😴
同時に多数のterraform plan /applyをするときのRoute 53 API limit回避方法
前提
同時に多数のterraform plan / applyを1つのAWSアカウントに対して行っている。
それにはRoute53のリソースが多数含まれている。
発生する現象
複数のterraform実行でRoute53のAPIが呼び出されるため、5回/秒のAPI呼び出し制限に引っかかる。
これは1つのterraform実行だけであればその中でうまく調整できるものが、複数の実行が並行することでrate limitをうまく考慮できず、結果的に制限に引っかかるものである。
TF_LOG=DEBUGで実行すると次のようなログが出る。
http.response.body=
| <?xml version="1.0"?>
| <ErrorResponse xmlns="https://route53.amazonaws.com/doc/2013-04-01/"><Error><Type>Sender</Type><Code>Throttling</Code><Message>Rate exceeded</Message></Error><RequestId>390b160f-4aac-42a4-90fe-605d292c412d</RequestId></ErrorResponse>
http.response.header.date="Fri, 24 Jan 2025 09:55:52 GMT" tf_rpc=ReadResource @caller=github.com/hashicorp/aws-sdk-go-base/v2@v2.0.0-beta.61/logging/tf_logger.go:45 tf_aws.sdk=aws-sdk-go-v2 tf_provider_addr=registry.terraform.io/hashicorp/aws tf_resource_type=aws_route53_record http.duration=7 rpc.system=aws-api tf_aws.signing_region="" tf_req_id=7c6dec43-4411-99d0-aa3c-5ea569f1776d http.response.header.content_type=text/xml http.response_content_length=255 http.status_code=400 rpc.service="Route 53" timestamp=2025-01-24T09:55:52.738Z
2025-01-24T09:55:54.515Z [DEBUG] provider.terraform-provider-aws_v5.84.0_x5: retrying request Route 53/ListResourceRecordSets, attempt 2: aws.region=us-east-1 tf_rpc=ReadResource rpc.service="Route 53" tf_aws.sdk=aws-sdk-go-v2 tf_mux_provider="*schema.GRPCProviderServer" tf_resource_type=aws_route53_record @caller=github.com/hashicorp/aws-sdk-go-base/v2@v2.0.0-beta.61/logging/tf_logger.go:45 @module=aws rpc.method=ListResourceRecordSets rpc.system=aws-api tf_provider_addr=registry.terraform.io/hashicorp/aws tf_req_id=7c6dec43-4411-99d0-aa3c-5ea569f1776d timestamp=2025-01-24T09:55:54.515Z
2025-01-24T09:55:54.515Z [DEBUG] provider.terraform-provider-aws_v5.84.0_x5: HTTP Request Sent: @caller=github.com/hashicorp/aws-sdk-go-base/v2@v2.0.0-beta.61/logging/tf_logger.go:45 aws.region=us-east-1 tf_aws.sdk=aws-sdk-go-v2 http.request.header.authorization="AWS4-HMAC-SHA256 Credential=ASIA************D75P/20250124/us-east-1/route53/aws4_request, SignedHeaders=amz-sdk-invocation-id;amz-sdk-request;host;x-amz-date;x-amz-security-token, Signature=*****" tf_provider_addr=registry.terraform.io/hashicorp/aws tf_req_id=7c6dec43-4411-99d0-aa3c-5ea569f1776d http.request.header.x_amz_security_token="*****" http.user_agent="APN/1.0 HashiCorp/1.0 Terraform/1.10.5 (+https://www.terraform.io) terraform-provider-aws/5.84.0 (+https://registry.terraform.io/providers/hashicorp/aws) aws-sdk-go-v2/1.32.8 ua/2.1 os/linux lang/go#1.23.3 md/GOOS#linux md/GOARCH#amd64 api/route53#1.48.0" net.peer.name=route53.amazonaws.com tf_mux_provider="*schema.GRPCProviderServer" http.method=GET http.request.body="" http.request.header.amz
2025-01-24T09:55:54.555Z [DEBUG] provider.terraform-provider-aws_v5.84.0_x5: HTTP Response Received: http.status_code=400 rpc.method=ListResourceRecordSets rpc.service="Route 53" tf_provider_addr=registry.terraform.io/hashicorp/aws @module=aws tf_resource_type=aws_route53_record tf_aws.signing_region="" tf_mux_provider="*schema.GRPCProviderServer" @caller=github.com/hashicorp/aws-sdk-go-base/v2@v2.0.0-beta.61/logging/tf_logger.go:45 aws.region=us-east-1 http.response.header.content_type=text/xml rpc.system=aws-api http.response.header.x_amzn_requestid=06f57079-d7f3-422b-a915-8d9fa9e77d1d tf_req_id=7c6dec43-4411-99d0-aa3c-5ea569f1776d tf_aws.sdk=aws-sdk-go-v2 tf_rpc=ReadResource http.duration=39
これが厄介なのは、再実行のタイミングまで衝突してしまう点である。
もしこの再実行のタイミングまで衝突してしまうとまたしばらく待つ必要があるため、この再実行タイミングがズレないと理論上無限に衝突してしまう(実際には衝突しても5API呼び出しは成功するのでいつかは終わるが)
対策
terraform実行自体をずらす。
github actionsで実行しているのなら、次のようなsleepステップを terraform plan / apply 実行前に挟む。
- name: route53 API rate limit回避のためのsleep
run: |
base_sec=17
case "${{ matrix.working_directory }}" in
"project/a") sleep $((base_sec * 1)) ;;
"project/b") sleep $((base_sec * 2)) ;;
"project/c") sleep $((base_sec * 3)) ;;
"project/d") sleep $((base_sec * 4)) ;;
"project/e") sleep $((base_sec * 5)) ;;
"project/f") sleep $((base_sec * 6)) ;;
"project/g") sleep $((base_sec * 7)) ;;
"project/h") sleep $((base_sec * 8)) ;;
"project/i") sleep $((base_sec * 9)) ;;
"project/j") sleep $((base_sec * 10)) ;;
esac
これにより最初および再度の衝突確率を下げ、結果的に全体が早く終わるようになる。
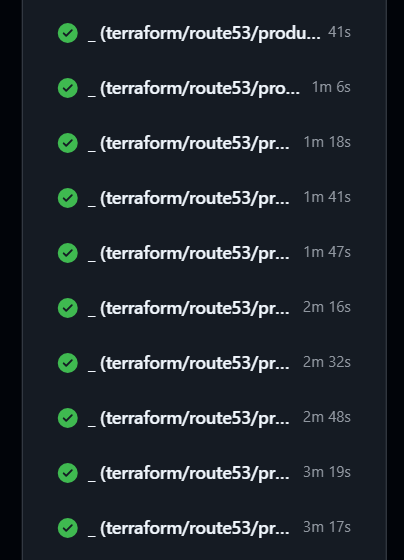
実際の効果
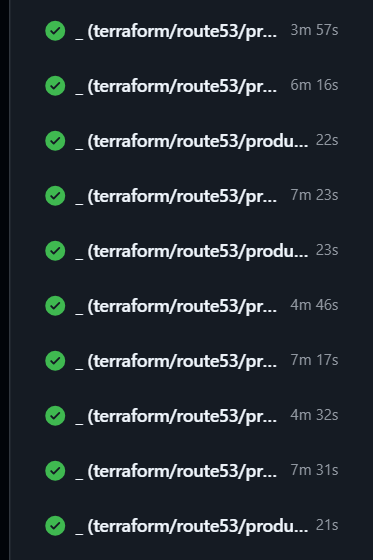
のように通常7~10分かかっていた10個のroute53関連terraform実行が、
sleepを挟むことで4分以下に収まるようになった。
Discussion
retry mode は試されましたか?
adaptive に設定してみると、比較的容易に回避できるかもしれません
ありがとうございます。
こんなオプションあったんですね、知りませんでした。
確かに行けそうな気がして試してみたのですが、
普通に
しただけではむしろ実行時間が伸びてしまいました。
うおおおお。早速ありがとうございます。
想定どおりの結果ですね。
リトライ回数を増やすだけで長時間の同時実行をエラーにしないで終わらせられる可能性は知っていたのですが、モードを adaptive にするとどうかは試せたことがなくて。。。
今のところ adaptive だと内部的なリクエスト制限がかかる感じになるので、全体的に時間がかかるようになる(APIコールの同時処理量が減る)はずなので、総処理時間は伸びるものと思っていました。
実行側で sleep 処理をしなくても避けられる、程度かなと。。。