🦢
論文要約: Swin Transformer - 画像タスクで汎用的に使えるTransformerモデル


論文
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
概要
オブジェクト検出やセグメンテーションといった密な視覚タスクにおいて、従来のクラス分類に特化したモデル(ViT[1], DeiT[2])は解像度が十分でないことや、計算量が画像サイズの2乗に比例することが課題だった。本論文ではこれらの課題をクリアし、あらゆる画像タスクで汎用的なバックボーンとして利用できるモデルを提案する。
提案手法の特徴
- 階層的な特徴抽出(FPN[3], Unet[4]のような構造)
- self attentionの範囲を画像全体でなく、local window内のパッチに限定することで計算量を削減
- sliding window でなく shifted window という手法を採用することで計算量を削減
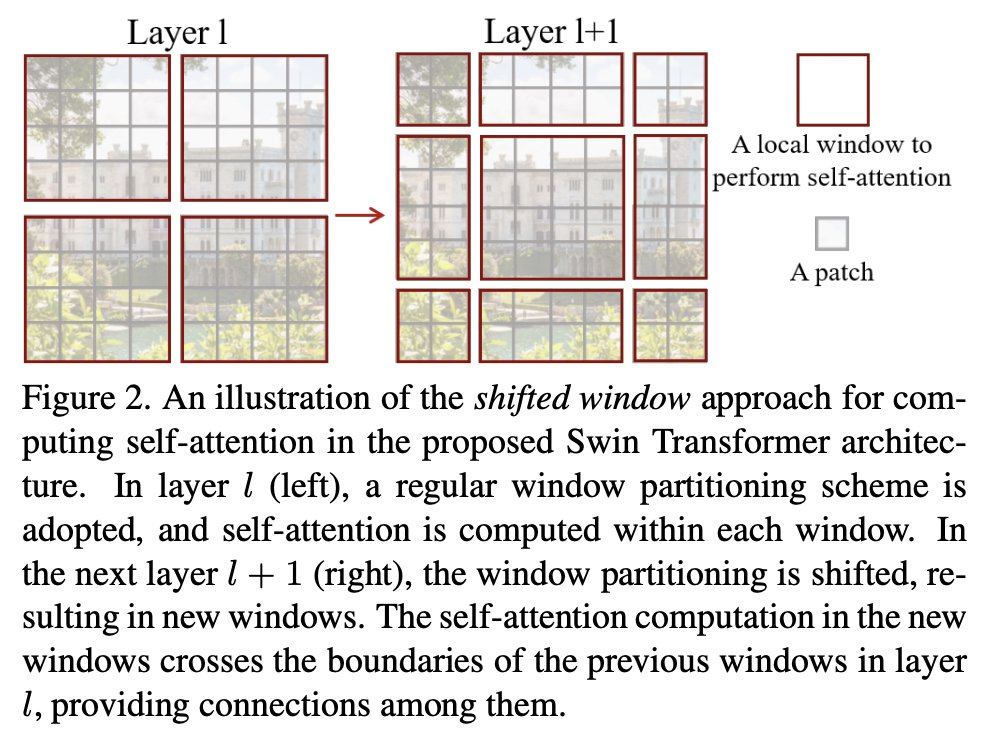
Shifted Window
widowを固定にすると同じwindow内のパッチ同士の相関は抽出できるが、windowをまたいだパッチの相関は抽出できない。そこで、本論文では偶数レイヤーでwindowの範囲を半分ずらす方針をとる。
こうすることでwindowの境界をまたがるパッチの相関を特徴として抽出できる。
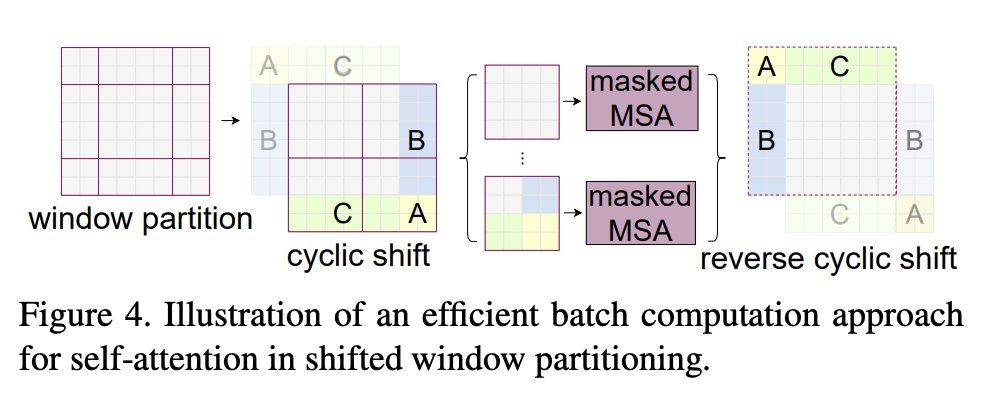
shifted window における計算量的な工夫
windowをずらしたレイヤーではwindowの数が増えてしまう。本論文では右上に位置するパッチを巡回してずらし、左下のパッチと結合することでwindowの数を一定に保っている。
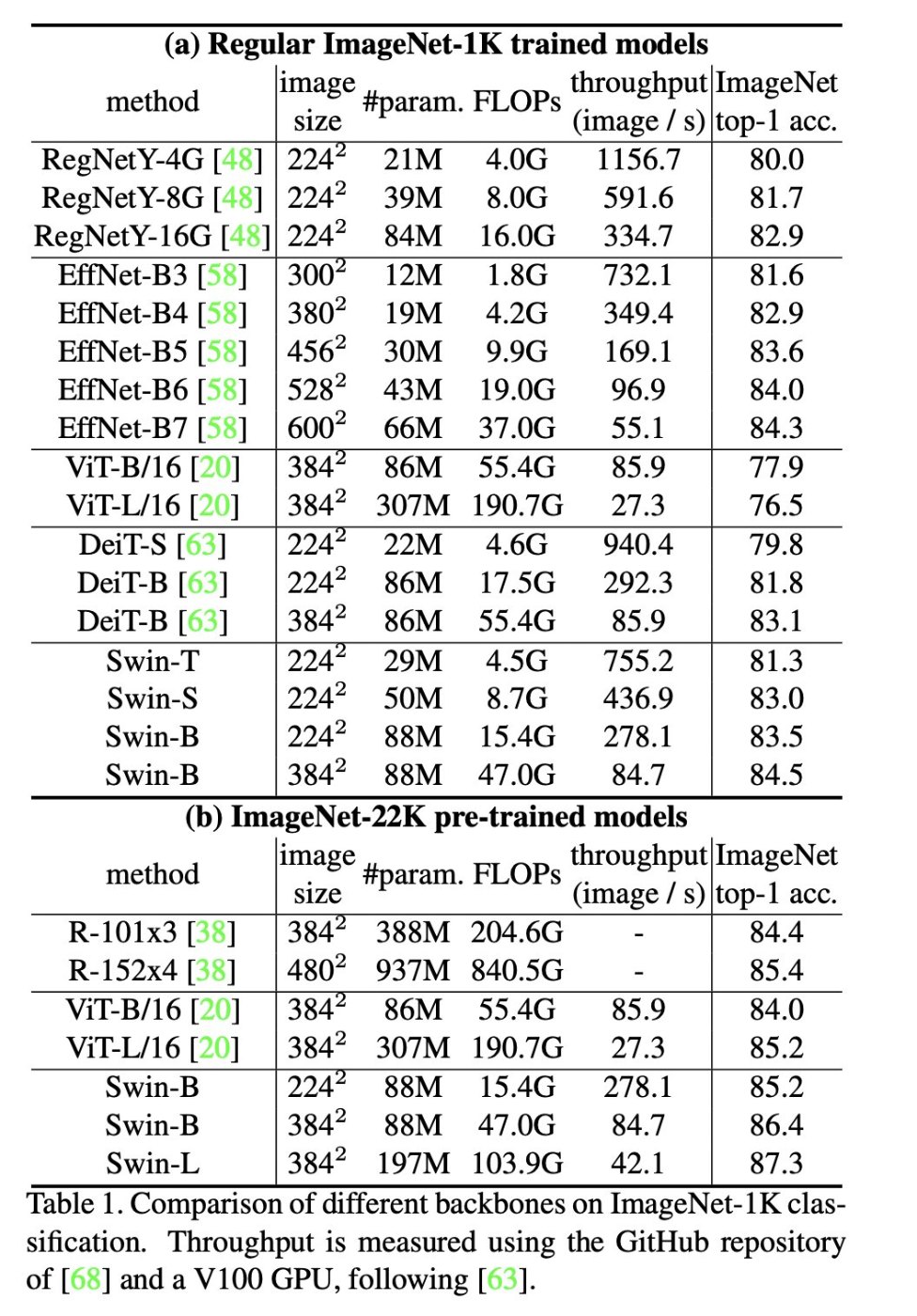
既存モデルとの比較
- 汎用的なモデルを意図したものだが、画像分類においても既存のTransformer (ViT/DeiT)を上回る精度を実現。また推論速度が大幅に改善。
- CNNとの比較において、imagenet-1Kで事前学習したモデルは性能はあまり変わらないが、imagenet-22Kで事前学習したモデルでは明確な差が出ている。
Discussion
ViTを例にとると、16x16のパッチからは正確な位置情報の特定ができないのでobject detectionやinstance segmentationには向かない、ということ。