AWS認定 MLS 勉強メモ
はじめに
かなり適当なメモですが、マシンラーニング知識0からMLSを取得するまでに身につけた知識をなるべくそのまま書き出したものです。
練習問題に取り組みつつ、見知らぬ単語を一度ここに書き出して、その単語が解答に絡んでいる場合はGoogleで検索して記事を少し読みました。また、何度も出てくる単語はYoutubeの解説も参考にしました。
逆に書き出したものの、特に調べていないものは詳細を追記していません。
内容に間違いがあったらすみませんorz
機械学習
過去問に謎に歯ブラシと歯磨き粉の会社が多い
回帰
分類
線形学習
クラスタリング
ニューラルネットワーク
正則化
正規化
まだ分類してない
主成分分析法(PCA)
多くの変数を持つデータを集約して主成分を作成する統計的分析手法。
何かを予測する教師あり学習ではなく、教師なし学習にあたる。
主成分とはデータの特徴を表す要素のことで、「第一主成分、第二主成分・・・」という形で表現する。
教師なし機械学習
学習データに正解を与えない状態で学習させる学習手法。学習データに正解を与える「教師あり学習」と対をなす機械学習の学習手法となっている。教師なし学習では予測や判定の対象となる正解が存在しないため、教師あり学習とは違い回帰や分類の問題には対応できない。
教師なし学習で行なう代表的な例は以下
- クラスタリング
- 次元削減
教師あり機械学習
学習データに正解を与えた状態で学習させる手法。学習データに正解を与えない「教師なし学習」と対をなす機械学習の学習手法となっている。教師あり学習では、トレーニングデータや教師データなどと呼ばれる正解となる学習データを利用する。つまり、正解・不正解が明確な問題の解決に利用できる学習手法。例えば、システムの不正行為の検出や、おすすめ製品のパーソナライズなどを実現できる。
学習と認識・予測の2段階のプロセスで構成されており、このプロセスを実現するアルゴリズムとして回帰と分類が使用される。なお、ディープラーニング(深層学習)は基本的に教師あり学習を発展させたもの。
教師あり学習で利用される代表的なアルゴリズムは以下
- 回帰
- 分類
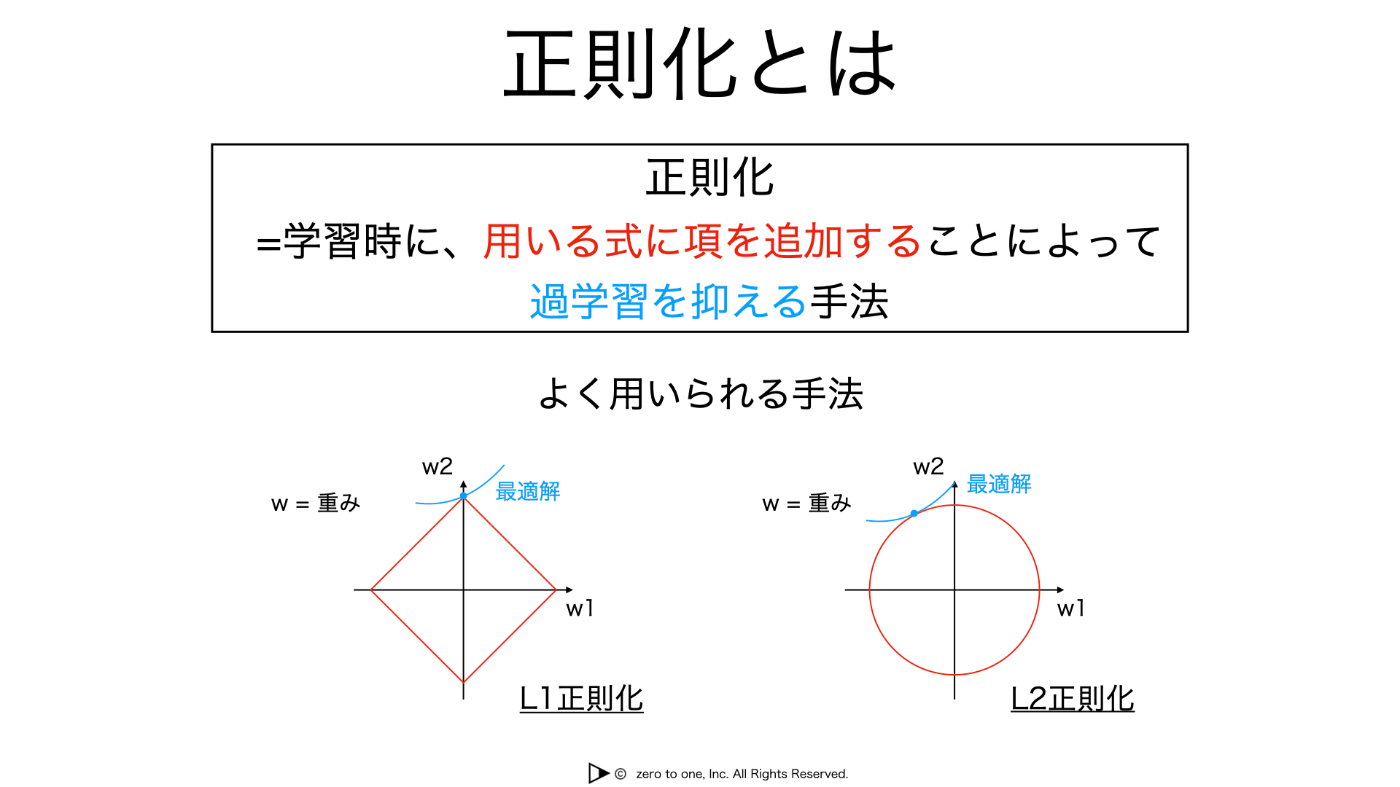
正則化(Regularization)
学習時に用いる式に項を追加することによってとりうる重みの値の範囲を制限し、過度に重みが訓練データに対してのみ調整される(過学習する)ことを防ぐ役割を果たす。
活性化関数 tanh関数?
SELU(Scaled Exponential Linear Unit)
長・短期記憶(LSTM)
バイナリ分類(二値分類)
複数クラスの分類(多クラス分類)
探索的データ分析
箱ヒゲ図(Box Plot Chart)
正規化変換
推論
エポック数(epoch)
一つのトレーニングデータを何回繰り返して学習させるかの数のこと。
Deep Learningのようにパラメータ数が多いものになると、トレーニングデータを何回も繰り返して学習させないとパラメータをうまく学習できない。やりすぎてもダメ。
テキスト特微量エンジニアリング手法(Feature Engineering)
Term Frequency - Inverse Document Frequency(TF-IDF、単語出現頻度-逆文書頻度)
N-Gram
nグラム変換
Bag-of-Words
直角のスパースなバイグラム(OSB)
シミュレーションに基づく強化学習
ヒューリスティックアプローチ
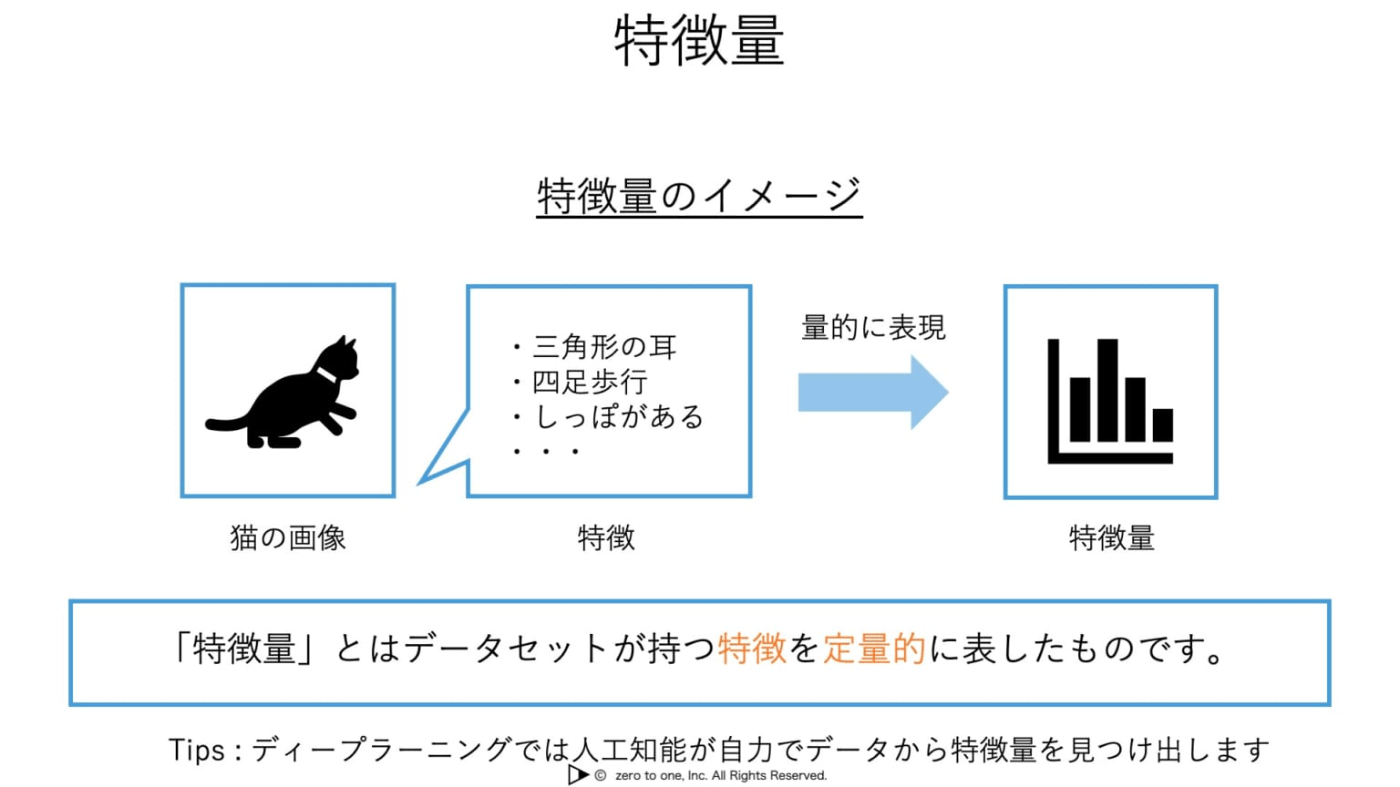
特微量
人工知能に学習させようとするデータセットの特徴を定量的に表現したもの。
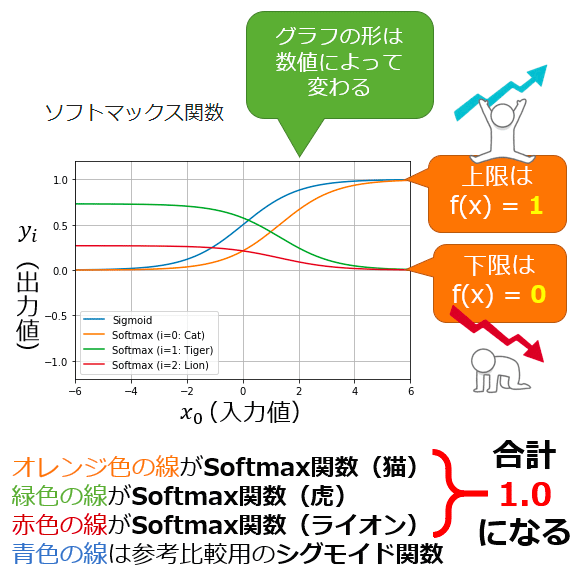
ソフトマックス関数(正規化指数関数)
入力データ(=ベクトル)内の複数の値(=ベクトルの各成分)を0.0~1.0の範囲の確率値に変換する関数である。この関数によって出力される複数の値(=ベクトルの各成分)の合計は常に1.0(=100%)になる。
ソフトマックス関数の出力値をグラフにすると、滑らかな(=ソフトな)曲線が得られる(図1)。この滑らかさと、1つの成分だけが最大値を取る特性から「ソフトマックス関数」と呼ばれる。
感情分析
自然言語処理(NLP)
独立変数
エルボー法
二乗平均平方根誤差(RMSE)
曲線下面積(AUC)
混同行列
ある手法を用いて分類処理を行った場合に、分類した値(陰/陽)とその正誤(真/偽)について結果をまとめた表。
分類手法の特徴は、この混同行列にまとめられた値をもとに定量的に評価することができる。もちろんAmazon MLで構築するモデルも、二項分類モデルや多項分類モデルは分類の一種であるため、この混同行列にまとめられた結果をもとに評価が行われる。
表上の各項目は以下のような名前で表現される。
- 分類結果が陽であり、予測結果が正しい場合 : 真陽性 (True Positive)
- 分類結果が陽であり、予測結果が誤りの場合 : 偽陽性 (False Positive)
- 分類結果が陰であり、予測結果が正しい場合 : 真陰性 (True Negative)
- 分類結果が陰であり、予測結果が誤りの場合 : 偽陰性 (False Negative)

潜在的ディリクレ配分(LDA)
傾向
季節性
損失関数
コーパス
線形最小二乗回帰モデル
多重代入法
SMOTE(Synthetic Minority Oversampling Technique )
分析に使うカテゴリ対象データが不均衡であり、そのデータ数が少ないカテゴリに対して、オーバーサンプリングする分析テクニック。内部で機械学習のアルゴリズムを使ってオーバーサンプリングを実施する。
過学習
四分位ビニング
非線形のデータを扱うための変換手段の一つ。
数値変数と bin 番号と呼ばれるパラメータの 2 つの入力を受け取り、カテゴリ変数を出力する。目的は、観測値をグループ化して変数の分布における非直線性を発見すること。
トレーニング前のバイアスの測定
カテゴリカル変数のバイアス分布を評価するのに適しているメトリクス
- ジェンセンシャノン情報量 (JS)
- カルバックライブラー情報量 (KL)
- 合計変動距離 (TVD)
アルゴリズム
回帰
機械学習モデルの一般的なタイプの 1 つ。連続する入力値に対する次の値を予測することを指し、結果に対する原因を推測するために、例えば宣伝広告費と来店者数の関係を数字に直して分析する際などに活用できる。原因となる説明変数が一つの場合には単回帰分析、複数になると重回帰分析などと呼び分ける。
線形回帰
別の関連する既知のデータ値を使用して未知のデータの値を予測するデータ分析手法。未知または従属変数と、既知または独立変数を線形方程式として数学的にモデル化する。たとえば、昨年の支出と収入に関するデータがあるとする。線形回帰手法では、このデータを分析し、支出が収入の半分であると判断する。次に、将来の既知の収入を半分にすることによって、未知の将来の費用を計算する。
ロジスティック回帰
目的変数が0と1からなる2値のデータ、あるいは0から1までの値からなる確率などのデータについて、説明変数を使った式で表す。 ロジスティック回帰分析を行うと、説明変数を用いてある事象が起こる確率を予測することができる。
多変量回帰
複数の説明変数と1つの目的変数との関係を調べるための統計的手法。これは、説明変数が目的変数にどのように影響を及ぼすかを理解し、予測分析や要因分析を行う。
多変量回帰分析では、独立変数と従属変数の間の線形関係をモデル化する。モデルは、各説明変数の係数(回帰係数)と、モデルの切片(定数項)から構成される。回帰係数は、説明変数の値の変化が目的変数にどのような影響を与えるかを示す。
多変量回帰分析は、実際のデータからモデルを構築するために最小二乗法などの統計的手法を使用する。構築されたモデルは、独立変数の値が与えられた場合に、従属変数の値を予測するために使用できる。多変量回帰分析として主として重回帰分析とロジスティック回帰分析が使われる。
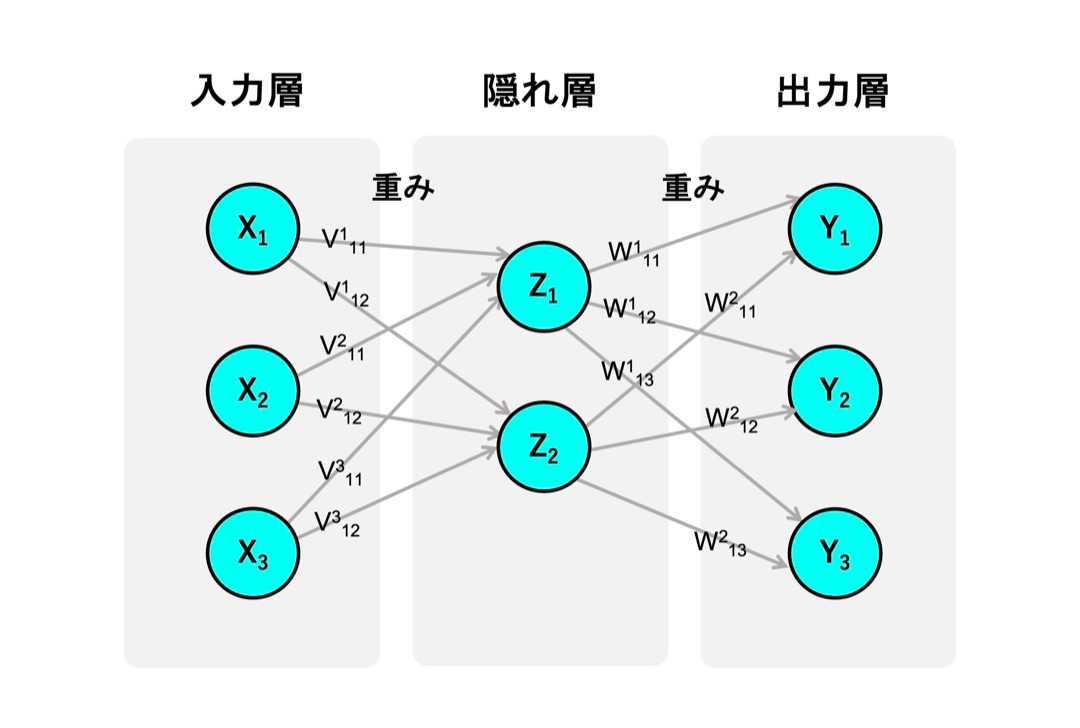
ニューラルネットワーク
人間の脳の神経回路の構造を数学的に表現する手法。脳内の神経細胞である「ニューロン(neuron)」を語源とし、主に音声や画像などのパターンを認識する際に活用される。
一般的なニューラルネットワークは、情報が入力される「入力層」、情報が発信される「出力層」、その中間にある「隠れ層」の3層で構成されている。
なかでもニューラルネットワークの肝となるのが、入力されたデータに対してさまざまな計算を行う隠れ層。隠れ層をいくつも持つことで、より複雑な問題にも対処できるようになる。
自動符号化器(オートエンコーダ)
入力された記号をエンコード(符号化、圧縮)して別のものに変え、もとの形に戻して出力する手法。
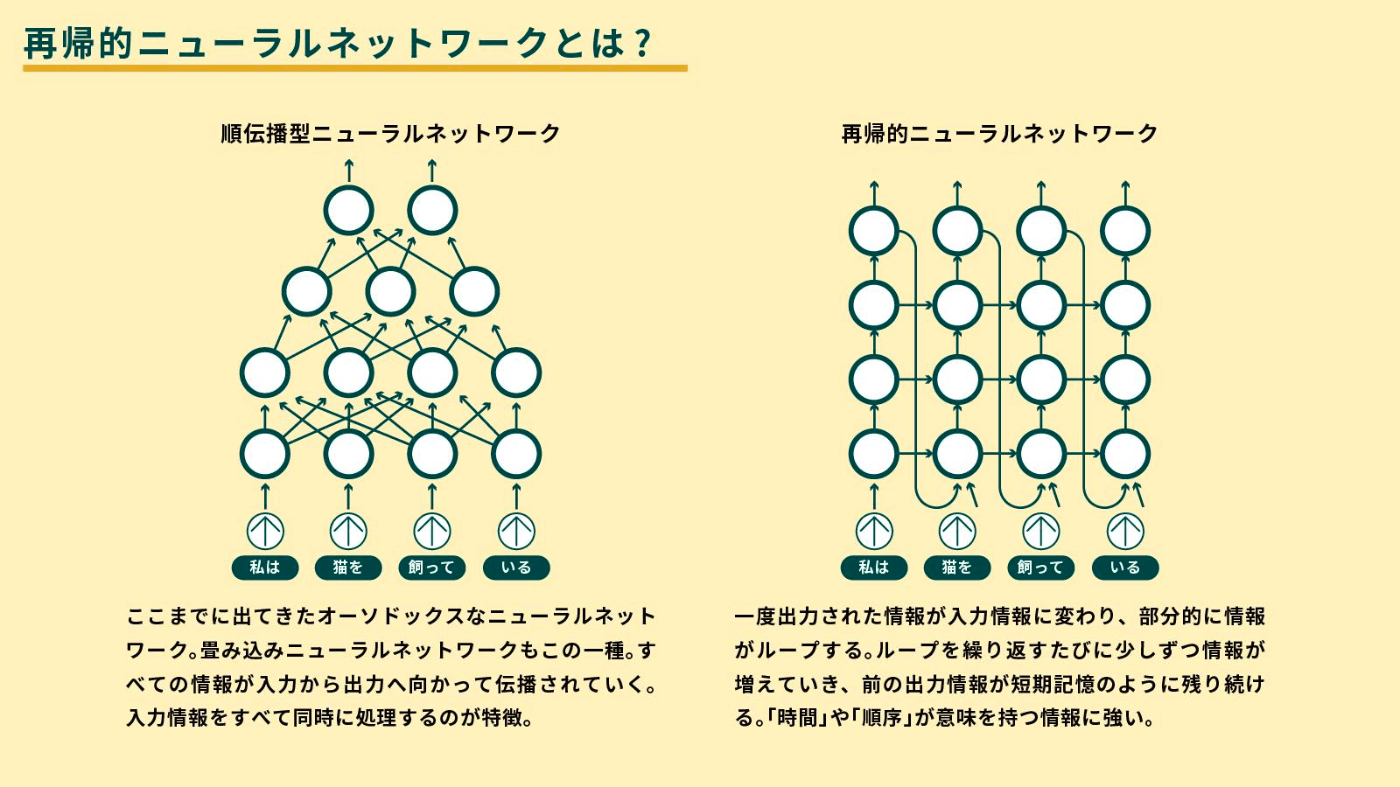
再帰型ニューラルネットワーク(RNN)
回帰型・循環型とも呼ばれるニューラルネットワーク。参考URL先を一読推奨。
畳み込みニューラルネットワーク(CNN)
人間の脳神経系の仕組みを模倣したニューラルネットワークに「Convolution(畳み込み)層」を追加したアルゴリズム。CNNは人間の脳の神経細胞「ニューロン」を模したモデルで「層」と呼ばれる内部構造を持つ。主に「畳み込み層」「プーリング層」「全結合層」の3つの層から構成される。
回帰型ニューラルネットワーク
順次データまたは時系列データを使用する一種の人工ニューラル・ネットワーク。 これらのディープ・ラーニング・アルゴリズムは、言語翻訳、自然言語処理(NLP)、音声認識、および画像キャプションなどの順序問題または一時的な問題によく使用される。
ニューラルトピックモデル(NTM)
書集合で話題となっているトピックを、同じ文書で現れやすい語彙として抽出する手法。文書のメタ情報の抽出や、トピックを使って文書の分類に使用できる。
トピックモデルでは、文書は構造化されている必要はないため、構造化させる手間がなく、使用しやすい分析手法と言える。
木系
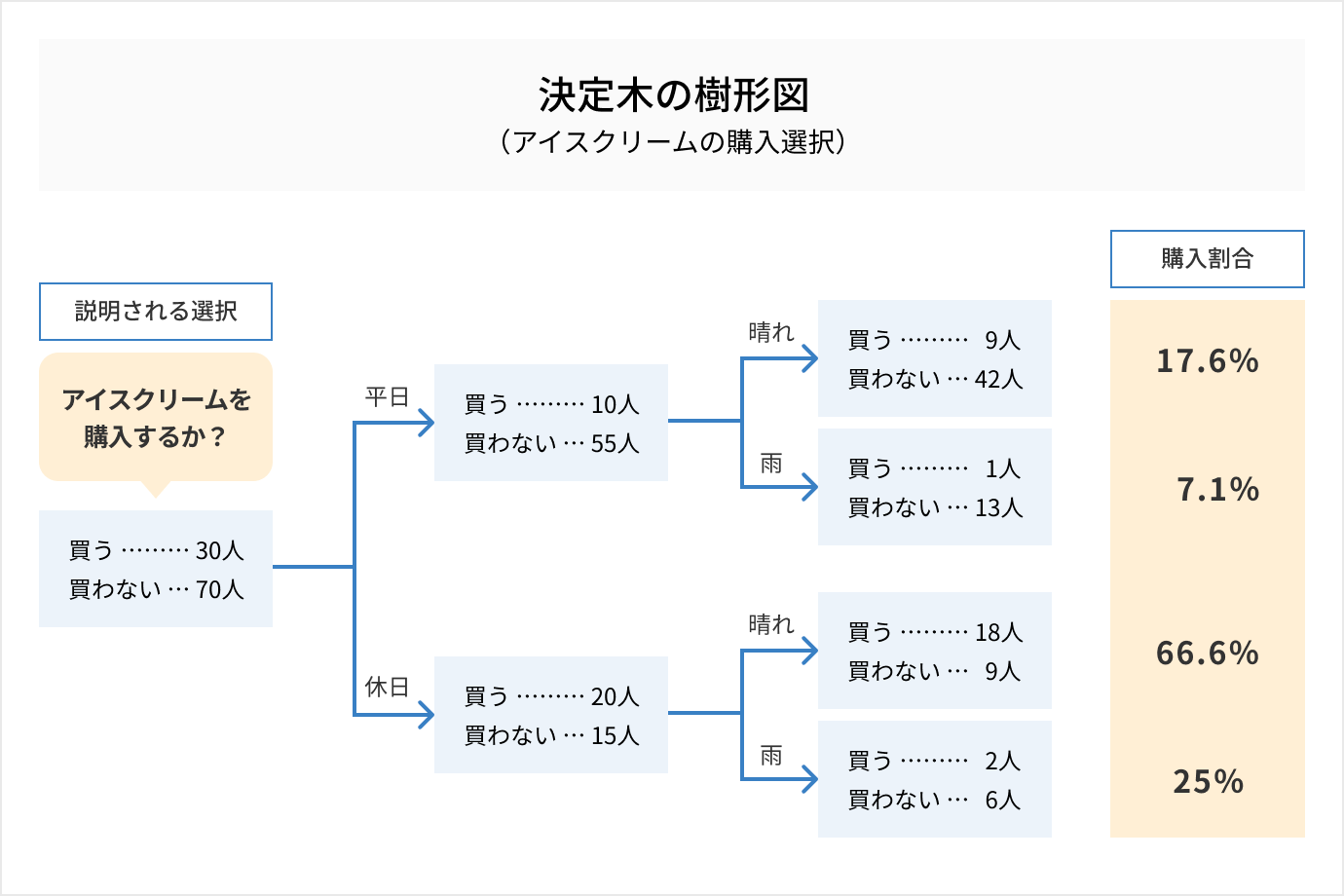
分類木
その日が平日か休日か、そして天気が晴れか雨かといった各要素に対して、「アイスクリームを買う/買わない」といった区分結果を表したツリー。
回帰木
「アイスクリームを買う/買わない」といった区分結果を分析する場合には「分類木」を使うが、「○円のアイスクリームを買う」といった連続して変わりうる値を分析する場合には「回帰木」(かいきぎ)を使う。
たとえば、ポスティングしたクーポンの利用枚数は、「天気」「チラシのポスティング数」などの要素に左右されると仮定する。
この場合、「天気は晴れか?」→YES→「チラシを1万枚ポスティングしたか?」→YES→1万枚あたり35人が来客、といったように、連続値(この場合は35人)を推定するルールをツリーの流れで表したもの。
決定木(ディシジョンツリー)
分類木と回帰木を組み合わせたもので、ツリー(樹形図)によってデータを分析する手法。機械学習や統計、マーケティングや意思決定などさまざまな分野で用いられる。
ランダムフォレスト
Leo Breiman氏とAdele Cutler氏によって商標登録された、一般的に使用されている機械学習アルゴリズムであり、複数の決定木の出力を組み合わせて1つの結果に到達する。 分類と回帰の両方の問題を処理するランダム・フォレストは、その使いやすさと柔軟性により広く採用されている。
ランダムカットフォレスト(RCF)
データセット内の異常なデータポイントを検出する教師なしアルゴリズム。決定木ベースなので決定木をイメージすると分かりやすい。分類と回帰の両方で使える。
XGBoost(eXtreme Gradient Boosting)
決定木に基づき、ランダム フォレストや勾配ブーストなどの他の手法を改善したもの。 さまざまな最適化の方法を使用することにより、大規模で複雑なデータセットの処理で性能を発揮する。
k系
k近傍法(k-NN)
データをグループ分けするにあたり、対象とするあるデータがどのグループに含まれるかを周囲のデータの多数決で推測するという手法。
k近傍法は非常にシンプルな手法であるため、学習を必要としない、外れ値に頑健であるといったメリットがある。一方、それぞれのデータについて多数決を取らなければならないという性質上、データ数が増えるに伴って計算量も非常に多くなってしまうというデメリットがある。
k平均法(K-means)
まずデータを適当なクラスタに分けた後、クラスタの平均を用いてうまい具合にデータがわかれるように調整させていくアルゴリズム。任意の指定のk個のクラスタを作成するアルゴリズムであることから、k-means法(k点平均法)と呼ばれている。
k-means法には最初のランダムのクラスタの割り振りによって精度が変わってしまうという問題点がある。
未分類
サポートベクタマシン(SVM)
信号処理医療アプリケーションや自然言語処理、音声および画像認識などの多くの分類と回帰の問題に使用される教師あり学習アルゴリズム。
SVM アルゴリズムの目的は、あるクラスのデータ点を、別のクラスのデータ点から、可能な限り分離する超平面を見つけること。「最適」は、2 つのクラス間で最大のマージンを持つ超平面を指す。以下の図では、これをプラスとマイナスで表している。マージンとは、内部にデータ点を持たない超平面に平行なスラブの最大幅を意味する。線形分離可能な問題でのみ、そのアルゴリズムはそのような超平面を見つけることができる。ほとんどの現実的な問題では、アルゴリズムは少数の誤分類を許容しながら、ソフトマージンを最大化する。

ナイーブベイズ(単純ベイズ分類器)
確率に基づいて予測を行うモデルで、ベイズの定理の考え方をもとにしたアルゴリズム。性能はやや劣ることがあるものの、高速に訓練でき実装も比較的容易。
モンテカルロシミュレーション
「自由なサイコロをいくつも作って、何回も投げること」。
活用例として、ビジネスリスク分析が挙げられる。事業性評価や需要予測、売上予測、投資効果の予測、マーケティング関連の分析によく使われている。
モンテカルロ・シミュレーションには、分からないもの・決められていないものをそのままに扱えるというメリットがある。 例えば、売上や成長率、為替、競合の動き、業界成長率、製品スペックの想定など。 さらに、これらの影響をまとめて確認して何が重要な因子になっているのかを特定できるというのもポイントである。
seq2seq
文から文を生成するモデルである。はじめに、入力文を単語ごとに順に読み込み、固定長の内部表現に変換し、またその固定長の内部表現から可変長の文を単語ごとに順に生成する。seq2seqは入力系列を固定長に収めるという、かなり強い制約のもとで学習を行う。
マルコフ連鎖モンテカルロ法(MCMC)
因数分解機アルゴリズム
協調フィルタリング(CF)
DeepAR予測
指標(メトリクス)
機械学習で分類モデルを作成した際、モデルの精度をどのように評価すべきか、モデルを評価する際に使用されるものを評価指標と呼ぶ。
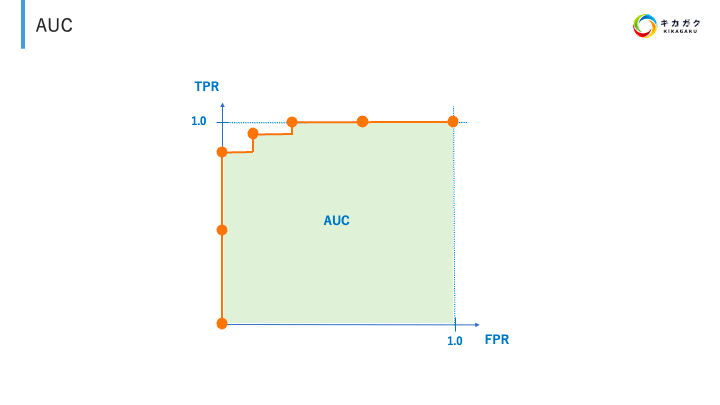
AUC/ROC
ROC曲線

各軸は TPR、FPR を表しており、Positive と Negative に分類する際の閾値を変更した際の TPR、FPR の値をプロットしている。
AUC は Area Under the Curve の略であり、ROC 曲線の下部分の面積のこと。
正解率(Accuracy)
二値分類や多クラス分類のタスク(問題)に対する評価指標の一つで、機械学習モデルによる予測結果などにおける正解数をデータ数で割った値である。0.0(=0%)~1.0(=100%)の範囲の値になり、1.0に近づくほどより良い。
再現率(Recall)/感度(Sensitivity)
二値分類のタスク(問題)に対する評価指標の一つで、正解値(真の値)が「陽性(Positive、正例)」であるデータ全体のうち、機械学習モデルによる予測値も「陽性」で正解だった確率である。0.0(=0%)~1.0(=100%)の範囲の値になり、1.0に近づくほどより良い。
適合率(Precision)
二値分類のタスク(問題)に対する評価指標の一つで、「陽性(Positive、正例)」と予測したデータの中で実際に「陽性」が正解だった確率である。0.0(=0%)~1.0(=100%)の範囲の値になり、1.0に近づくほどより良い。
特異性(Specificity)
二値分類のタスク(問題)に対する評価指標の一つで、正解値(真の値)が「陰性(Negative、負例)」であるデータ全体のうち、機械学習モデルによる予測値も「陰性」で正解だった確率である。0.0(=0%)~1.0(=100%)の範囲の値になり、1.0に近づくほどより良い。
勾配
勾配
勾配チェック
勾配消失
機械学習手法の一つであるニューラルネットワークの設計において、勾配が消失することで学習が進まなくなる技術的な問題のこと。
異常検知技術
教師なし異常検知
教師あり異常検知
半教師あり異常検知
AWSサービス関係(大事だと思ったサービスに⭐️)
⭐️Amazon SageMaker
推論パイプライン
ノートブック
RecordIOデータ形式
Amazon SageMaker Clarify
Amazon Machine Learning
バイナリ分類モデル
⭐️AWS Glue
よく出る
AWS GlueジョブでデータをApache Parquet形式に変換できる
⭐️Amazon Kinesis Data Firehose
⭐️Amazon Kinesis Data Streams
Amazon Kinesis Data Analytics
⭐️Amazon Kinesis Video Streams
⭐️Amazon Athena
Amazon EMR
Spark
AWS KMS
AWS Step Functions
Amazon S3
Amazon CloudWatch
アラーム
AWS CloudTrail
Amazon Mechanical Turk
AWS Data Pipeline
AWS IoT
AWS IoT Greengrass
Amazon QuickSight
⭐️AWS Rekognition
⭐️Amazon Comprehend
Amazon Elastic Inference
AWS PrivateLink
AWS Storage Gateway
Amazon Polly
発音レキシコン
Discussion