初めまして、BEENOSの田之上です!
執筆時点で新卒4年目となり、段々と若手扱いされなくなってきたことにやや寂しさを感じている今日この頃です🥺
今回は、弊社で運用しているとある大規模webサービス(ユーザ30万人、DBテーブル数1,000以上)のデータパージを実施しようとしてみましたので、そのレポートになります。
...タイトルにもある通り未実施なので、実施後に改めて加筆修正予定です!
※以前サノ氏が取り上げていたこちらのシステムと同じ
データパージとは
文字通りデータをパージ(消去、浄化)することで、今回で言うとDBの不要なデータを削除する意味になります。
目的
サービスを運用開始して2年半近くになることもあり、DBに不要なデータが溜まり続けています。
不要なデータが溜まり続けると、
- DBの処理速度の低下
- インフラ費用が余計にかかる
などが発生する可能性があり、喫緊の課題という訳ではないですが、早いに越したことはないので今回実装するに至りました。
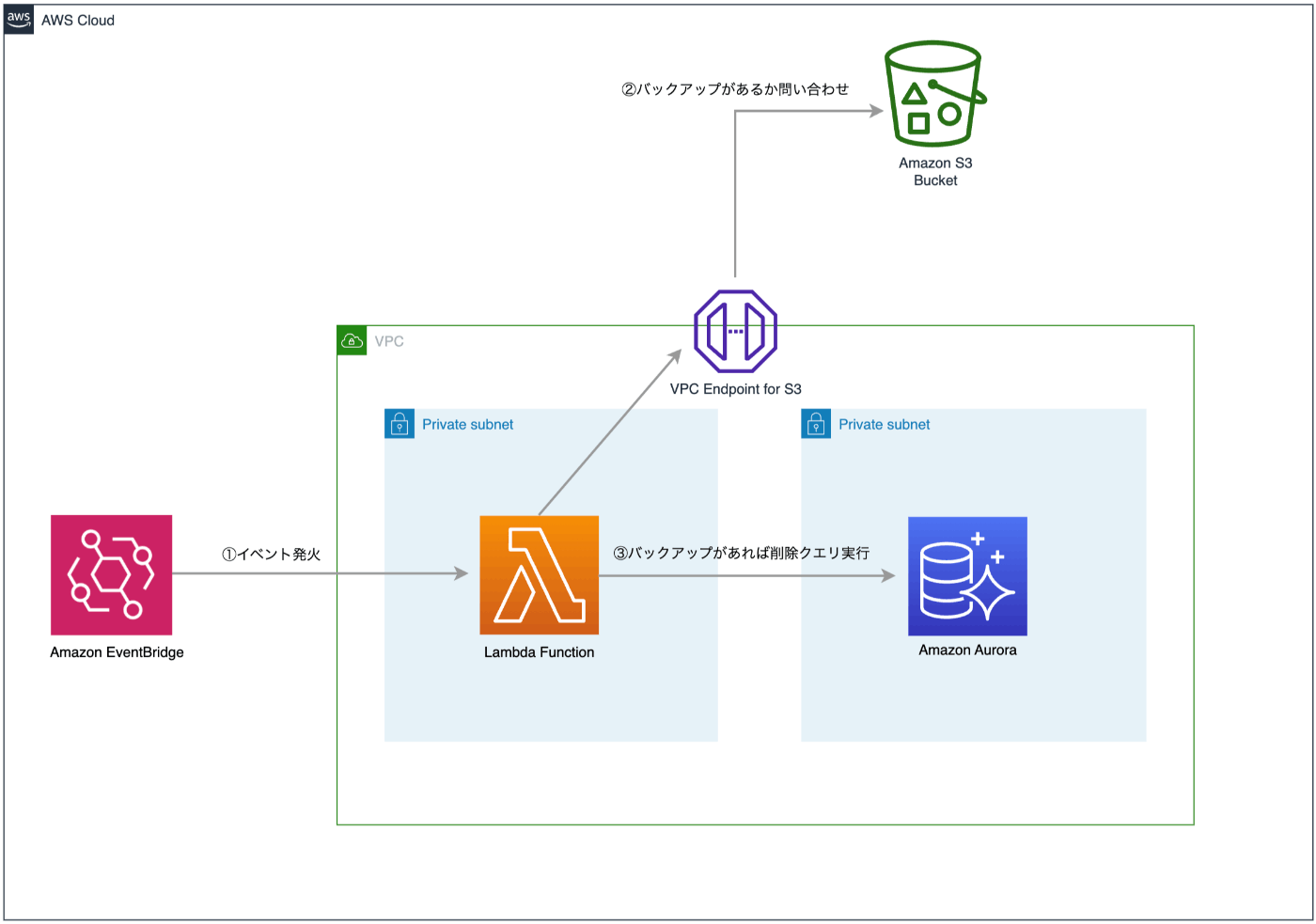
設計
厳密には異なりますが以下が概略図です。
言語
ロジック
上図の通り、Amazon EventBridgeとAWS Lambdaの組み合わせで、バックアップの存在を担保しつつ、削除クエリを定期的に実行するというシンプルなものです。
※バックアップについては既に別システムにて実装済み
また、削除対象のテーブルは、以下のように削除タイミングをグループ分けすることで、トラブル発生時の調査ができるようにしました。
やはり決済関連は気を使いますよね😅
- 削除対象
- 全件
- 決済以外の外部サービスとの通信情報
- 有効期限切れのトークン
- 1日前
- ゲストユーザー関連
- 未ログイン状態における商品閲覧やカートイン等の履歴情報
- ゲストユーザー関連
- 30日前
- 各種履歴テーブル
- 本システムでは各レコードの変更履歴を追うため、ほぼ全テーブルに履歴テーブルを紐づけている
- 各種履歴テーブル
- 半年前
- 決済関連の外部サービスとの通信情報
- 全件
補足
バックアップ方法
実は当初の設計では、「DBのDump結果をS3に正常に送ってから対象テーブルのデータを削除する」というものでしたが、以下の理由で本システムとは切り離し、別の方法で実装しました。
このあたりやや複雑なので、機会があれば別記事としてご紹介できればと思ってます。
- 全体の処理時間がLambdaの規定実行時間(15分)を超える
- DBへの負荷が大きくなりすぎて、障害発生のリスクがある
削除タイミングをグループ分け
どう設計するか迷いましたが、各グループごとに削除対象のテーブルを列挙したjsonファイルを作成する方法にしました。
これらのjsonテキストを各EventBridgeスケジュールのペイロードに定義して、Lambdaにて読み込むイメージですね。
こうすることで、別のグループに対象テーブルを移動もしくは追加したい場合でも、アプリ側のロジックに影響を与えずに変更ができる利点があります!
例:1日前の削除グループ
{
"deleteType": "1day",
"description": "データパージ実行時から1日前以上のデータ削除テーブル一覧",
"tables": [
"guests",
"guest_carts"
// ...
]
}
削除実装コード一部抜粋(jsonのdeleteTypeをもとに条件分岐)
func (repo databaseRecordRepository) Delete() {
switch true {
case repo.targetFileInfo.IsAllDeleteType():
repo.deleteAllRecords()
case repo.targetFileInfo.Is1DayDeleteType():
repo.deleteOverDaysRecords(1)
case repo.targetFileInfo.Is30DaysDeleteType():
repo.deleteOverDaysRecords(30)
case repo.targetFileInfo.IsHalfAYearDeleteType():
repo.deleteOverDaysRecords(183)
default:
panic("Invalid delete type: " + repo.targetFileInfo.GetDeleteType())
}
}
実装
アプリケーションコード
Lambdaの特性上、どうしても手続き型の記述になりがちですよね...😅
本プロダクトでは手動DIを実装してパッケージの責務を分けることで、オブジェクト指向型になるように意識しました。
全て列挙すると膨大なので、メインのパッケージのみ以下に記載します。
- Connection層
- dbConnection(クレデンシャル情報を基にDBへ接続する)
- ConnectionInterfaceを継承
- dbConnection(クレデンシャル情報を基にDBへ接続する)
- Repository層
- s3StorageRepository(S3へオブジェクトの検索、アップロード等を行う)
- StorageRepositoryInterfaceを継承
- databaseRecordRepository(各種DBレコードに関する処理、主に削除を行う)
- DB接続用としてConnectionInterfaceに依存
- RecordRepositoryInterfaceを継承
- s3StorageRepository(S3へオブジェクトの検索、アップロード等を行う)
- Service層
- DataPurgeService(メインサービスとして以下のサービスを呼び出し)
- BackupService
- StorageRepositoryInterfaceに依存
- DatabaseRecordDeleteService
- RecordRepositoryInterfaceに依存
- BackupService
- DataPurgeService(メインサービスとして以下のサービスを呼び出し)
各パッケージ(構造体)がInterfaceを参照することで、先述の通り依存性の少ないコードにできています。
また、dbConnectionパッケージを作ることでDB接続用のクレデンシャル情報を隠蔽しました。
SAMの構築
個人的にSAMの実装は初めてだったのですが、インフラ担当の方に手解きを受けなんとか完成させることができました。
ありきたりですが、今までマネコンでやっていた手作業をコマンド1つ集約できたり、特に検証環境が複数ある本システムならではの環境ごとにデプロイがしやすかったり等、たくさんのありがたみを感じられました✨
※template.yamlのResources部分の抜粋(一部改変済)
Resources:
SecretsManager:
Type: AWS::SecretsManager::Secret
Properties:
Name: !Sub ${Stage}-for-data-purge-lambda-function
Description: データパージ用の環境変数
SecretString:
!Sub '{
"HOST":"",
"PORT": "",
"USERNAME": "",
"PASSWORD": "",
"DB_NAME": "",
"SNAPSHOT_BUCKET_NAME": "${Stage}-rds-snapshot-data",
"AWS_S3_REGION": "ap-northeast-1"}'
Tags:
- { Key: created_by, Value: SAM } # SAMで作られたことを明記
DataPurgeFunction:
Type: AWS::Serverless::Function
Properties:
MemorySize: 256
FunctionName: !Sub ${Stage}-data-purge-function
CodeUri: ./
Handler: main
Timeout: 100
Runtime: provided.al2 # Amazon Linux 2 ベース
Architectures: [arm64] # arm64(Graviton2) 指定
Environment:
Variables:
SECRET_NAME: !Sub ${Stage}-for-data-purge-lambda-function
env: !Sub ${Stage}
VpcConfig:
SecurityGroupIds:
- !FindInMap [EnvMap, !Ref Stage, SecurityGroupId]
SubnetIds:
- !FindInMap [EnvMap, !Ref Stage, SubnetId]
Events:
AllDeleteListSchedule:
Type: ScheduleV2
Properties:
Name: !Sub ${Stage}-data-purge-all-schedule
ScheduleExpression: !FindInMap [EnvMap, !Ref Stage, CronFormat]
ScheduleExpressionTimezone: "Asia/Tokyo"
Input: "略"
Over1DayDeleteListSchedule:
Type: ScheduleV2
Properties:
Name: !Sub ${Stage}-data-purge-over-1-day-schedule
ScheduleExpression: !FindInMap [EnvMap, !Ref Stage, CronFormat]
ScheduleExpressionTimezone: "Asia/Tokyo"
Input: "略"
Over30DaysDeleteListSchedule:
Type: ScheduleV2
Properties:
Name: !Sub ${Stage}-data-purge-over-30-days-schedule
ScheduleExpression: !FindInMap [EnvMap, !Ref Stage, CronFormat]
ScheduleExpressionTimezone: "Asia/Tokyo"
Input: "略"
OverHalfAYearDeleteListSchedule:
Type: ScheduleV2
Properties:
Name: !Sub ${Stage}-data-purge-over-half-a-year-schedule
ScheduleExpression: !FindInMap [EnvMap, !Ref Stage, CronFormat]
ScheduleExpressionTimezone: "Asia/Tokyo"
Input: "略"
Policies:
- "略"
Metadata:
BuildMethod: makefile # go build の設定ファイル
DataPurgeLogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub /aws/lambda/${DataPurgeFunction}
RetentionInDays: 3
記事執筆時点だと、通常の設定ではarm64アーキテクチャでGoは動かせなかったので、以下の記事を参考にカスタムランタイムを用いて実行させました🙇♂
まとめ
今回の経験を通じて、インフラ周りの知識が得られたのはもちろん、インフラ構成やアプリコードの設計にも気を遣い、さらにこれまでほとんど経験のなかったGoを使ってシステムを作り上げたことでエンジニアとして大きく成長できた気がします!
...このようにやり切った感を出していますが未実施なので、実施後に改めて得られた効果(主に費用面や速度面)や課題点等が見つかれば加筆していきます💪
Wanted!!
BEENOSグループでは一緒に働いて頂けるエンジニアを強く求めております!
少し気になった方は、社内の様子や大事にしていることなどをThe BEENOSにて発信しておりますので、是非ご覧ください。
とても気になった方はこちらで求人も公開しておりますので、お気軽にご応募ください!
「自分に該当する職種がないな...?」と思った方はオープンポジションとしてご応募頂けると大変嬉しく思います 🙌
世界で戦えるサービスを創っていきたい方、是非是非ご連絡ください!よろしくお願い致します!!


BEENOSグループのTech Blogです。 BEENOSは越境ECを主要事業として、その他関連/新規事業を行っています。 このTech Blogでは、グループ内の各事業を推進する過程で得られた技術的知見を発信していきます。
Discussion