象とする系列を
これと似た考え方に、「ネットワークがどの程度の長さのコンテクスト情報を保持するか」という問題があるが、ここではこの問題については扱わない。
なぜbaer-RNNは「長期的なコンテクストを学習できない」か?
bare-RNNが長期のコンテクストを学習できない原因は端的にいうと「勾配消失・爆発しやすいため前方のステップまで勾配が伝搬しないため」であるが、LSTMやGRUも勾配はステップを遡るともに減少するので両者の違いを議論するには数式に基づく議論が必要である。
直感的にはbare-RNNにおいては「制御信号と信号そのものが分離されていない」ことが長期的なコンテクストを学習できないことについての間接的な原因であり、具体的にはback propagation で時系列を遡るたびにtanhのパスを繰り返し通ることで同じ係数行列の線形変換が勾配に冪乗されて適用され、勾配爆発・消失のいずれかが生じやすくなることが原因と考えられる。
LSTMやGRUが「長期的なコンテクストを学習できる」のはなぜか?またどの程度「長期的」か?
これに対し、後継のアーキテクチャであるLSTMやGRUは制御信号(ゲート)と信号そのものが分離されている。ゲートは「信号をどの程度後続のステップに伝搬させるか」をコントロールする。具体的には信号そのものに
勾配の減衰に関するより厳密な議論
以上の議論を数式に基づきより厳密に議論する。
RNNにおける勾配の減衰
bare-RNNにおけるhidden stateについての勾配の計算式は以下のようになる。
前方のステップに遡るたびに
注1:
LSTMにおける勾配の減衰
LSTMにおけるcell stateについての勾配の計算式は以下のようになる。
前方のステップに遡るたびに乗算されるのは
bare-RNNとの違いは2つあり、まず、乗算される項が
Reference
- [1] A Brief Introduction to Recurrent Neural Networks
- [2] Bengio, Y., Simard, P., and Frasconi, P. (1994). Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2), 157–166.
- [3] Pascanu, P., Mikolov, T., and Bengio, Y. (2013). On the difficulty of training Recurrent Neural Networks
- [4] Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780
付録
付録A: 勾配消失・爆発問題に関する研究論文について
勾配消失・爆発の問題についての既存研究について触れておく。勾配消失・爆発の問題は歴史が古く、1994年にはすでにBengioらによって提起されている[2]。比較的最近(2013年)に出版された論文には[3]があり、本稿で扱ったような議論(重み行列の冪乗のノルムが勾配伝搬とともに指数関数的に減少・増大する)をよりフォーマルに論じている。また、この論文では逆伝搬される勾配のノルムの増加と減少に対してペナルティを加える正則化項
この論文でトークン列の分類タスクにおいて、長さ50〜200の時系列に対して提案手法によりSGDによる学習の成功確率が向上することを示した。
一方で、LSTMの論文[4]では1,000を超える系列長の人工データ対して模擬的なタスクを十分な性能で行えることを実験により示している。
Discussion