Mac で RAG による最新情報の LLM を構築してみた



Mac で RAG による最新情報の LLM を構築してみた
はじめに
様々な企業が、AI 活用を視野に入れ始めて、取組みを良く見かけるようになり、Large Language Models (LLMs/LLM) も業務で活用される事例も増えております。そして、AI とデータを柔軟に管理してツールやプロセス、コストパフォーマンス、スケーラブルをバランス良くするための手法である MLOps や 、MLOps と GenAIOps を LLM 基準で開発と運用に考慮した LLMOps 、Retrieval-augmented generation (RAG) の配信と運用を考慮した RAGOps も登場しております。そこで、LLM を特定の情報で回答できるようになる RAG を構築してました。
Large language Models (LLMs/LLM: 大規模言語モデル) とは
Large language Models (LLMs/LLM: 大規模言語モデル) とは、大規模なデータセットを使用してコンテンツを認識、要約、翻訳、予測、生成できる Deep Learning のアルゴリズムのモデルです。Transformer Model を使い、連続したデータの関係性のパターンを判断して文脈と意味を教師なし学習する Neural Networks です。
こちらが参考になります。
Retrieval-Augmented Generation (RAG: 検索により強化した生成) とは
Retrieval-Augmented Generation (RAG: 検索により強化した生成) とは、外部のデータからドキュメントを検索して、大規模言語モデル(LLM)に情報を追加するにより、LLM の生成プロセスに個別の情報を組み込むフレームワークです。RAG により、個別の情報に特化したり、精度と信頼性させ、Hallucination (ハルシネーション) を抑制することもできます。
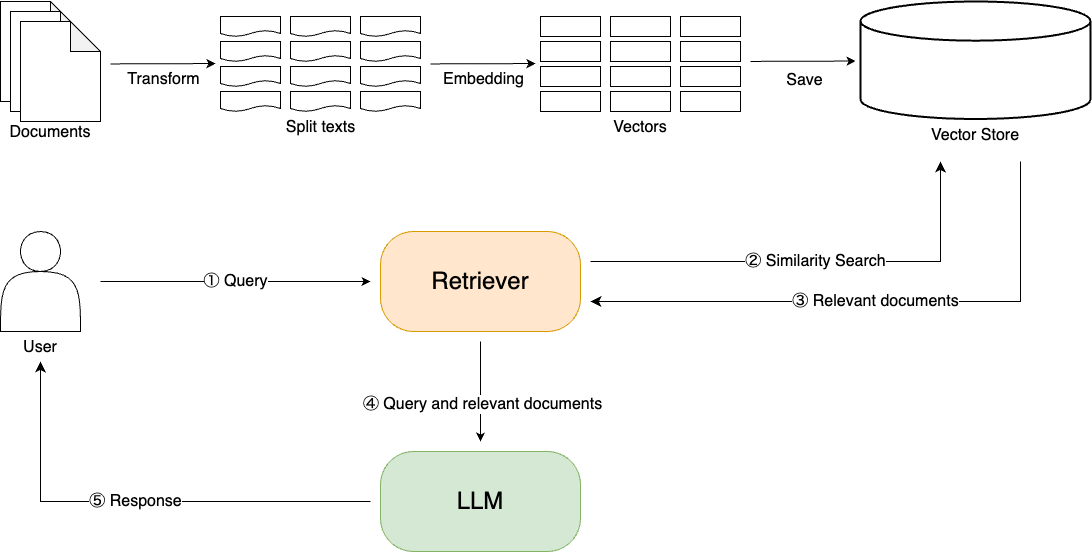
RAG Flow Image
こちらが参考になります。
実行環境
今回の構築した環境を以下に記載します。
Hardware
MacBook Pro を使用しています。
- CPU: Apple M3 Pro (Arm)
- Memory: 36 GB
- OS: Sonoma 14.2.1
Software
Python を使用しています。
LangChain
LangChain とは、言語モデルを利用したアプリケーション開発向けのフレームワークです。
Embeddings
Embeddings とは、コンテンツを、関係性の測定するため、高次元ベクトルに変換することです。
HuggingFaceEmbeddingsを使用します。
Faiss
Faiss とは、密ベクトルの効率的な類似検索を提供するライブラリです。
JupyterLab
JupyterLabとは、ウェブベースでインタラクティブな開発環境を提供するインターフェースです。本記事の Python コードは、JupyterLab の Notebook から実行しています。
Model
学習済みの Model をダウンロードできるサイトは、huggingface です。
そして、LLaMAを日本語向けに強化して開発したモデル ELYZA-japanese-Llama-2-13b-fast-instruct を利用しています。
今回は、GGUF形式のモデルを使用するために こちら から 8-bit integer で量子化した Model をダウンロードします。
モデルは、modelディレクトリに格納します。
mkdir model
cd model
モデルのダウンロードします。
wget https://huggingface.co/mmnga/ELYZA-japanese-Llama-2-13b-fast-instruct-gguf/resolve/main/ELYZA-japanese-Llama-2-13b-fast-instruct-q8_0.gguf
cd ..
試験データ
今回は、CSVのデータを使用します。
データは、data ディレクトリに格納します。
mkdir data
cd data
こちらの csv ファイルを用意します。
順位, 竣工年, ビル名, 高さ(m), 所在地, 国名
1, 2027, トーチタワー, 390, 東京都千代田区, 日本
2, 2023, 麻布台ヒルズ森JPタワー, 325.40, 東京都港区, 日本
3, 2014, あべのハルカス, 300, 大阪市阿倍野区, 日本
4, 1993, 横浜ランドマークタワー, 296, 横浜市西区, 日本
5, 2023, 虎ノ門ヒルズ ステーションタワー, 265.75, 東京都港区, 日本
cat << 'EOF' > building.csv
順位, 竣工年, ビル名, 高さ(m), 所在地, 国名
1, 2027, トーチタワー, 390, 東京都千代田区, 日本
2, 2023, 麻布台ヒルズ森JPタワー, 325.40, 東京都港区, 日本
3, 2014, あべのハルカス, 300, 大阪市阿倍野区, 日本
4, 1993, 横浜ランドマークタワー, 296, 横浜市西区, 日本
5, 2023, 虎ノ門ヒルズ ステーションタワー, 265.75, 東京都港区, 日本
EOF
cd ..
ディレクトリ構成
ディレクトリ構成はこちらです。
❯ tree
├── data
│ └── building.csv
├── llm-rag-ex01.ipynb
├── model
│ └── ELYZA-japanese-Llama-2-13b-fast-instruct-q8_0.gguf
└── vectorstore
└── ex01
├── index.faiss
└── index.pkl
Python コード
JupyterLab の Notebook から実行しています。
Python の library は、適宜追加してください。
LLM のみの回答
コードはこちらです。
from gpt4all import GPT4All as GPTTest
# Model select
model = GPTTest(model_name='ELYZA-japanese-Llama-2-13b-fast-instruct-q8_0.gguf', model_path='model')
# Chat
with model.chat_session():
response1 = model.generate(prompt='日本で1番高いのビルは?', temp=0)
print(model.current_chat_session)
出力はこちらです。
日本の一番高いタワーである、634mのスカイツリーと回答してます。
[{'role': 'system', 'content': ''}, {'role': 'user', 'content': '日本で1番高いのビルは?'}, {'role': 'assistant', 'content': '日本の一番高いビルは、634mある東京スカイツリーです。'}]
RAG を使用した回答
コードはこちらです。
import の内容はこちらです。
from langchain.document_loaders import DirectoryLoader, CSVLoader
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores.faiss import FAISS
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.llms.gpt4all import GPT4All
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
ドキュメントを読み込みます。
# Document Loaders
loader = DirectoryLoader(path="data", loader_cls=CSVLoader, glob='*.csv')
raw_docs = loader.load()
ドキュメントを分割します。
今回は、1行ごとに分割します。
# Document Transformers
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 100, chunk_overlap = 0)
docs = text_splitter.split_documents(raw_docs)
分割したドキュメントをベクトル化します。
# Embedding
embeddings = HuggingFaceEmbeddings()
faiss_db = FAISS.from_documents(documents=docs, embedding=embeddings)
ベクトル化をVector Storeに格納します。
# Vector Store
faiss_db.save_local(FAISS_DB_PATH + FAISS_DB_DIR)
ベクトルの類似度でドキュメントを取得できるか確認します。
query は、「日本1番のビルは?」です。
# Retrievers
retriever = faiss_db.as_retriever()
query = "日本1番のビルは?"
context_docs = retriever.get_relevant_documents(query)
print(f"len={len(context_docs)}")
first_doc = context_docs[0]
print(f"metadata={first_doc.metadata}")
print(first_doc.page_content)
4個のドキュメントが格納されていることがわかり、1番目はトーチタワーのドキュメントです。
len=4
metadata={'source': 'data/building.csv', 'row': 0}
順位: 1
竣工年: 2027
ビル名: トーチタワー
高さ(m): 390
所在地: 東京都千代田区
国名: 日本
質問を「日本1番のビルは?」として、テンプレートを作成します。
PROMPT = '日本1番のビルは?'
template = """Answer the question based only on the following context:
{context}
Question: {question}
Answer in the following language: Japanese
"""
RAG より Vector から類似度検索を行います。
embedding_vector = embeddings.embed_query(PROMPT)
contexts = faiss_db.similarity_search_by_vector(embedding_vector)
context = "\n".join([document.page_content for document in contexts])
callbacks = [StreamingStdOutCallbackHandler()]
LLM のモデルとプロンプトを指定します。
llm = GPT4All(model='model/ELYZA-japanese-Llama-2-13b-fast-instruct-q8_0.gguf', callbacks=callbacks, verbose=True)
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
LLM を起動します。
response = llm_chain.run(PROMPT)
回答は、期待通り、RAG により格納した「トーチタワー」になりました。
回答: トーチタワー
次に、2番目に高いビルを理由も踏まえて聞いてみます。
PROMPT = '日本2番のビルは?'
template = """Answer the question based only on the following context:
{context}
Question: {question}
Answer: Let's think step by step.
"""
embedding_vector = embeddings.embed_query(PROMPT)
contexts = faiss_db.similarity_search_by_vector(embedding_vector)
context = "\n".join([document.page_content for document in contexts])
callbacks = [StreamingStdOutCallbackHandler()]
llm = GPT4All(model='model/ELYZA-japanese-Llama-2-13b-fast-instruct-q8_0.gguf', callbacks=callbacks, verbose=True)
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
response = llm_chain.run(PROMPT)
出力は
1. 日本で一番高いビルはどこにあるか考えます。答えは、トーチタワーです。
2. 次いで高いビルの順位を考えてみましょう。位置情報から、順に高さが高いビルから並んでいることがわかります。したがって、2番目は300mの高さのあべのハルカスとなります。
3. 日本2番のビルは、2位になるため、トーチタワーよりも高さが低いビルであることが分かります。そして、2位のビルは高さ265.75 mなので、1位と2位は入れ替わります。よって、日本で一番高いビルはトーチタワーで、2番目は虎ノ門ヒルズ ステーションタワーとなります。
したがって、日本2番のビルは、「虎ノ門ヒルズ ステーションタワー」です。
所感
本記事は、RAG による LLM を特定の情報を入力して、どのような回答が得られるかを確認しました。簡単なテストデータでは、ある程度、精度の高い回答は得られるが、理由までを出力すると不正確な情報になります。Fine-tuning では、LLMの精度向上にはなるが、複数の個別ユーザに対応したい場合は、RAG が有効的であるので、RAG の精度を向上のため、ドキュメントの内容を充実するように追加していきたい。そして、どのようなドキュメントが良いのかは検証したいです。
Discussion