Google Gemini Pro の テキスト・画像入力を JavaScript で試してみた
Google Gemini Pro が今は無料
昨年末より Google のGemini Proが無料で試せるようになっています。
詳しくは以下の記事に書いている通りですが、Gemini Proは文字・音声・画像を同時に処理できるマルチモーダルAIで、テキスト入力はもちろん、テキストと画像を用いた内容にもAIが応答しれくれます。
今回、Google が用意してくれたドキュメントを元にJavaScriptでマルチモーダル(テキストと画像の同時処理)を実装してみました。
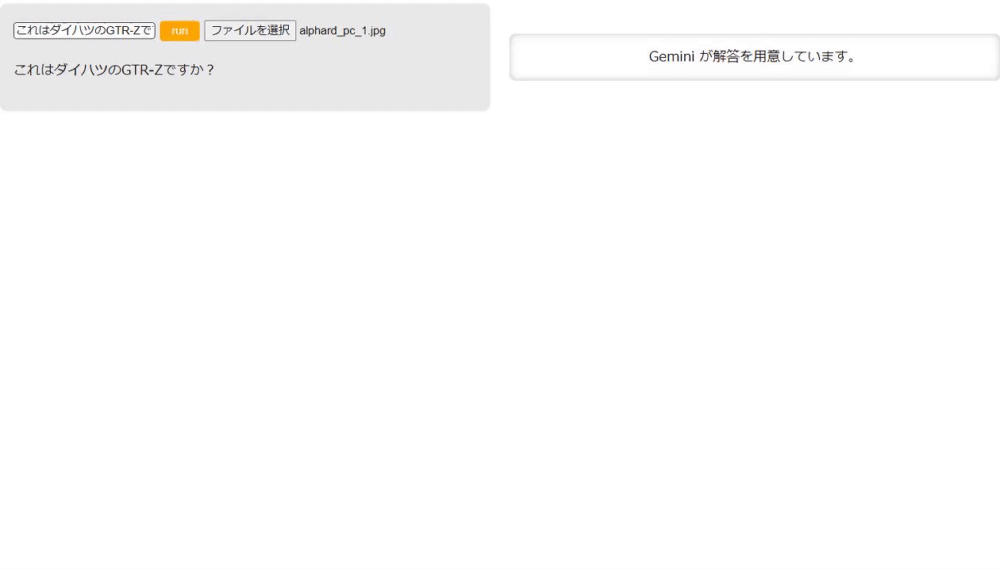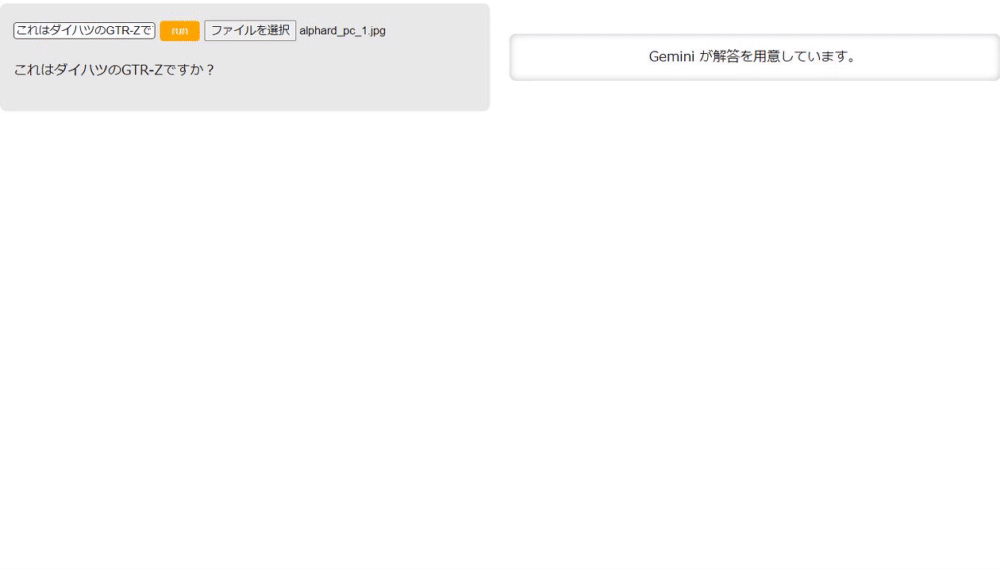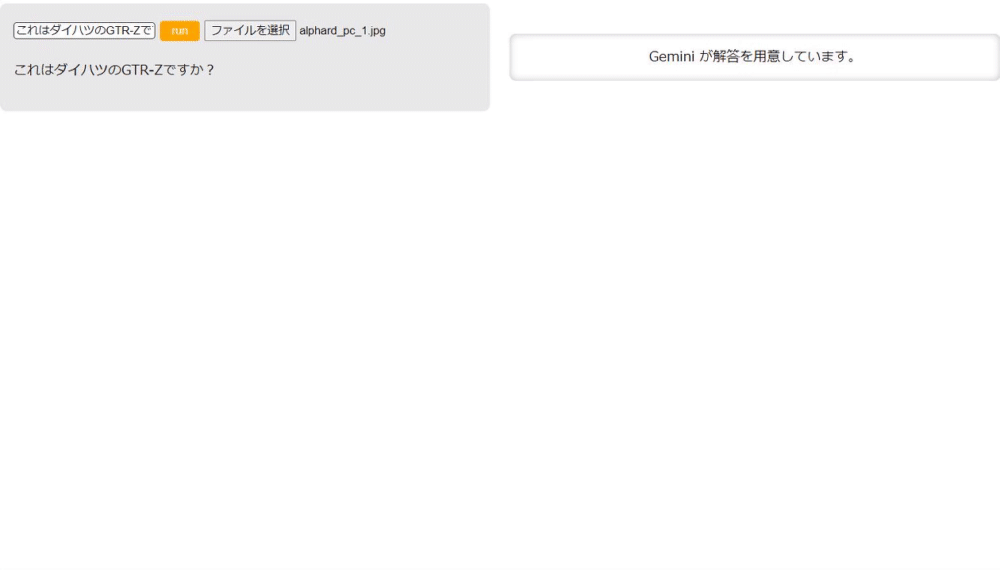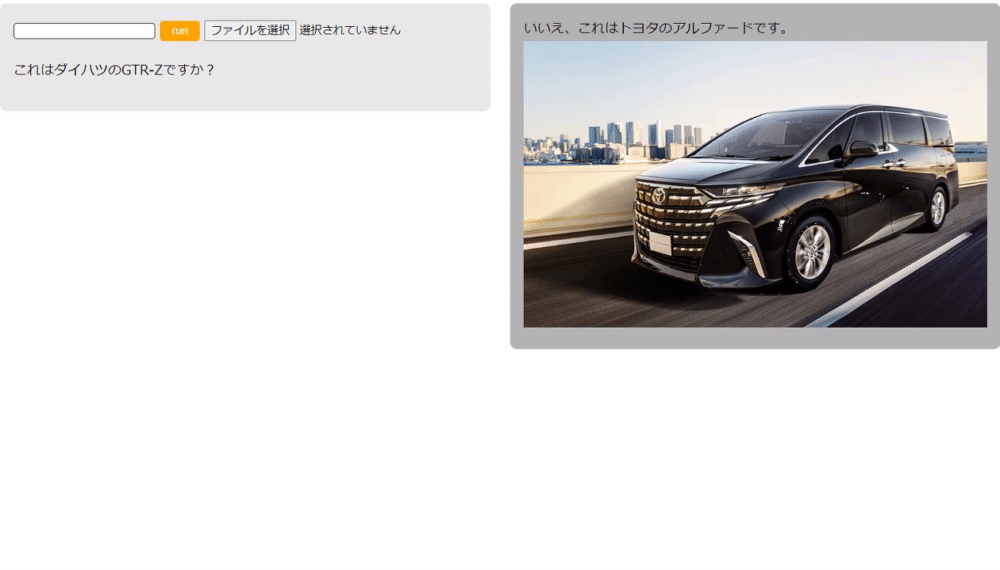
「ダイハツのGTR-Z」という架空の自動車に対して正確な情報をGeminiが返してくれています。
以下のQiita記事で筆者はGeminiの無料使用のことを知って、昨日テキスト入力だけの実装を行っていたのですが、作る中でGeminiにはテキスト入力モード?のGemini Pro と テキスト・画像の同時処理モード?のGemini Pro Vision の2種類があることも知りました。
Gemini Pro Vision
先ほど説明したGeminiのテキスト・画像の同時処理モード?です。
冒頭に貼ったgif画像のようなことができます。
今回筆者はタイトルにあるようにJavaScriptでGemini Pro Visionを試用しました。
JavaScriptの項目をクリックすると(どの言語でも同じでしょうが)以下のように試用チュートリアルが記載されています。

筆者は「テキストと画像の入力からテキストを生成する(マルチモーダル)」という内容を元に実装していきました。
コードは以下になります。GeminiのAPI_KEYさえ取得されていればローカル環境で手軽に試せますので良ければGeminiを使ってみてください。
Javascript
import { GoogleGenerativeAI } from "@google/generative-ai";
/* 各種 DOM 要素 */
const formElm = document.querySelector('form#runForm'); // 包括する form 要素
const inputElm = document.querySelector('input[type="text"]'); // プロンプト入力欄
const fileElm = document.querySelector('input[type="file"]'); // プロンプト入力欄
const answerElm = document.querySelector('.answer'); // gemini の解答反映用
const geminiLoading = document.querySelector('.geminiLoading') // loading
// Fetch your API_KEY
const API_KEY = "YOUR_API_KEY_STRING";
// Access your API key (see "Set up your API key" above)
const genAI = new GoogleGenerativeAI(API_KEY);
// Converts a File object to a GoogleGenerativeAI.Part object.
const fileToGenerativePart = async (file) => {
const base64EncodedDataPromise = new Promise((resolve) => {
const reader = new FileReader();
reader.onloadend = () => {
const readerResult = reader.result;
answerElm.insertAdjacentHTML('afterbegin', `<img src=${readerResult} />`);
resolve(readerResult.split(',')[1])
};
reader.readAsDataURL(file);
});
return {
inlineData: { data: await base64EncodedDataPromise, mimeType: file.type },
};
}
const run = async (
inputValueLength,
inputValue
) => {
geminiLoading.classList.add('OnView');
formElm.insertAdjacentHTML('beforeend', `<p>${inputValue}</p>`);
if (answerElm.classList.contains('OnView')) {
answerElm.innerHTML = '';
answerElm.classList.remove('OnView');
}
if (inputValueLength > 0 && fileElm.value.length > 0) {
// For text-and-images input (multimodal), use the gemini-pro-vision model
const model = genAI.getGenerativeModel({ model: "gemini-pro-vision" });
const prompt = inputValue;
const fileInputEl = document.querySelector("input[type=file]");
const imageParts = await Promise.all(
[...fileInputEl.files].map(fileToGenerativePart)
);
const result = await model.generateContent([prompt, ...imageParts]);
const response = await result.response;
const text = response.text();
// console.log(text);
answerElm.insertAdjacentHTML('afterbegin', `<p>${text}</p>`);
answerElm.classList.add('OnView');
inputElm.value = '';
fileElm.value = '';
geminiLoading.classList.remove('OnView');
} else {
geminiLoading.classList.remove('OnView');
answerElm.insertAdjacentHTML('afterbegin', '<p>プロンプトの入力または、画像を投稿してください</p>');
answerElm.classList.add('OnView');
}
}
/* ------------- 処理実行イベントハンドラ ------------- */
formElm.addEventListener('submit', (e) => {
e.preventDefault();
run(inputElm.value.length, inputElm.value);
});
HTML
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Gemini-tutorial-multiModal</title>
<link rel="stylesheet" href="./style.css">
<script type="importmap">
{
"imports": {
"@google/generative-ai": "https://esm.run/@google/generative-ai"
}
}
</script>
<script type="module" defer src="./gemini-multiModal.js"></script>
</head>
<body>
<section>
<form id="runForm">
<input type="text">
<button id="submitBtn">run</button>
<input type="file" accept="image/png, image/jpeg, image/jpg">
</form>
<p class="geminiLoading">Gemini が解答を用意しています。</p>
<div class="answer"></div>
</section>
</body>
</html>
CSS
@charset "utf-8";
* {
box-sizing: border-box;
}
#runForm {
width: clamp(320px, calc(100vw/2), 960px);
margin: 0 auto 1em;
padding: 1em;
background-color: #e9e9e9;
border-radius: 8px;
line-height: 2;
& input[type="text"] {
appearance: none;
border: 1px solid #333;
border-radius: 4px;
}
& button {
appearance: none;
border: 1px solid transparent;
background-color: orange;
color: #fff;
border-radius: 4px;
padding: .25em 1em;
}
}
.geminiLoading {
width: calc(100vw/2);
text-align: center;
margin: auto;
padding: 1em 2.5em;
box-shadow: 0 0 8px rgba(0, 0, 0, .25) inset;
border-radius: 8px;
display: none;
&.OnView {
display: block;
}
}
.answer {
width: clamp(320px, calc(100vw/2), 960px);
margin: auto;
line-height: 1.8;
padding: 1em;
background-color: #b3b3b3;
border-radius: 8px;
display: none;
& p {
margin: 0;
}
& img {
width: 100%;
height: auto;
}
&.OnView {
display: block;
}
}
@media screen and (min-width:1025px) {
section {
display: flex;
gap: 2%;
align-items: flex-start;
& #runForm {
margin-bottom: 0;
}
}
}
Geminiは画像内のコードについても説明してくれました。
ところどころGeminiの説明が間違っているのですが、これは筆者がそれまでに何度も似たような質問をしていたせいかもしれません。とはいえ、このようなことはGeminiのみならず、Chat-GPTなど他の生成AIでもありそうですね。
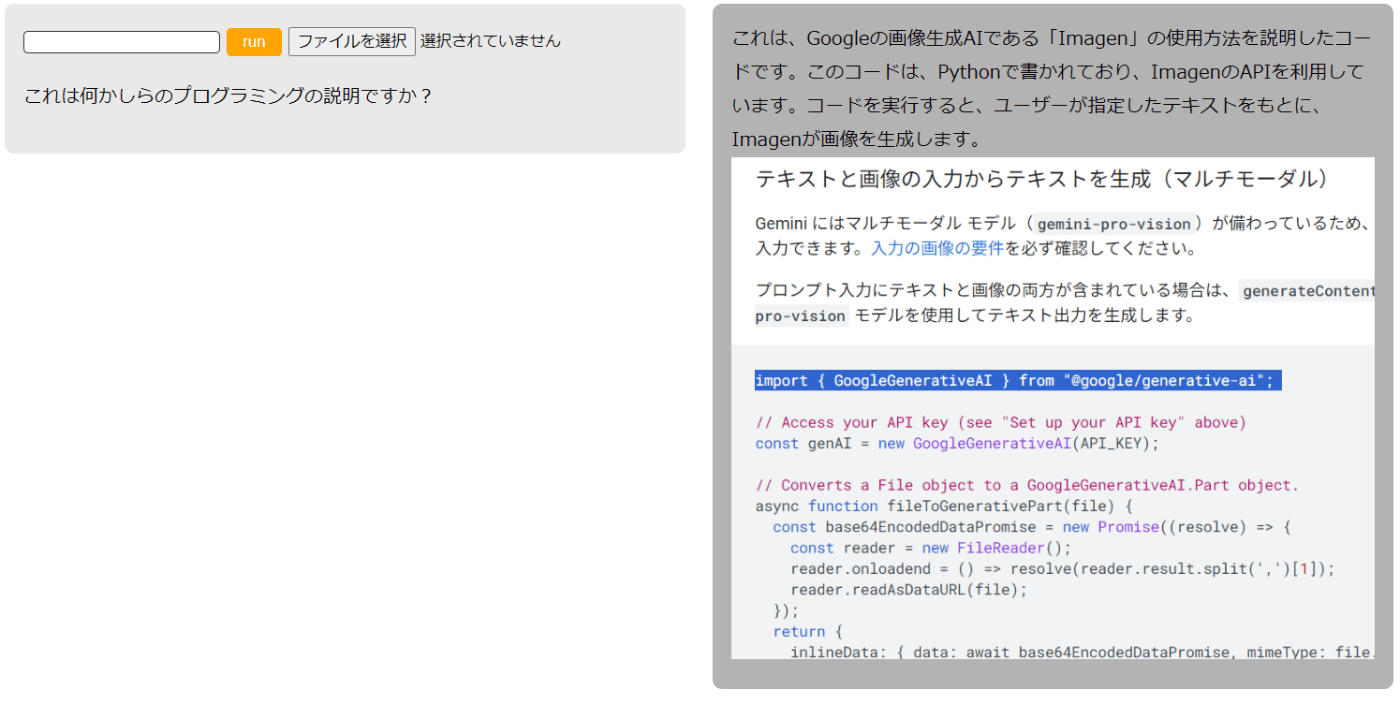
上記に掲載したJavaScriptコードの下記部分を(ご自身で発行したGeminiのAPI_KEYに)書き換えるだけで利用できると思います。
.
..
// Fetch your API_KEY
const API_KEY = "YOUR_API_KEY_STRING";
..
.
API_KEYの取得
まず上記のサイトにアクセスしGet API key in Google AI Studioをクリックします。

次に、開いたページの左上にあるGet API Keyをクリックして、
Create API Key in new projectを引き続きクリックすると自身のGeminiのAPI_KEYが発行されます。

さいごに
ここまで読んでいただき、ありがとうございました。
気が向いたら上記のコードをReactで書き換えてみようかなとか思っています。
Geminiの無料利用は2024年の初旬までと言われているので気になる方は早めに試してみてください!
参照情報
Discussion