クローズドLLM (GPT, Gemini, Claude, etc.)からの知識蒸留 [論文より]
はじめに
LLMって、どうやって知識蒸留(Knowledge Distillation: KD)するんだろう、ふと疑問に思いました。
arXivを探してたところ、サーベイ論文を発見したので読んでみました。
そのメモを残していきます。
調査のきっかけ
LLMをKDしようと思ったときに、2パターンあると思います。
- Open Source(Open Weight)モデルから蒸留する場合
- Closed Source (Proprietary)モデルから蒸留する場合
[2]によると、1の場合はAttention行列を模倣することがよくあるそうです。Attension行列には文法に基づいた注意パターンを表しており、それを真似することで効果的に暗黙知(dark knowledge)を学習できるとのこと。
確かにオープンソースであれば好きな箇所の出力を取得することができるので、特徴蒸留もできますし、たしかにうまくいきそうな感じがします。
では、2の場合はどうでしょう。Closed Sourceモデル(GPT-4、Claude、Geminiなど)からKDする場合、Open Sourceモデルとは大きく異なるアプローチが必要になります。前述のようにオープンソースモデルではAttention行列などの内部表現にアクセスできますが、独自モデルではそれらの内部状態にアクセスできないため、別の戦略が求められます。
単純に考えると、Closed Sourceモデルに与えたInputとそのOutputを元に、生徒モデルを学習させることになります(それしかできなさそうですね)。
果たして、その方法はうまくいくのでしょうか?
論文[1]を調査し、どのような方法があるのか調べてみました。
論文[1]の調査結果
1. イントロダクション(モチベーション)
[1]の1. INTRODUCTIONの内容です。
Closed Sourceモデルには、アクセス制限と高コスト、そしてデータプライバシーとセキュリティの観点での懸念という欠点がある。
対象的に、Open Sourceモデルは、制限や(インフラがあれば)コストの支払いなしに使用できるのに加えて、AI研究の促進にも貢献する。
しかし、性能的にはどうしてもClosed Sourceモデル > Open Sourceモデルとなっているのが現実である。この性能格差を埋める手段として知識蒸留(KD)の手法の研究が進んでいる。

KDはLLMにおいて3つの重要な役割を果たす([1]のFigure 1)。
①性能の向上
②効率性のための規模圧縮(compression)
③自己生成知識(self-generated knowledge)による自己改善(Self-Improvement)
論文[1]によると、一連の蒸留技術を通じて、Closed SourceモデルとOpen Sourceモデルの間のギャップは、大幅に狭まっているとのことです。
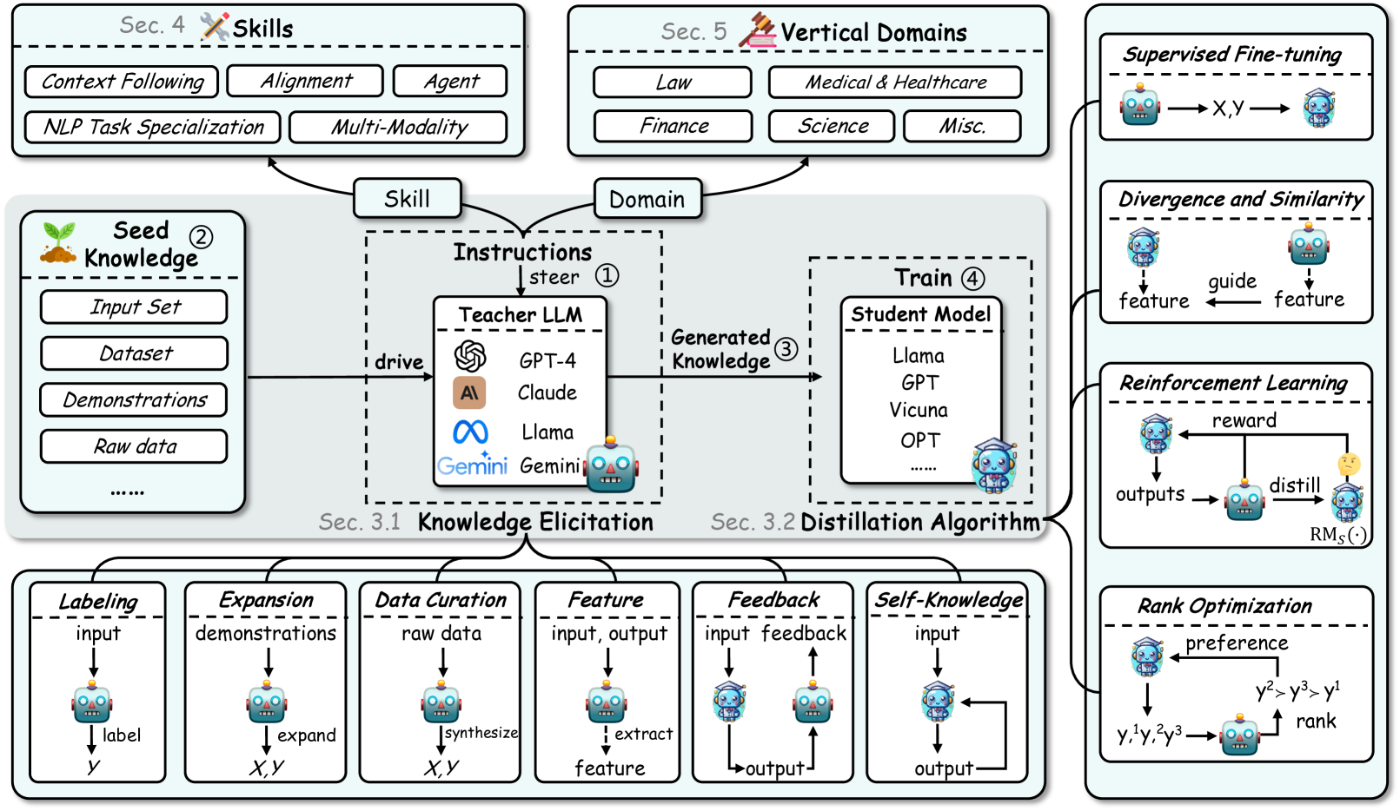
[1]のFigure 2には本論文における調査の構成と、LLMにおけるKDのステップ①→②→③→④が示されています。
本記事では、2章の知識蒸留の概要、3章の知識を引き出す手法(Knowledge Elicitation)と蒸留アルゴリズム(Distillation Algorithm)についてまとめたいと思います。
知識蒸留の概要
[1]の2. OVERVIEWの内容です。
従来の蒸留から、LLMの蒸留へ
AI分野における蒸留とは、大規模で複雑なモデル(教師モデル)から、小規模で効率的なモデル(生徒モデル)へ知識を転移するプロセスを指していた。
しかしLLMの出現により状況は変わりました。GPT-4やGeminiなどのClosed Sourceモデルには、我々はパラメータにアクセスできないためで、プルーニングや量子化を使用して圧縮することが困難です。そこで、知識蒸留の目的としては、単なるアーキテクチャの圧縮から知識の引き出しと転移と、焦点をシフトしていったそうです。
この「知識を引き出し転移する」アプローチの鍵は、プロンプトです。プロンプトは、自然言語理解から推論や課題解決などのより複雑な認知タスクまで、様々な領域におけるLLMの理解と能力を活用するように設計されます。この工夫により、特定のスキルや関心領域に焦点を当てた、より的を絞った知識の抽出を可能にしているそうです。
Data Augmentation (DA)
DAは、LLMの知識蒸留において必要不可欠な要素になりつつあるそうです。
従来はparaphrasing (ある1データの意味とできるだけ同じになるように、新たなデータを作成する手法)やback-translation (元のテキストを他の言語に翻訳し、その翻訳したテキストを再び元の言語に翻訳することで、新たなデータを生成する方法)などの手法で、機械的にデータを拡張していました。
しかし、LLMのコンテキストにおけるDAは、特定のドメインやスキルに合わせた新しいコンテキストリッチなトレーニングデータの生成に焦点を当てています。
LLM時代の蒸留パイプライン
強い教師モデルから、より単純な生徒モデルへ知識を転移することを目的としたプロセスを紹介します。このパイプラインは、GPT-4やGeminiなどのClosed Sourceモデルの高度な能力を、よりアクセスしやすく効率的なOpen Sourceモデルの対応物で活用するために不可欠です。このパイプラインの概要は、知識蒸留において重要な役割を果たす4つの明確な段階に大きく分類できます([1]のFigure 4)。
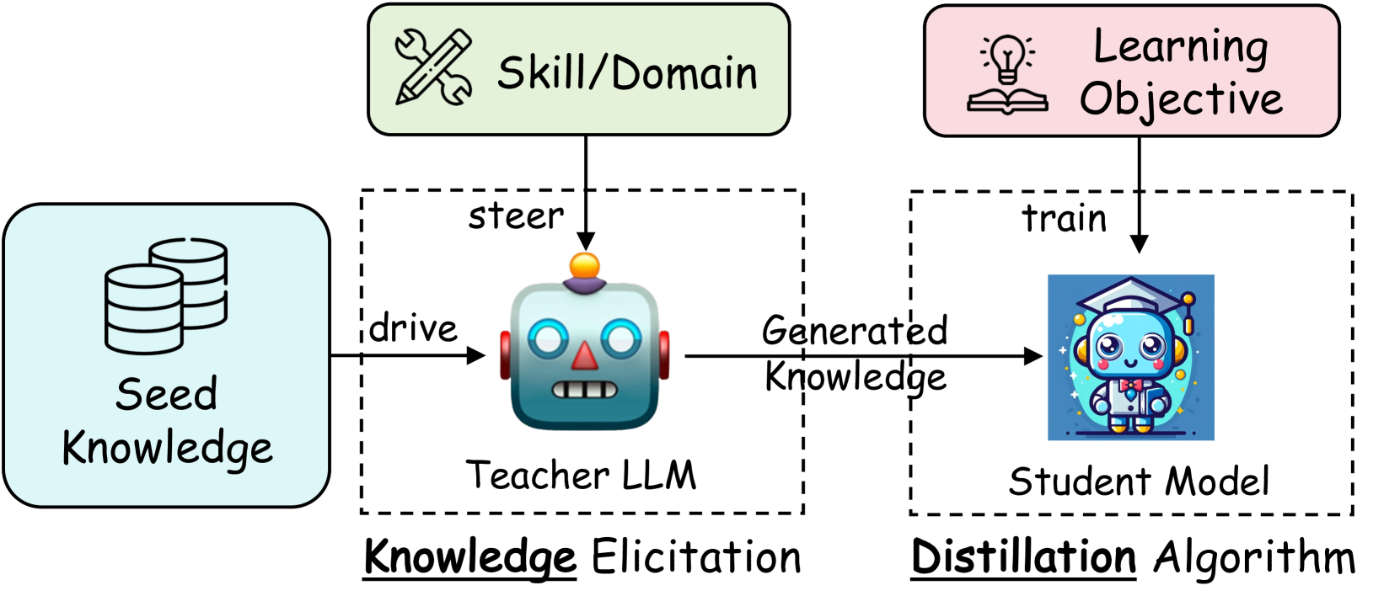
-
ターゲットのスキル/ドメインに基づく、教師LLMのステアリング
教師LLMの出力を、特定のターゲットスキルまたはドメインに向けるために指示を出す。例えば、システムプロンプトなどで実行される。 -
インプットとしてのシード知識を収集
教師LLM提供するためのシード知識(特定の分野やスキルに関連する基本的な情報や初期データセット)を収集する。 -
蒸留知識の生成
ステアリングとシード知識に応じて、教師LLMに知識例を生成させる。これらの例は主にQA対話形式や語り口調の説明形式となる。 -
特定の学習目標を持つ生徒モデルのトレーニング
生成された知識例を使用して生徒モデルをトレーニングする。このトレーニングには学習目標に合わせた損失関数が定義され、損失関数を最小化することで学習する。
上記の1~4のステージは、下記の2式に定式化できますね。
ここで、
上記の式は、言葉で書くと、シード知識郡
次に損失関数です。
ここで、
本論文では、LLM時代に目立った特定の蒸留について紹介するそうです。

上記([1]のFigure 5)は、教師LLMからの知識の引き出し方を表しています(詳しくは次の章で説明されます)。
- Labeling: 教師モデルが入力から出力を生成する
- Expansion: 教師モデルが文脈内学習を通じて、与えられた例示に似たサンプルを生成する
- Data Curation: 教師モデルがトピックやエンティティなどのメタ情報に基づいてデータを合成する
- Feature: データを教師モデルに入力し、ロジットや特徴などの内部知識を抽出する (抽出できる場合に限る)
- Feedback: 教師モデルが生徒モデルの生成に対して、好み、修正、難しいサンプルの拡張などのフィードバックを提供する
- Self-Knowledge: 生徒モデルが最初に出力を生成し、それが高品質のものにフィルタリングされるか、生徒モデル自身によって評価される
知識を引き出す手法
[1]の3.1. Knowledgeの手法です。
Labeling

Labelingとは、教師LLMを使用して、インストラクション
最もシンプルな割に効果的で、広く適用されているそうです。
数式もシンプルですね。
指示
Expansion

Labelingのアプローチは、入力データが多様性を持つものでないと、うまくはたらきません。この制約に対処するために、様々な拡張方法が提案されています。大まかな流れは、デモンストレーション
ExpansionはLLMのコンテキスト内学習の強みを活用して、入力と出力の両方を持つより多様で広範なデータセットを生成します。ただし、生成されたデータの品質と多様性は、教師LLMと初期シード知識に大きく依存するという問題点があります。このことは、教師LLMから固有のバイアスを持つデータセットが生成されやすくなったり、アウトプット
Data Curation

Data Curationは、LabelingとExpansionの課題である、多様性の確保を解決するために考案されました。
Data Curationは、トピックや知識ポイントなどの多様なメタ情報
このメタ情報には何を使うのか、は研究によって異なるそうです。
1つは、広範なメタ情報を使用する方法です。例えば「テクノロジー」や「食べ物と飲み物」などの30のメタトピックを使用して、幅広い指示と会話を蒸留しています。
もう一方はいわゆる「教科書」のような高品質で小規模なデータセットでの蒸留に焦点を当てています。こちらは例えばコーディングドメインを学習するときに用いられ、Pythonであれば、蒸留されるデータは10億トークンのPython教科書および解答付きの1億8千万トークンのPython演習という量にのぼります。これを使用したモデルは、HumanEvalやMBPPなどのコーディングベンチマークでほぼすべてのオープンソースモデルを上回るパフォーマンスを発揮したそうです。
このようにData Curationは、高品質で多様かつ大規模なデータセットを合成するための有望な技術とされています。
Feature

これまでの手法と異なり、こちらはホワイトボックスモデルに対してのみ行える蒸留方法です。そのためGPTやGeminiなどには適用できません。
この手法は特に小さなモデルで有望性を示しますが、ブラックボックスモデルでは使用できません。さらに、ホワイトボックスな教師モデルよりもブラックボックスの教師モデル(例:GPT-4)がより強力な傾向にあるため、ブラックボックスの同等モデルと比較して性能が劣る可能性があります。
Feedback
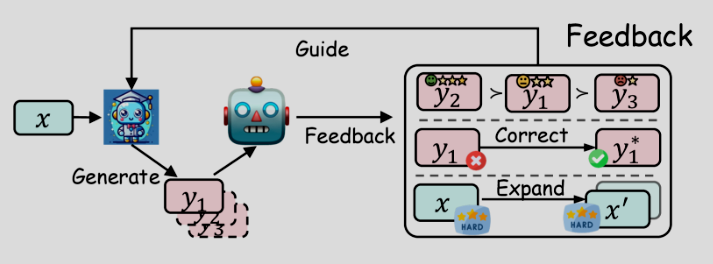
これまでのパイプラインは、主に教師モデルから生徒モデルへの一方向の知識伝達に焦点を当てており、生徒モデルの生成物に対する教師モデルからのフィードバックを考慮していませんでした。教師モデルからのフィードバックは通常、生徒モデルが生成した出力に対する選好、評価、または修正情報を提供することで行われます。例えば、一般的なフィードバック形式として、教師モデルが生徒モデルの生成物をランク付けし、この選好をAIフィードバックからの強化学習(Reinforcement Learning from AI Feedback: RLAIF)を通じて生徒モデルに蒸留することが挙げられます。
ここで、
選好のほかにも、生徒モデルの生成物を単に評価するだけでなく、教師モデルは生徒モデルが不十分な部分に対して広範なフィードバックを提供する手法も存在するそうです。
Self-Knowledge

Self-Knowledgeとは、生徒モデル自信から引き出した知識のことです。同じモデルが教師と生徒の両方の役割を果たし、以前に生成した出力を蒸留・改良することで自身を反復的に改善します。この方法では、GPTのような外部の強力な教師モデル(多くの場合はClosed Sourceモデル)の必要性を独自に回避します。
ここで、
蒸留アルゴリズム
Supervised Fine-Tuning: SFT
SFTは、ブラックボックスLLMを蒸留するための最もシンプルかつ効果的な方法の1つです。SFTは教師モデルによって生成されたシーケンスの尤度を最大化することで生徒モデルをFine-Tuningし、生徒モデルの予測を教師の予測に合わせます。
損失関数は下記となります。
ここで
Divergence and Similarity
ここでの手法は、主にホワイトボックスである教師モデルから特徴蒸留をするためのアルゴリズムです。これらは、大きく2グループに分類できます。
- 確率分布のDivergenceを最小化すること
- 隠れ層の類似性を高めること
確率分布のDivergenceの最小化
損失関数は下記で表されます。
隠れ層の類似性(Similarity)を高める
Similarity-basedの手法は、生徒モデルの隠れ状態または特徴マップを教師モデルのもとの整合させることを目的としています。
損失関数は下記となります。
ここで
類似性関数
現状、LLMの知識蒸留においては、Similarity-basedのものはかなり少ないようです。
強化学習
強化学習を用いて教師モデルから生徒モデルへ知識を蒸留する方法が紹介されています。
まずは報酬モデルの訓練です。これは、教師モデルによって作成されたフィードバックデータ
ここで、
↓
そうすれば
↓
そうすれば
↓
そうすれば
ということで、
報酬モデルができたら、それを用いて下記のように期待値を最大化します。
これは、訓練された報酬モデルに従って期待報酬を最大化するように最適化されます。ただし、それだけでは学習データに過学習してしまうので、同時に、
強化学習については、こちらでも解説しています。
ランク最適化
こちらは強化学習に変わる手法です。例えばDPOというものがあります。
DPOについては下記で解説していますので、そちらを参照ください。
さいごに
今回は"A Survey on Knowledge Distillation of Large Language Models"という論文の1~3章まで見て、いかにClosed Sourceモデルから(一部Open Sourceモデルから)知識を蒸留するかという手法を見てきました。
この論文には4~6章もありますので、機会があればぜひ読んでみたいと思います!
参考文献
[1] Xiaohan Xu, Ming Li, Chongyang Tao, Tao Shen, Reynold Cheng, Jinyang Li, Can Xu, Dacheng Tao, Tianyi Zhou "A Survey on Knowledge Distillation of Large Language Models" arXiv:2402.13116v4, 2024
[2] 佐藤竜馬. 深層ニューラルネットワークの高速化 (第5章). 技術評論社. 2022
[3] 岡谷貴之. 深層学習 改訂第2版 (10章). 講談社. 2022
Discussion