Paper Review - WaveNet: A Generative Model for Raw Audio
概要
音声データの条件付き生成モデルWaveNet[1]について解説する。
WaveNetは画像ドメインにおける生成モデル(PixelRNN[2])を音声信号に適用することを目指したもの。画像データと比較した音声信号の特徴は系列長が非常に長いことで、PixelRNNが生成するデータは64x64=4,096と低解像度であるが、音声データは16kHzでサンプリングした場合、1秒あたり16,000にもなる。このため、長大な系列長から特徴を拾うために提案手法ではdilated convolutionによりCNNの受容野を広げるアプローチをとる。
提案手法で用いられている要素技術について
Casual convolution
提案手法は生成モデルであるから、推論時に未来の時系列を参照することができない。従って、CNNの基本ブロックとして過去の時系列に基づいてのみ畳み込みを行うcausal convolution を採用している。

一方で、オフラインの回帰タスクや分類タスクの場合は未来の系列も参照できるのでこの制約は取り払うことができる。
なお、実際にcausal convolutionを機械学習フレームワークで実現するには通常のconvolutionの直前に以下のようなleft-paddingを挿入することで実現できる。
Dilated convolution
CNNの受容野を拡大する手法としてはpoolingやstrideを用いる方法があるが、これらは同時に系列の解像度を下げるために、入力信号と同じ解像度の時系列を生成する目的にはあまり適さない。このため提案手法ではdilated convolutionを用いて解像度を落とさずに受容野を広げる手法をとっている。また、比較的浅いネットワークで受容野を広げるためにdilationの大きさはlayerの深さに対して指数関数的に大きくなるようにとる。

一方で、回帰タスクや分類タスクの場合は時系列方向の解像度を下げても問題ないので、strideやpoolingを用いる方が学習、推論の効率が良いかもしれない。
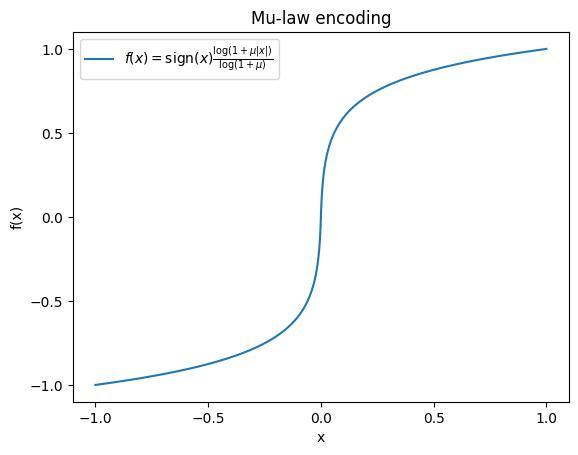
量子化による出力次元の削減
提案手法は過去の連続するt個のトークンを入力として、次の1フレームの信号
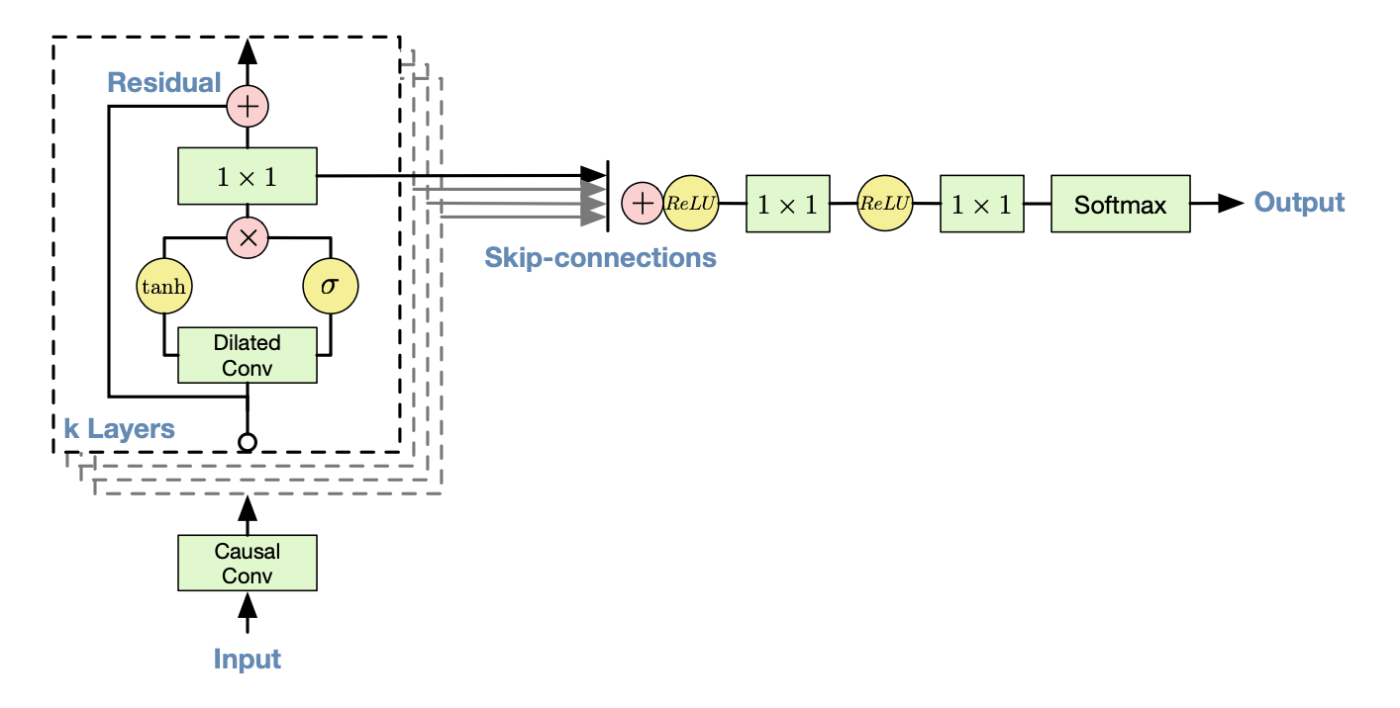
Gated Activation
提案手法のアーキテクチャを以下の図に示す。各レイヤではGRUやLSTMに似たtanhとsigmoidの積によるゲート構造を導入している。
コンテクストの与え方
提案手法はText-To-Speechのように、何らかのコンテクスト情報をもとにして音声信号を生成するモデルである。
以下の2通りの与え方を提供している。
Global context
話者のembeddingなど、系列を通して一貫したコンテクストを入力系列に加算することで与える。

Local context
テキストや音素など、時系列をコンテクストとして与えることもできる。
時間方向の解像度は生成するデータのそれよりも粗い場合はtransposed convolutionによって解像度を音声信号の時系列と一致させてから入力する。

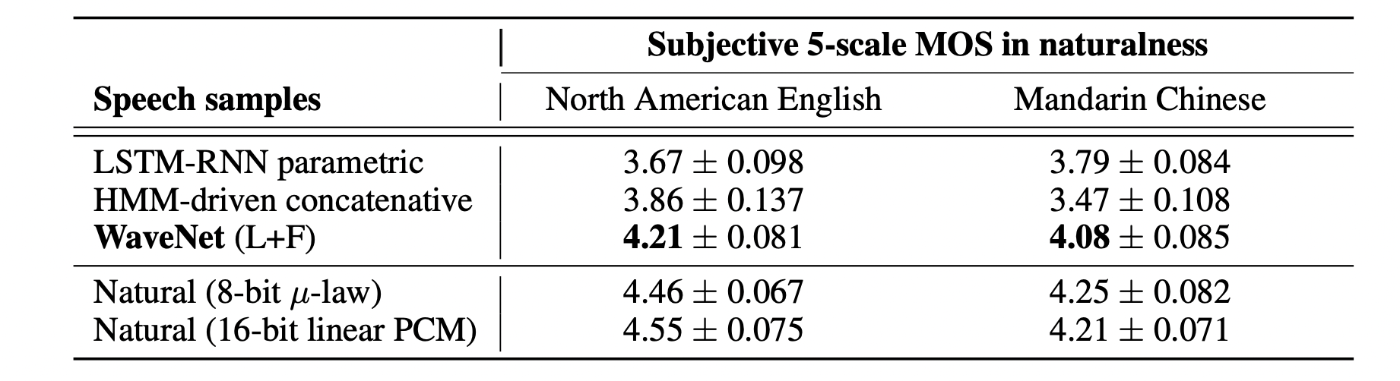
評価方法と結果
北米英語および中国語(北京語)のスピーチデータセットに対して人間の被験者に対してアンケート調査を実施し、人間のスピーチ音声として自然に聞こえる度合いを5段階評価で採点させた。評価結果は英語、中国語ともに、既存の手法を上回った。
Reference
- [1] WaveNet: A Generative Model for Raw Audio
- [2] Conditional Image Generation with PixelCNN Decoders
- [3] https://en.wikipedia.org/wiki/Μ-law_algorithm
Discussion