[論文要約] ST-SED: 弱ラベル付きデータを用いたクエリベース学習によるZero-shot音源分離
論文
Zero-shot Audio Source Separation through Query-based Learning
from Weakly-labeled Data
概要
これまで提案された音源分離手法は以下のいずれかである。
- 個々の音源のクラスに対して個別にモデルの学習が必要なもの
- 1つのモデルで複数のクラスの音源を学習できるが、未知の音源には対応しないもの
本論文で提案するのは1つのモデルで未知の音源を含む普遍的な音源の分離を可能とするモデルである。
提案手法の特徴
- 弱ラベル付きデータセット(AudioSet)を使った音声イベント検出器[1]を提案
- 1つのモデルで複数のクラスの音源を分離する
- 学習時に使用されていない未知の音源にも対応
- 未知の音源に対しては新たにモデルのパラメータの学習を必要としない[2]
提案モデルのアーキテクチャ
以下の3つのモジュールからなる(図1)。
- Sound Event Detector: 弱ラベル付き音源から音声イベントを検出する(音源の局所化)
- Latent Source Processor: 1と同じSED[1:1]に局所化された音源を入力し、その潜在ベクトルを抽出する
- Audio Source Separator: 2で抽出した潜在ベクトル及び混合音源から元の音源を復元する
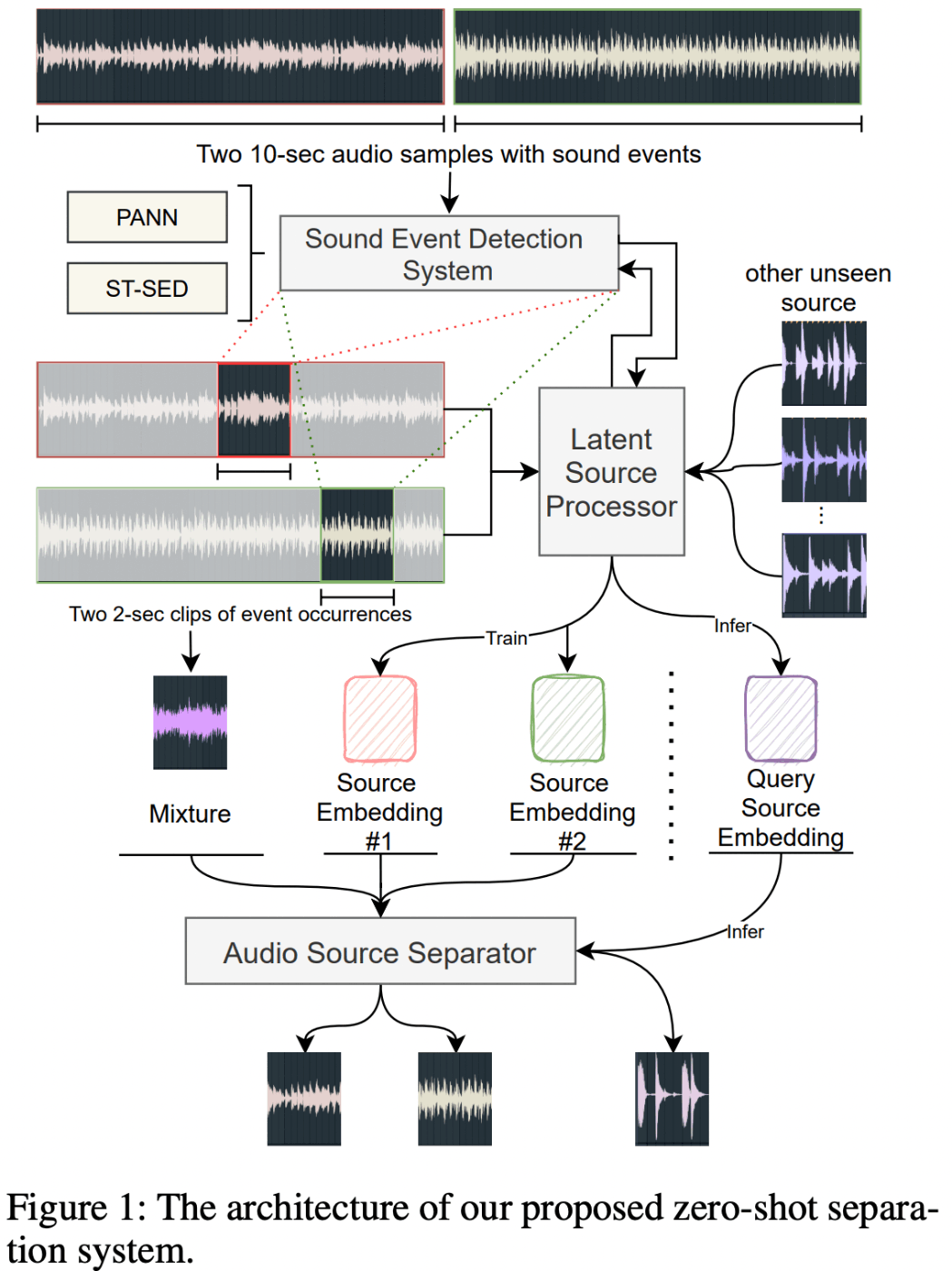
図1: 提案モデルのアーキテクチャ
音声イベント検出器
このモジュールの入出力は以下の通り:
- 入力
- 生の10秒クリップの音源のmel-spectrogram:
x_i - 抽出したい音源のクラス:
c
- 生の10秒クリップの音源のmel-spectrogram:
- 出力: 局所化された音源:
s_i
音源分離モデルの学習には、なるべく余計な音を含まない純粋な音源のデータを使用することが望ましい。一方で、AudioSetのデータは複数の音声イベントを含んだ10秒間のクリップからなる。唯一参照できるラベルは、そのサンプルに含まれる音声イベントの種類のみであり、正確な開始時間と終了時間を知ることはできない。
そこで、本論文ではまず音声イベント検出器を使って、対象とするクラスの音源をサンプル内で時間的に局所化することを考える。局所化された音源は余計な音がより少ないため、後段の音声分離器の学習がより効率的に行えるはずである。
音声イベント検出器として、本論文ではSwin-Transformerベースの検出器を提案する(図2)。
なお、性能比較のために、CNN(PANN)ベースの検出器も作成した(図3)。

図2: Swin-Transformerベースの音声イベント検出器
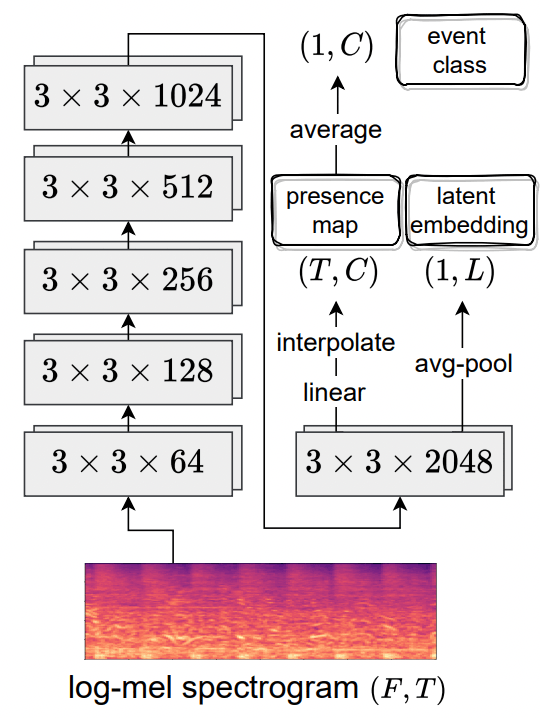
図3: PANNベースの音声イベント検出器
潜在ベクトル抽出器
このモジュールの入出力は以下の通り:
- 入力: 局所化された音源データ
s_i - 出力: 対応する潜在ベクトル
z_i
出力は、音声イベント検出器のバックボーンの重みをPoolingすることで作成する。
音源分離器
このモジュールの入出力は以下の通り:
- 入力:
- 混合音源のmel-spectrogram
- 抽出したいクラスの潜在ベクトル(クエリ)
- 出力: 分離された音源のmel-spectrogram
1は前段のモジュールで局所化した音源のサンプル2つを混合することで人工的に作成する。
アーキテクチャは図4に示すようなUnetに似た構造を持つ。
各convolutionレイヤの入力にembeddingを入力することで、embeddingと分離後の音源の関係性を学習できると著者は主張している。
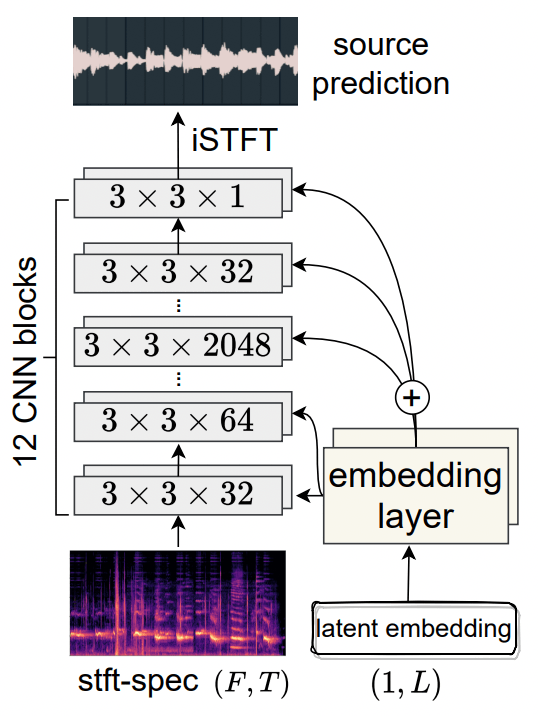
図4: 音源分離器のアーキテクチャ
推論時
学習時に含まれない混合音源を分離する場合、分離したい音源の潜在ベクトルはあらかじめ与えられていない。したがって、本提案手法では分離したいクラスの音源のサンプルがいくつか与えられていることを制約として課し[3]、それらの潜在ベクトルのサンプル平均をクエリとする。
実験結果
- 音声イベント検出器について
- Swin-Transformerベースの検出器の精度がCNN(PANN)ベースの検出器の精度を上回った。
- 本提案モデルはASTと異なり、ImageNetによる事前学習を必要としない(フルスクラッチ学習の場合と比較して精度がほとんど変わらない)。
- 音声分離モジュールについて
- CNN(PANN)ベースのembeddingを使うよりもSwin-Transformerベースのembeddingを使うほうが精度が高い -> 後者のほうがより音源の特徴を捉えている
- MUSDB18 test setに対して既存のSOTAと比較すると、others以外のクラスではまずまずの比較可能な性能がでている[4]
所感
- 「分離したいクラスに対応する潜在ベクトルと混合音源を入力することで、分離後の音源が得られる」というのが本手法の骨子である。1) 音源から潜在ベクトルへのマッピング及び 2) 潜在ベクトルと混合音源から分離音源へのマッピングについて、AudioSetという十分大きなデータで学習することによって「普遍的な表現」を獲得している。
- 潜在ベクトルの計算は単純にクラスタ中心を計算しているだけなので、改善の余地がありそう。
- 音声イベント検出器としてSwin-Transformerベースの手法を提案したのは他ではやってないと思うので、こちらについても(別の論文で良いが)主張しても良さそうに思った。
-
ただし、学習データに含まれていないクラスの音源に対しては少なくともそのクラスに属するいくつかの音源のサンプルを必要とする。 ↩︎
-
未知データについては追加のパラメータの学習は不要であるが、この制約があることから、私はzero-shot学習と呼ぶには抵抗がある。なぜなら、学習データに含まれないクラスのサンプルに対しては、潜在ベクトルを計算するための音源サンプルを必要とするからである。 ↩︎
-
otherクラスで精度が悪い原因としては、otherの潜在ベクトルが単純なサンプル平均とは乖離している可能性を指摘している。さまざまな音源を含むこのクラスは、当然ながら潜在空間上で複雑な分布をしていると考えられ、単純に平均をとるだけではこのクラスの特徴を十分に捉えられていない、というのが著者の主張であろう。「その他」クラスの扱いについては議論の余地があると考える。 ↩︎
Discussion