[論文要約] DeiT: 知識蒸留による効率的なViTの学習手法
論文
Training data-efficient image transformers & distillation through attention
概要
ViTの学習には300M枚の画像からなる膨大なデータセットが必要だった。これに対し、提案手法はViTと同じアーキテクチャを使い、学習方法の改善と新たに提案した知識蒸留手法を適用することで、imagenetのみを使って最新のConvNetと同等以上の性能を達成した。
提案手法の特徴
- Transformerに特化した注意ベースの知識蒸留[1]手法を新たに提案
- 上記知識蒸留手法と重いデータ拡張などによる一連の学習手法の改善により、一般的に使われているimagenetのみによって最新のConvNetの同等以上の精度を達成(図1)

図1: 最新モデルとの精度-スループットの比較
注意による知識蒸留
- Soft distillation: 教師ラベルの分布と生徒モデルの予測分布のKLダイバージェンスをロス関数に加える
- Hard-label distillation: 教師ラベル、正解ラベルそれぞれに対して生徒モデルの予測分布とのCross Entropy誤差を計算し、平均をとる
- Distillation token: class tokenと同等のdistillation tokenをpatch tokenとともにTransformerに入力する。distillation tokenに由来するTransformerの出力と教師ラベルから計算したCross Entropy誤差を、class tokenから計算したモデルの予測結果と正解ラベルから計算した通常のCross Entropy誤差に加える(図2)。
2について、実験結果によると、Hard-labelはSoft-labelよりも明確に精度が良かった。
このことについて、論文では「例えば画像の隅に小さく猫が写っていたとして、cropによるデータ拡張で猫の部分が失われた場合は、拡張後のデータには別のラベルが付与されるのが合理的である」と説明されている。すなわち、この場合は正解ラベルをそのまま正解として用いるよりも、教師ラベルを正解として用いる方が生徒のバイアスを小さくできることが期待できるのである。
3について、Distillation tokenはclass tokenと同じく学習可能なパラメータである。
実験によると、初期値を同じにしてもDistillation tokenとClass tokenはそれぞれ全く異なる重みに収束したとのことである(cosine類似度が0.06)。一方で、これらのトークンを元にして予測された2つの予測結果は似通った重みになったという(cosine類似度0.93)。
この事実は、これらのトークンがそれぞれ独立した方法によってラベルの予測をしていることを間接的に示唆している。
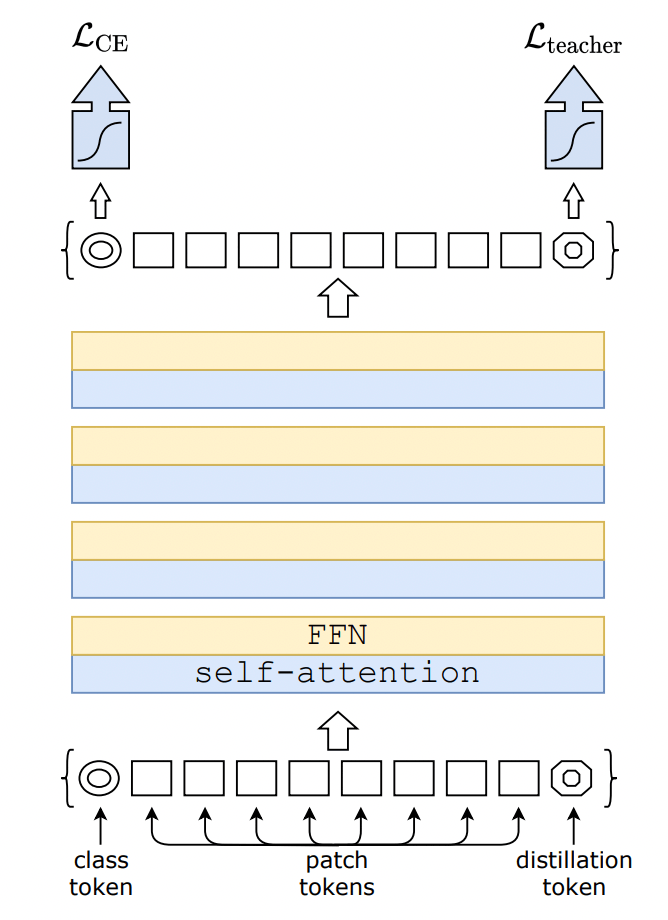
図2: 本論文で提案する知識蒸留手法
特筆すべき実験結果
- 教師モデルには、TransformerベースのモデルよりもConvNetベースのモデルを使った方が精度がよい
- Distillation tokenとClass tokenを両方使う方が、片方だけ使う、あるいは両方とも使わないケースよりも精度がよい
- Hard-labelによる distillationの方がsoft distilattionよりも精度が良い。提案手法のdistillationはそれよりさらに精度が良い
- 提案した知識蒸留手法と重いデータ拡張の恩恵により、epoch数を300->1000に増やしても精度改善の恩恵が得られる(図3)
教師モデルにConvNetを使った方が生徒モデルの精度がよかった点については、著者らは「ConvNetが持つ帰納的バイアスの恩恵によるものだろう」と推測している。一方で「これについて形式的な検証をすることは難しい」とも言っている。
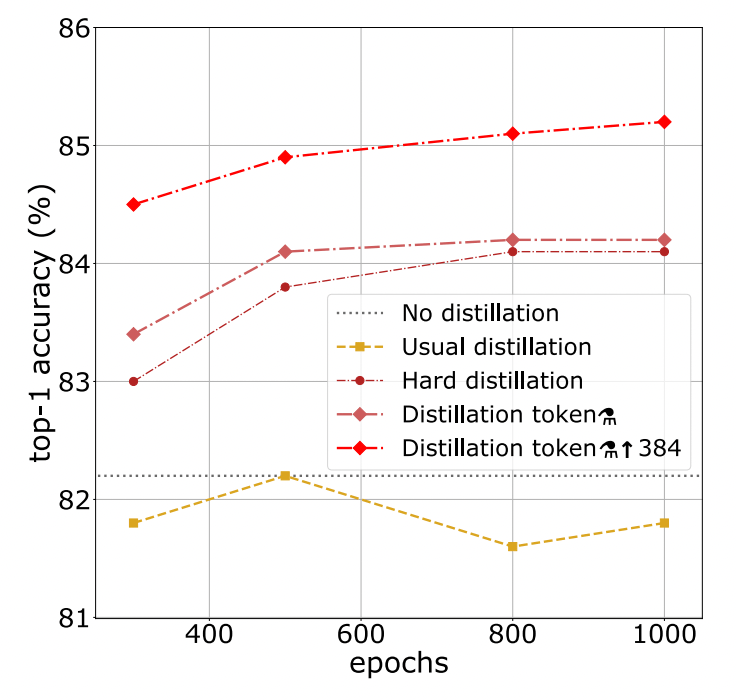
図3: 知識蒸留手法ごとの学習過程の比較
所感
- 教師モデルとしてConvNetを使う方がTransformerを使うよりも精度が高いのは興味深い。教師と生徒でアーキテクチャを変えることでモデルのアンサンブルのような効果が期待できるのだろうか?
- DeiTとViTは学習方法とDistillation tokenの部分が異なるのみで、アーキテクチャは同一である、というのは知らなかった
-
nowledge distillation ↩︎
Discussion