[論文要約] Deep Adversarial Decomposition: 敵対的深層学習による混合画像分離の統一的手法


論文
Deep Adversarial Decomposition: A Unified Framework for Separating Superimposed Images
ソースコード: https://github.com/jiupinjia/Deep-adversarial-decomposition
概要
敵対的学習による汎用的な混合画像の分離手法。これまでは人間がa prioriに与えた制約を使った手法が提案されてきたが、本論文では画像を分離するGeneratorと、画像が分離されたものかを判定するCriticモジュールによる敵対的学習をする。
本手法の応用として、1) 雨の除去、2) 反射除去、3) 影の除去といったタスクにも利用できる。混合画像分離、及び上記の応用タスク全てについてSOTAを上回る性能を示した。

図: 提案手法の適用例
提案手法の特長
- 分離前後の画像についての制約を人間が与える必要がない
事前知識が与えられていない場合、混合画像を分離する方法は無数に存在する。したがって、本タスクを扱うに当たって何らかの制約を与えるか、あるいはデータから制約を学習する必要がある。これまでは人間がa prioriに与えた制約を使った手法が提案されてきたが、提案手法では敵対的ネットワークを使って背景にある制約をネットワークが自動的に学習できることが特長である。
提案手法の概要
以下の3つのコンポーネントからなる(図1)。
- Generator(
G - Critic(
D_c - Discriminator(
D_1 D_2
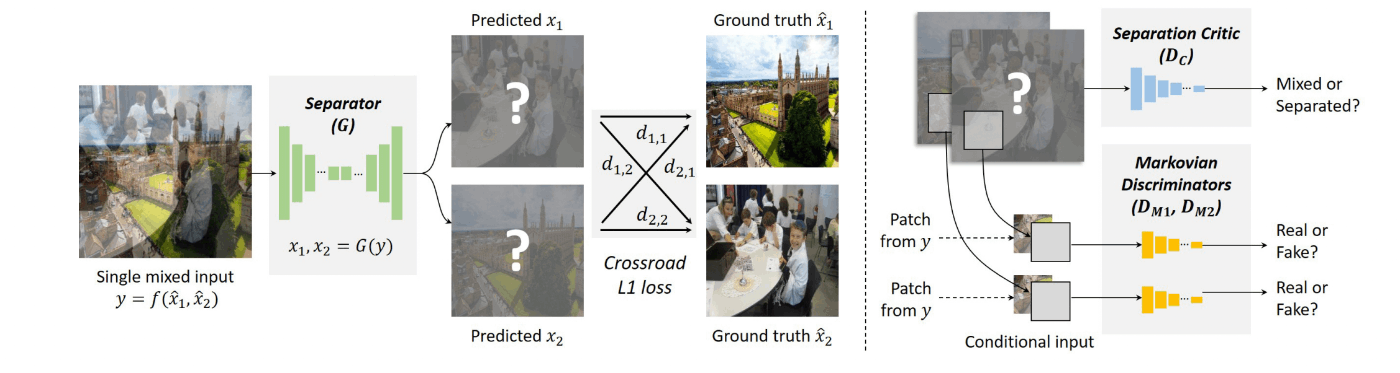
図1: 提案手法のアーキテクチャ
Criticの学習方法
学習時、Criticには以下の画像を入力として加える。
- Trueサンプル
- 合成前の2枚の画像
- Fakeサンプル
- Generatorの出力
- 合成前の画像をある比率で合成した2枚の画像
Criticの学習効率を上げるために、Trueサンプルを
Clossroad L1 Loss関数
Generatorが生成する2枚の画像は、本質的に順序に依存しない。
通常のL1 lossではこの性質を反映ないため、本論文では通常のL1ロスから順序の依存性をなくしたClossroad L1 lossというロス関数を導入する。
具体的には、Generatorの出力画像ペア、及び、それらの順序を入れ替えた画像ペアと正解ラベルのL1誤差のうち、小さい方をロスとする。
分離の良し悪しについての評価指標の比較
分離の良し悪しについて、既存の評価指標と、本手法で提案するCriticのロスによる評価指標の比較を図2に示す。
Adv-Criticというのが提案手法のことを指し、それ以外が既存の評価指標を指す。
論文では線形の合成と、線形の合成に1) overexposure, 2) random gamma, 3) random hueの3通りの非線形な変換を施した場合で比較する。
図の
図より、提案手法は既存の評価指標よりも分離の状態を反映していることがわかる。特に、非線形な変換を加えた入力に対してもロバストな性能を示す。
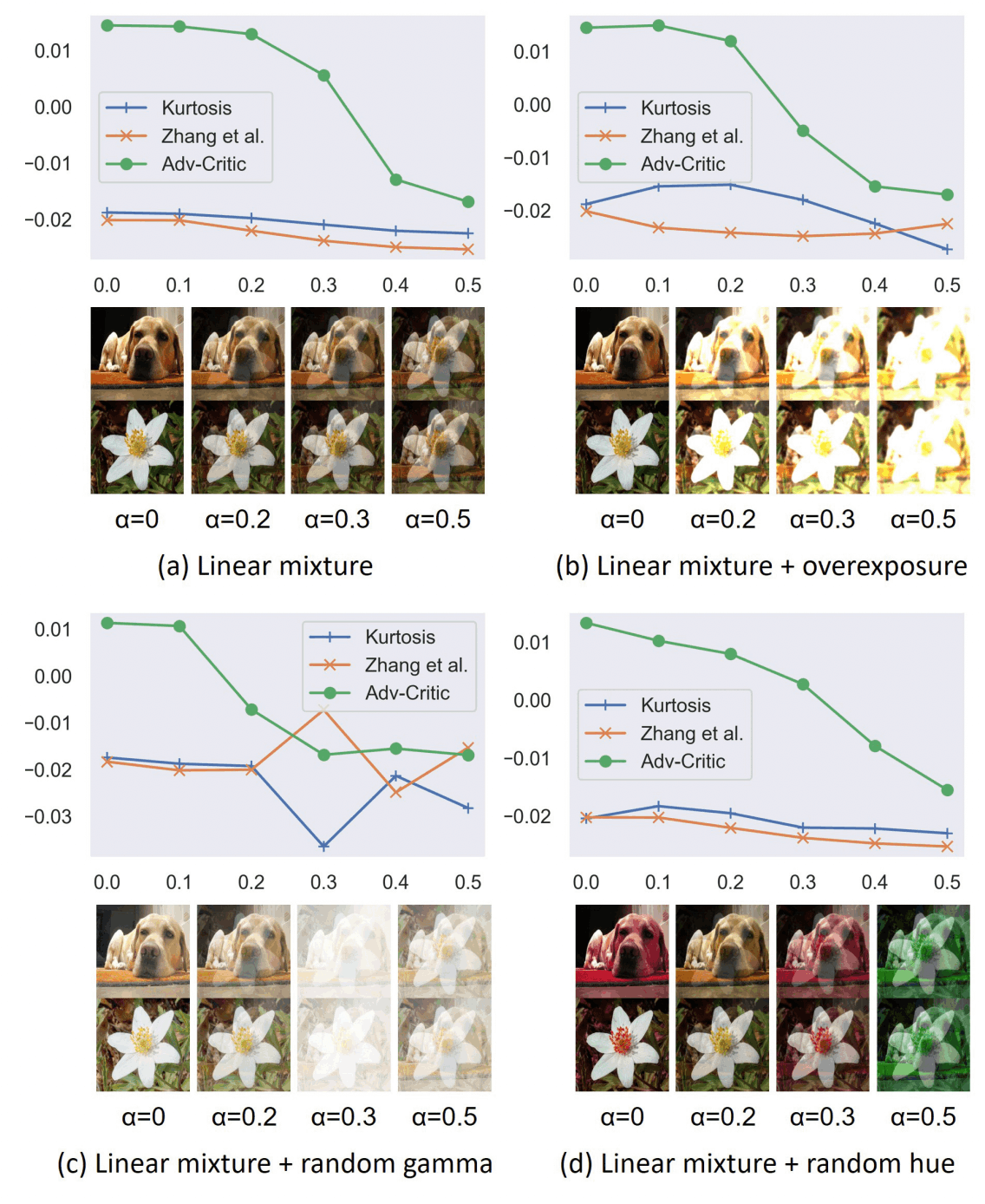
図2: 分離の良し悪しについての評価指標の比較
所感
- 既存手法がhand-craftedな制約に頼っていたこともあって、混合画像分離のタスクにおいて本手法はSOTAを大きく上回る精度を出している。
- また、本提案手法は制約を与える必要がないため、データのドメインの知識を必要とせず、さまざまなデータセット、タスクに対して汎用的に適用できる。
- 本手法は音源分離にも使えそう。著者も次の研究のターゲットとして会話の分離をあげている。
Discussion