はじめに
こんにちは。BEENOSのがれっとです。
E2Eテストのメンテナンス、うまくできていますか?
E2Eテストはその性質上、アプリケーションのUI変更や仕様変更に影響を受けやすく、テストコードの頻繁な修正が必要となり、メンテナンスコストが高いという課題があります。
私たちの持つサービス、「Groobee」は、サイトのデザインや構造を柔軟にカスタマイズできる点が特徴です。ユーザー自身でUIを変更可能なため、DOM要素に依存する従来のE2Eテストは、これらの変更によって頻繁に動作しなくなります。それによる維持管理コストの高さが課題となっていました。
そこで、今年(2025年)3月に登場したPlaywright MCPを使い、LLMを活用した自然言語でのE2Eテストを実験してみました。
Playwright MCPとは
ブラウザを自動操作するためのツールであるPlaywrightをMCPサーバーとして立ち上げ、LLMがブラウザを操作できるようにしたものです。
これにより、ユーザーが自然言語でLLMに指示を出すことで、ブラウザを操作できるようになります。
構成
今回構築したE2Eテストシステムの全体像は、以下の構成図の通りです。

- GitHub Actions
- GitHubをトリガーとしてLambdaを起動
- 結果をPRコメントに投稿
- Lambda
- Playwright MCPを実行
- LLMに自然言語での指示を出し、ブラウザを操作
- 結果をGitHub Actionsに返却
- S3
- テスト内容のテキストを保存
- 実行結果のスクリーンショットを保存
- OpenAI
- 自然言語での指示を受け取り、Playwright MCPを用いてテストを実行
- Application
- 今回はサンプルのため、簡単なTodoアプリケーションを用意
また、Playwrightを実行するために、コンテナイメージのLambdaを作成しています。
アプリケーションの実装
Pythonスクリプト
先に全体像を示します。その後、各部分について説明します。
class OutputResult(BaseModel):
output_text: str
test_result: bool
async def main() -> dict[str, object]:
test_id = str(uuid7())
model = "gpt-4.1-mini"
query = get_text_from_s3("test001.txt")
output_text = ""
log_text = ""
async with MCPServerStdio(
params={
"command": "npm",
"args": ["run", "mcp", "--", "--executable-path", get_chromium_executable_path()],
}
) as server:
agent = Agent(
name="Assistant",
model=model,
tools=[get_environment_variable],
output_type=OutputResult,
mcp_servers=[server],
)
result = await Runner.run(
agent,
query,
max_turns=50,
)
image_filenames = upload_images_s3(dir_name=test_id)
log_text = ""
for i in result.new_items:
if isinstance(i, ToolCallItem) and isinstance(
i.raw_item, ResponseFunctionToolCall
):
log_text += f"{i.raw_item.name}({i.raw_item.arguments})\n"
return {
"test_id": test_id,
"start_time": start_time.isoformat(),
"end_time": end_time.isoformat(),
"elapsed_sec": (end_time - start_time).seconds,
"output_text": result.final_output.output_text,
"log_text": log_text,
"result": result.final_output.test_result,
"bucket_name": os.getenv("BUCKET_NAME", ""),
"image_filenames": image_filenames,
}
def get_chromium_executable_path() -> str:
base_path_str = "/opt/.cache/ms-playwright/"
chromium_dir = next(iter(Path(base_path_str).glob("chromium-*")))
return chromium_dir.joinpath("chrome-linux", "chrome").as_posix()
def lambda_handler(event, context) -> dict[str, object]:
return asyncio.run(main())
if __name__ == "__main__":
# ローカル環境でのテスト用
asyncio.run(main())
ローカル・Lambda環境での実行
ローカル環境でLambdaを実行するために環境構築するのは手間なので、今回は簡易的にpython main.pyを実行することでLambdaを実行できるようにしています。
これにより、Lambdaやローカルのみで行う処理を分けることができるという副次的なメリットもあります。
def lambda_handler(event, context) -> dict[str, object]:
return asyncio.run(main())
if __name__ == "__main__":
# ローカル環境でのテスト用
asyncio.run(main())
MCPServerの実行
npm runコマンドでMCPServerを実行します。
公式ドキュメントではnpxコマンドで実行しています。その場合初回は実行時にインストールが必要です。今回はDockerイメージのnode_modulesにPlaywright MCPを含めたため、npm runコマンドを使用しています。
--executable-pathオプションで、Playwrightが使用するChromiumのパスを指定します。ChromiumのバージョンがDockerイメージのビルドタイミングで変わる可能性があるため、プログラムから取得するようにしています。
async with MCPServerStdio(
params={
"command": "npm",
"args": ["run", "mcp", "--", "--executable-path", get_chromium_executable_path()],
}
) as server:
# 省略
def get_chromium_executable_path() -> str:
base_path_str = "/opt/.cache/ms-playwright/"
chromium_dir = next(iter(Path(base_path_str).glob("chromium-*")))
return chromium_dir.joinpath("chrome-linux", "chrome").as_posix()
Agentの実行
今回のモデルはgpt-4.1-miniを使用しています。選定理由は、OpenAIの公開しているモデルのうち、コンテキストウィンドウとTPMが大きく、API Limitsに引っかかりにくいからです。
toolsとしては、環境変数を取得するためのget_environment_variable関数を指定しています。出力としてtest_resultをbool型で取得することにより、後続の処理を分岐できるようにしています。
class OutputResult(BaseModel):
output_text: str
test_result: bool
model = "gpt-4.1-mini"
agent = Agent(
name="Assistant",
model=model,
tools=[get_environment_variable],
output_type=OutputResult,
mcp_servers=[server],
)
result = await Runner.run(
agent,
query,
max_turns=50,
)
toolsにおいてLLMが環境変数を取得するための関数get_environment_variableを宣言し、環境変数をシナリオのテキストへ含めないようにします。
@function_tool
def get_environment_variable(variable_name: AllowedVariables) -> str:
"""
Retrieves the value of a predefined environment variable.
Args: The name of the environment variable to retrieve.
Returns:
str:
The value of the specified environment variable.
Example:
>>> get_environment_variable("USERNAME")
'test_user'
"""
if variable_name not in get_args(AllowedVariables):
raise InvalidEnvironmentVariableNameError(variable_name)
value = os.environ.get(variable_name)
if value is None:
raise KeyError()
return value
Agentのログを取得
この部分ではAgentが実行したtoolのログを取得しています。
これをLambdaの返り値とすることで、GitHub ActionsのPRコメントに投稿します。
for i in result.new_items:
if isinstance(i, ToolCallItem) and isinstance(
i.raw_item, ResponseFunctionToolCall
):
log_text += f"{i.raw_item.name}({i.raw_item.arguments})\n"
package.json
Playwright MCPのpackage.jsonには、binコマンドとしてmcp-server-playwrightが定義されています。そのため、"@playwright/mcp"をインストールすることで、mcp-server-playwrightとしてPlaywright MCPを実行できます。
また、lambdaで実行するオプションを指定するため、configファイルを指定しています。
{
"scripts": {
"mcp": "mcp-server-playwright --config ./playwright.config.json"
},
"dependencies": {
"@playwright/mcp": "^0.0.25"
},
"engines": {
"node": ">=22.0.0"
}
}
playwright.config.json
主にLambdaで実行するためのオプションを指定しています。
Playwright MCPがスクリーンショットにより画像を取得した場合、デフォルトでは画像をBase64エンコードしてLLMに渡します。
今回のケースでは画像をLLMに渡す必要がないため、noImageResponsesをtrueにすることで、画像をレスポンス内へ含めないようにしています。これにより、LLMのトークン数を削減できます。
{
"browser": {
"browserName": "chromium",
"launchOptions": {
"headless": true,
"args": [
"--single-process",
"--no-sandbox",
"--disable-gpu",
"--disable-dev-shm-usage",
"--no-zygote"
]
}
},
"noImageResponses": true
}
Dockerfile
ベースイメージとしては、python:3.13を使用しています。
Playwright MCPとその依存ライブラリ、chromium等はnode:slimを使用してインストールし、そのファイルを実行イメージにコピーしています。
fontをインストールしないと日本語が豆腐になるため、注意してください。
前提として、以下のようなディレクトリ構成でファイルが配置されていることを想定しています。
.
├── Dockerfile
├── app
│ ├── main.py
│ ├── requirements.txt
│ ├── package.json
│ ├── package-lock.json
│ └── playwright.config.json
└── testCases # Dockerイメージには含めない(S3に保存)
├── test01.txt
├── test02.txt
└── ...
# Playwright MCPのインストール
FROM node:slim AS node
WORKDIR /playwright/app
RUN npx -y playwright install --with-deps chromium
COPY app/package.json app/package-lock.json ./
RUN npm ci
# Python実行環境の構築
FROM python:3.13 AS base
WORKDIR /playwright
RUN apt-get update && apt-get install -y curl gnupg wget fonts-noto && \
curl -fsSL https://deb.nodesource.com/setup_22.x | bash - && \
apt-get install -y nodejs && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
# playwrightと依存ライブラリのコピー
COPY /root/.cache/ms-playwright/ /opt/.cache/ms-playwright/
COPY /usr/lib /usr/lib
COPY /lib /lib
COPY /playwright/app/node_modules /playwright/app/node_modules
FROM base AS prd
WORKDIR /playwright/app
COPY app/requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt awslambdaric
COPY app/playwright.config.json app/package.json app/main.py ./
ENTRYPOINT [ "python", "-m", "awslambdaric" ]
CMD [ "main.lambda_handler" ]
Lambdaの設定
このアプリケーションはホームディレクトリ(Lambdaでは/home/sbx_userXXXX)にログファイル等を出力します。
コンテナイメージのLambdaは/tmp以外の書き込みができずエラーになってしまうため、環境変数HOMEを/tmpに設定し、このエラーを回避します。
筆者の環境では、メモリは750MBほど使用していたため、メモリサイズは1024MBを指定しています。
Lambdaのタイムアウトは、シナリオの長さに応じて適宜変更してください。
resource "aws_lambda_function" "playwright_app" {
function_name = "playwright-mcp-app"
package_type = "Image"
image_uri = "${aws_ecr_repository.playwright_app.repository_url}:latest"
role = aws_iam_role.playwright_mcp_app_lambda_role.arn
memory_size = 1024
timeout = 60
architectures = ["arm64"]
environment {
variables = {
HOME = "/tmp"
}
}
depends_on = [
aws_ecr_repository.playwright_app,
aws_iam_role_policy_attachment.lambda_basic_execution,
]
}
GitHub Actionsの設定
GitHub Actionsは下記の流れで実行されます。
- PRコメント
/testでトリガー - PRにある最新のコミットのステータスを
pendingに更新 - Lambdaを実行、 その結果を取得
- 結果に応じてPRにある最新のコミットのステータスを
successまたはfailureに更新 - E2EテストのスクリーンショットをS3からダウンロード
- PRに結果のコメントを投稿
OIDCを使用してAWS認証をします。このとき付与されたロールでLabmdaの実行とS3オブジェクトに対する読み取り権限があることを確認してください。
また、スクリーンショット画像はリリースファイルに含めることで、リポジトリに権限を持っている人のみがアクセスできるようにしています。
全体のworkflowファイルは以下のようになります。
name: invoke-e2e-test
on:
issue_comment:
types: [created]
env:
AWS_DEFAULT_REGION: ap-northeast-1
FUNCTION_NAME: your-lambda-function-name
BUCKET_NAME: your-bucket-name
CONTEXT: "e2e-test-result"
jobs:
test:
if: github.event.issue.pull_request && contains(github.event.comment.body, '/test')
runs-on: ubuntu-latest
permissions:
id-token: write
contents: write
pull-requests: write
statuses: write
steps:
- name: 🛎️ Checkout repository
uses: actions/checkout@v4
- name: Get PR Head SHA
id: pr_head
env:
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
PR_NUMBER: ${{ github.event.issue.number }}
run: |
# gh CLI を使ってPRの最新コミットSHAを取得
HEAD_SHA=$(gh pr view $PR_NUMBER --json headRefOid -q '.headRefOid')
echo "HEAD_SHA=${HEAD_SHA}" >> $GITHUB_OUTPUT
if [ -z "$HEAD_SHA" ]; then
echo "Error: Could not get HEAD SHA for PR #$PR_NUMBER"
exit 1
fi
- name: 💭 Update commit status to pending
env:
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
OWNER: ${{ github.repository_owner }}
REPO: ${{ github.event.repository.name }}
SHA: ${{ steps.pr_head.outputs.HEAD_SHA }}
run: |
gh api \
--method POST \
-H "Accept: application/vnd.github+json" \
"/repos/$OWNER/$REPO/statuses/$SHA" \
-f state="pending" \
-f target_url="${{ github.server_url }}/${{ github.repository }}/actions/runs/${{ github.run_id }}" \
-f description="E2E test in progress" \
-f context="$CONTEXT"
- name: 🔐 Configure AWS credentials
id: configure-aws-credentials
uses: aws-actions/configure-aws-credentials@v4
with:
aws-region: "ap-northeast-1"
role-to-assume: ${{ secrets.AWS_OIDC_INVOKE_ROLE_ARN }}
- name: 💥 Invoke the Lambda
id: execute-lambda
shell: bash
run: |
response=$(
aws lambda invoke \
--function-name "$FUNCTION_NAME" \
--cli-binary-format raw-in-base64-out \
/dev/stdout \
| jq -s
)
escaped=$(echo "$response" | jq -c '.')
echo "res=${escaped}" >> "$GITHUB_OUTPUT"
- name: 💡 Update commit status for result
env:
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
OWNER: ${{ github.repository_owner }}
REPO: ${{ github.event.repository.name }}
SHA: ${{ steps.pr_head.outputs.HEAD_SHA }}
run: |
DECODED='${{ steps.execute-lambda.outputs.res }}'
RESULT=$(echo "$DECODED" | jq -r '.[0].result')
if [[ "$RESULT" == "true" ]]; then
STATE="success"
DESCRIPTION="E2E test passed"
else
STATE="failure"
DESCRIPTION="E2E test failed"
fi
gh api \
--method POST \
-H "Accept: application/vnd.github+json" \
"/repos/$OWNER/$REPO/statuses/$SHA" \
-f state="$STATE" \
-f target_url="${{ github.server_url }}/${{ github.repository }}/actions/runs/${{ github.run_id }}" \
-f description="$DESCRIPTION" \
-f context="$CONTEXT"
- name: 📦 Download test screenshots
run: |
DECODED='${{ steps.execute-lambda.outputs.res }}'
DIR_NAME=$(echo "$DECODED" | jq -r '.[0].test_id')
mkdir -p ./playwright/testResults/
aws s3 sync s3://$BUCKET_NAME/images/$DIR_NAME/ ./playwright/testResults/
- name: 🚀 Upload to GitHub Releases
id: create-release
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
SHA: ${{ steps.pr_head.outputs.HEAD_SHA }}
run: |
RELEASE_TAG="result-$SHA-images"
gh release create $RELEASE_TAG --notes "Test Result Image Upload"
gh release upload $RELEASE_TAG ./playwright/testResults/* --clobber
echo "RELEASE_TAG=${RELEASE_TAG}" >> $GITHUB_OUTPUT
- name: 💬 Comment image paths
uses: actions/github-script@v7
env:
RAW_OUTPUT: ${{ steps.execute-lambda.outputs.res }}
RELEASE_TAG: ${{ steps.create-release.outputs.RELEASE_TAG }}
OWNER: ${{ github.repository_owner }}
REPOSITORY: ${{ github.event.repository.name }}
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
script: |
const script = require('./.github/scripts/commentToPr.js');
await script({github, context});
- name: 🧪 Check the result
shell: bash
run: |
set -euo pipefail
raw_output='${{ steps.execute-lambda.outputs.res }}'
echo "$raw_output" | jq -e '.[0].result == true' > /dev/null || {
echo "❌ Lambda test failed"
exit 1
}
echo "✅ Lambda test passed"
GitHub ActionsのPRコメント
PRに対して結果をコメントするgithub-scriptは下記のように実装しています。
const parseTime = (isoString) => {
const d = new Date(isoString)
const f = (opt) => new Intl.DateTimeFormat('default', { timeZone: 'Asia/Tokyo', ...opt }).format(d);
return `${f({month:'numeric'})}月${f({day:'numeric'})}日 ${f({hour:'numeric', hour12:false})}時${f({minute:'numeric'})}分${f({second:'numeric'})}秒`;
}
module.exports = async ({github, context}) => {
const lambdaOutput = JSON.parse(process.env.RAW_OUTPUT);
const images = lambdaOutput[0]?.image_filenames ?? [];
const image_path = `https://github.com/${process.env.OWNER}/${process.env.REPOSITORY}/releases/download/${process.env.RELEASE_TAG}`
if (images.length === 0) {
console.log("📭 No images found to comment.");
return;
}
const body = [
"## 🧪 自動テストの結果\n",
`|項目|内容|`,
`|:-:|:-:|`,
`|テスト実行結果|${lambdaOutput[0]?.result ? "✅ 成功🎉" : "❌ 失敗😭"}|`,
`|開始時間|${parseTime(lambdaOutput[0]?.start_time)}|`,
`|終了時間|${parseTime(lambdaOutput[0]?.end_time)}|`,
`|テスト実行時間|${lambdaOutput[0]?.elapsed_sec}秒|`,
"### 🎭 実行ログ\n",
"<details>\n",
"<summary>Playwright実行ログ</summary>\n",
"```bash\n",
`${lambdaOutput[0]?.log_text}\n`,
"```\n",
"</details>\n",
"## 📝 テストレポート\n",
`${lambdaOutput[0]?.output_text}\n`,
"## 📸 自動テストのスクショ\n",
images
.flatMap((image, i, arr) => {
const content = ``
return i < arr.length - 1 ? [content, "\n---\n"] :[content];
})
].join("\n");
await github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number,
body,
});
console.log("✅ Comment posted successfully.");
};
プロンプト内容
今回はテスト用の簡単なTODOアプリケーションを用意しました。
アプリケーションの挙動は変えず、成功・失敗の2パターンのシナリオを用意し、CIの挙動を確認しました。
成功シナリオ
あなたはアプリの動作確認を行うテスターです。完全に指示通りに動作するか確認してください。
指示にないタイミングで異なるアクションを行わないでください。
すべて正常にテストが終了した場合は、resultをTrueとして出力してください。
1つでも異常があった場合は直ちにテストを中断し、resultをFalseとして出力してください。
スクリーンショットを取得する場合は、`browser_take_screenshot`を使用し、圧縮しない形式で保存してください。
テスト対象の要件は以下の通りです。1つでも満たさない場合はNGとしてください。
- TODOアイテムを追加することができる。
- TODOアイテムを削除することができる。
- TODOアイテムのチェックボックスの状態を変更することができる。
`TARGET_URL`をtoolsから取得して該当URLにアクセスし、下記動作を上から順に確認してください。
1. TODOアイテムを追加すると、画面上にTODOアイテムが表示されること。
2. 追加したアイテムの内容が、1で入力したテキストと一致すること。
3. チェックボックスをクリックし、input要素の状態が変わること。
4. 画面全体のスクリーンショットを取得してください。
5. 削除ボタンを押すと、1で追加されたアイテムが画面上から消えること。
最後に、`output_result`を用いて実行結果を出力してください。
失敗シナリオ
画面再読み込みによるアイテムの状態保持は実装していないため、このシナリオは失敗します。
あなたはアプリの動作確認を行うテスターです。完全に指示通りに動作するか確認してください。
指示にないタイミングで異なるアクションを行わないでください。
すべて正常にテストが終了した場合は、resultをTrueとして出力してください。
1つでも異常があった場合は直ちにテストを中断し、resultをFalseとして出力してください。
スクリーンショットを取得する場合は、`browser_take_screenshot`を使用し、圧縮しない形式で保存してください。
テスト対象の要件は以下の通りです。1つでも満たさない場合はNGとしてください。
- TODOアイテムを追加することができる。
- TODOアイテムを削除することができる。
- TODOアイテムのチェックボックスの状態を変更することができる。
- リロードしてもTODOアイテムの状態が保持できる。
`TARGET_URL`をtoolsから取得して該当URLにアクセスし、下記動作を上から順に確認してください。
1. TODOアイテムを追加すると、画面上にTODOアイテムが表示されること。
2. 追加したアイテムの内容が、1で入力したテキストと一致すること。
3. チェックボックスをクリックし、input要素の状態が変わること。
4. 画面全体のスクリーンショットを取得してください。
5. リロードを行い、アイテムの状況が保持されていること。
6. 削除ボタンを押すと、1で追加されたアイテムが画面上から消えること。
最後に、`output_result`を用いて実行結果を出力してください。
実行結果
テストの実行に成功した場合、PRに以下のようなコメントが投稿されます。
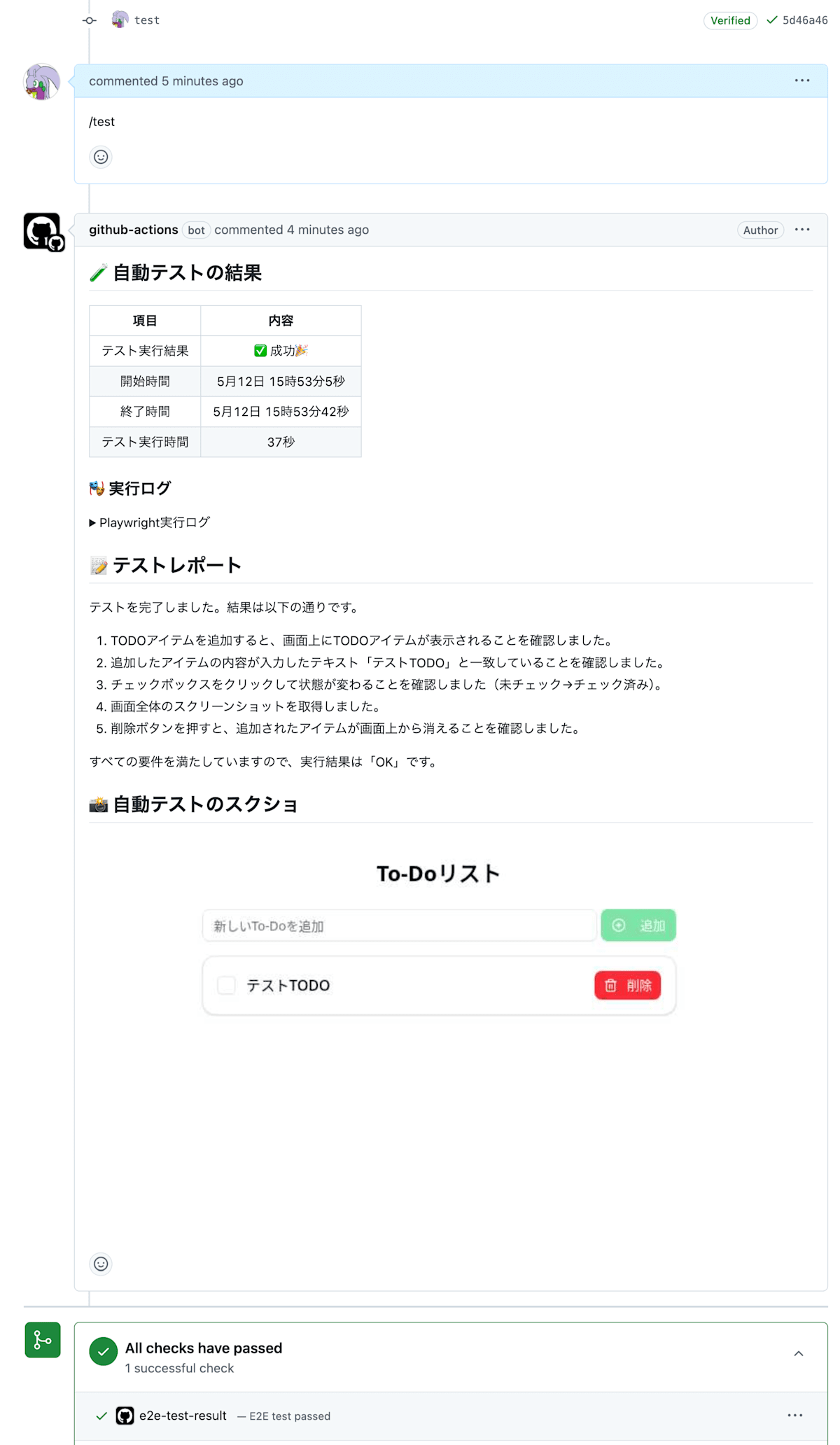
よく見るとチェック済みにした状態でスクリーンショットを取得しているはずなのに、スクリーンショットではチェックされていない状態になっています。
ログを確認してみると、checkboxのクリックとスクリーンショットの取得の順番が逆になっていました。

スクリーンショットがあると、このようなハルシネーションに気付きやすくなります。
またLLMがE2Eテストの実行に失敗した場合は、CIの結果が失敗となります。

まとめ
今話題のPlaywright MCPを使って、自然言語でE2Eテストを実行する方法を紹介しました。
LLMを活用することで、E2Eテストのメンテナンスコストを削減できる可能性があると考えています。
実運用はこれからですが、E2Eテストの保守性向上と効率化に向けて、引き続き改善を進めていく予定です。
Wanted!
BEENOSグループでは一緒に働いて頂けるエンジニアを強く求めております!
少し気になった方は、社内の様子や大事にしていることなどをThe BEENOSにて発信しておりますので、是非ご覧ください。
とても気になった方はこちらでも求人を公開しておりますので、お気軽にご応募ください!
「自分に該当する職種がないな…?」と思った方はオープンポジションとしてご応募頂けると大変嬉しいです 🙌
世界で戦えるサービスを創っていきたい方、ぜひご連絡ください!よろしくお願いいたします!


BEENOSグループのTech Blogです。 BEENOSは越境ECを主要事業として、その他関連/新規事業を行っています。 このTech Blogでは、グループ内の各事業を推進する過程で得られた技術的知見を発信していきます。
Discussion