論文要約: DITTO - 事前学習済み言語モデルを利用したEntity Matching手法
はじめに
entity matchingにけるmatcherに事前学習済み言語モデルを採用することで、各種ベンチマークにおいてSOTAを実現した手法。本論文では他にも1)ドメイン知識の追加 2) augmentation 3) 長いセンテンスの要約 を適用することでさらなる性能改善を実現した。
提案手法の構成について
まず、entity matchingタスクは以下の要素で構成される。
- blocker: 同じエンティティのペアの候補絞り、ふるいにかける
- matcher: エンティティのペアの候補を2値分類する
本論文で提案する手法は、matcherに事前学習済み言語モデルを採用することで、センテンス中の文脈の情報により注目する。
次に、本論文で提案するmatcherの構成について説明する。
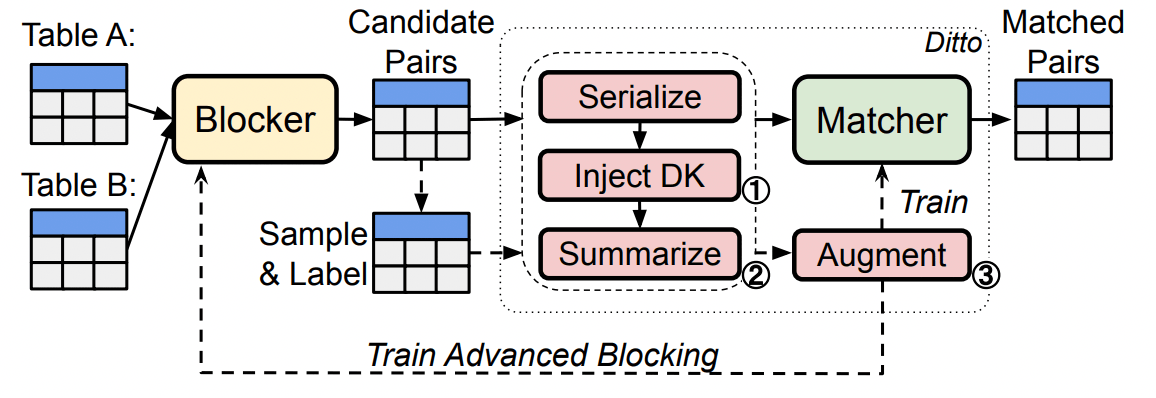
先行研究のDeepMatcherでは、2つのentityのペアのタプルのembeddingの距離をMLPに渡す構造だったが、本論文で提案するmatcherは言語モデル+FC層からなる。
タプルのペアを独立して渡すのでなく、両者を1つのセンテンスに結合して入力する(図参照)。

また、各タプルの表現についても異なり、DeepMatcherではスペース区切りのセンテンスとして扱っていたが、提案手法では[COL][VAL]というメタタグを使ってキーと属性を構造的に与える(JSONやYAMLのような形式)。
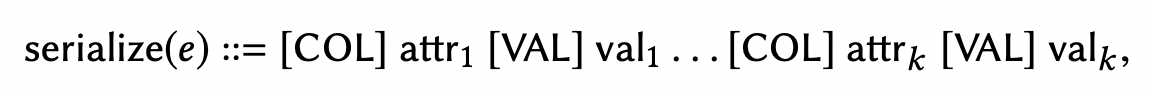
全体のアーキテクチャの概念図は以下:
その他の改善
事前学習モデルのファインチューンのみでもSOTAを達成しているが、本論文ではさらに以下の手法によってさらにスコアを伸ばしている。
- 属性タグの付加による事前知識の注入
- 長いセンテンスの要約
- augmentation
以下ではそれぞれの手法について説明する。
1) 属性タグの付加によるドメイン知識の注入
提案手法では学習時間を短縮するため、各値の属性の情報を追加で与える(例:人名、ID、電話番号の下4桁etc.)。属性の情報はEntity Recognition Model(ERM)[1]によって自動的に与える。このような属性タグによって、言語モデルはセンテンス中のどの情報に着目すれば良いかの手がかりを与えることができる。

2) 長いセンテンスの要約
Transformerベースの言語モデルは入力長の上限が決まっているため、長すぎるセンテンスは短くする必要がある。最初の固定単語でカットする方法があるが、entity matchingにおいては重要な情報が文頭にあるとは限らないため、この方法は適さない。本論文ではTF-IDFベースの文章要約を適用してセンテンスの長さを一定以下にした。
3) Augmentation
ラベル効率を改善するため、本論文では以下のaugmentationを適用した。
- 属性タグの消去
- 属性タグのシャッフル
- 属性の消去
- 属性のシャッフル
- エンティティペアの交換
また、一般的にテキストに対するaugmentationはセンテンスの特徴に大きすぎるノイズを加えてしまう問題がある。例えば、entity matchingの場合は、重要な属性を欠落させることで、macherが意味のある推論をするための情報がなくなることが懸念される。
これの問題を緩和するために、本論文では、MixDA[2]という手法を用いる。これはいわゆるMixUpのテキスト版で、入力のテキストをmixする代わりに、言語モデルの出力(=単語のembedding)を補完する。補完したembeddingは一般的に補完前のembeddingよりもノイズが小さいことが期待できる。
なお、MixDAはforward passを2回通るので、学習時の計算コストが増加する(推論時は無関係)。
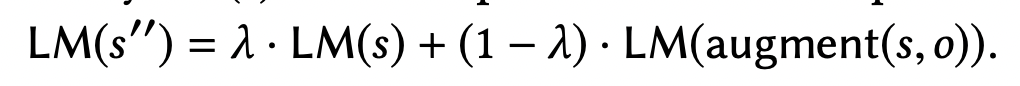
参考文献
[1] https://spacy.io/api/entityrecognizer
[2] https://arxiv.org/abs/2002.03049
Discussion