YOLOv12: Attentionベースのリアルタイム物体検出 [論文より]
はじめに
2025年2月、今までCNNベースで組まれていたYOLOが、ついにAttention機構中心になったということを知りました。
ちょうど今Vision Transformer (ViT)を勉強しており物体検出にも興味があったので、会社のゼミでの話題提供として、勉強メモを残します。
※ 個人の興味で載せているだけなので、誤った情報が載っている可能性があります。
※ メモなので、構成等気にせず書いているので雑です。
YOLOv12の論文、参考にした書籍は最後に載せてます。
YOLOv12
Attentionベースにするための課題
大前提、物体検出はリアルタイム(動画でも適用したい)ので、レイテンシが重要。そのため、効率的な計算が求められる。
例えば一般的なビデオのフレームレートである30 fpsであれば、最低でも約33ミリ秒で計算を終える必要があります。
Attentionは計算効率が悪く、その時間内に計算を終えるのが難しかった。
具体的には、トークン長
なお、今までのCNNだと
メモリのアクセスの効率もCNNより悪いそうです。
計算を効率的にするための特徴
Area Attensionの仕組みの導入
Vanilla Attentionの計算コストを落とすには、Linear Attensionというものを導入すればよい。
Linear Attensionは計算量を2乗のオーダーから、線形にする手法です。簡単に言えば、Attention行列を作成する際、query数
Linear Attentionについては下記記事が非常にわかりやすかったため、参照ください。
ただし、Linear Attentionは今回のYOLOv12はこのアプローチはとっていません。Linear Attentionにすると、Transformerの特徴である大域的特徴を捉える強みの敵かを招いたり、不安定になる、YOLOのケースだとそこまで計算量を削れないなど効果が限定的になるからです。
そこでYOLOv12では、Area Attentionという仕組みを採用しました。
Area Attentionは、特徴マップを複数の小さな領域(デフォルトで4つのサイズ領域)に分割し、各領域を独立して処理します。この方法には以下の特徴があります:
- 特徴マップを縦または横に等しい大きさの領域に分割(デフォルトは4)
- 複雑な演算を避けながらも大きな受容野を維持

[1]の図2より抜粋。一番右の図が、Area Attentionの分割方法
この方法で、精度はあまり落とさず、計算量を
論文では、
R-ELANの導入
Attentionを学ぶ文脈でYOLOのことを調べることにしたので、全く詳しくないのですが軽く記載してみます。
もともとYOLOシリーズでは、ELANという下記図の(b)構造が使われていたようです。
しかしELANには勾配ブロッキング、残差接続の欠如に加えて、Attention機構との相性の課題がありました。とくにYOLOv12-LとXサイズ(大きいサイズ)のモデルは、AdamやAdamWを使用しても、収束に失敗するか不安定状態になってしまうようでした。
それを、(d)のR-ELANにして解決したとのことです。
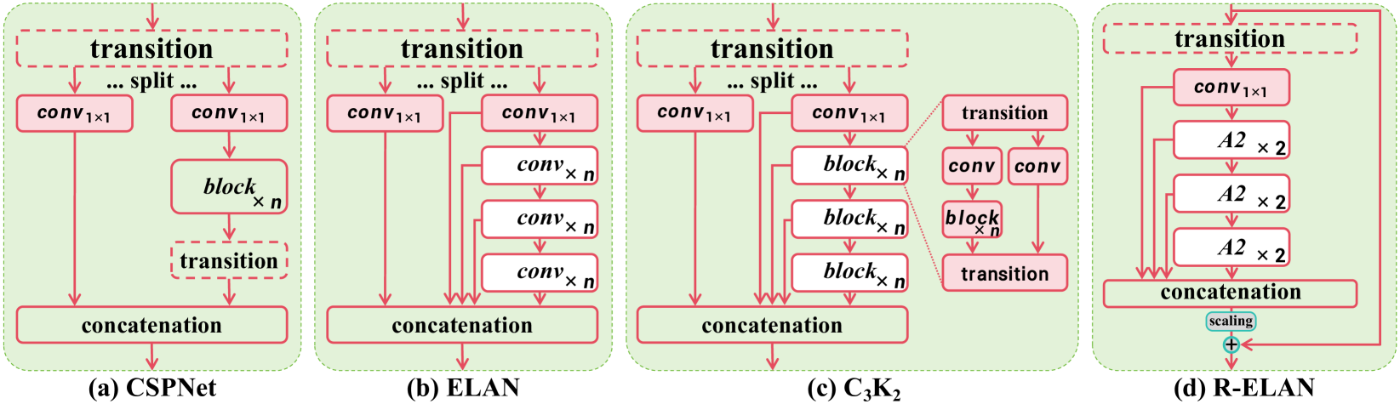
[1]の図3より抜粋。
YOLOv12の性能
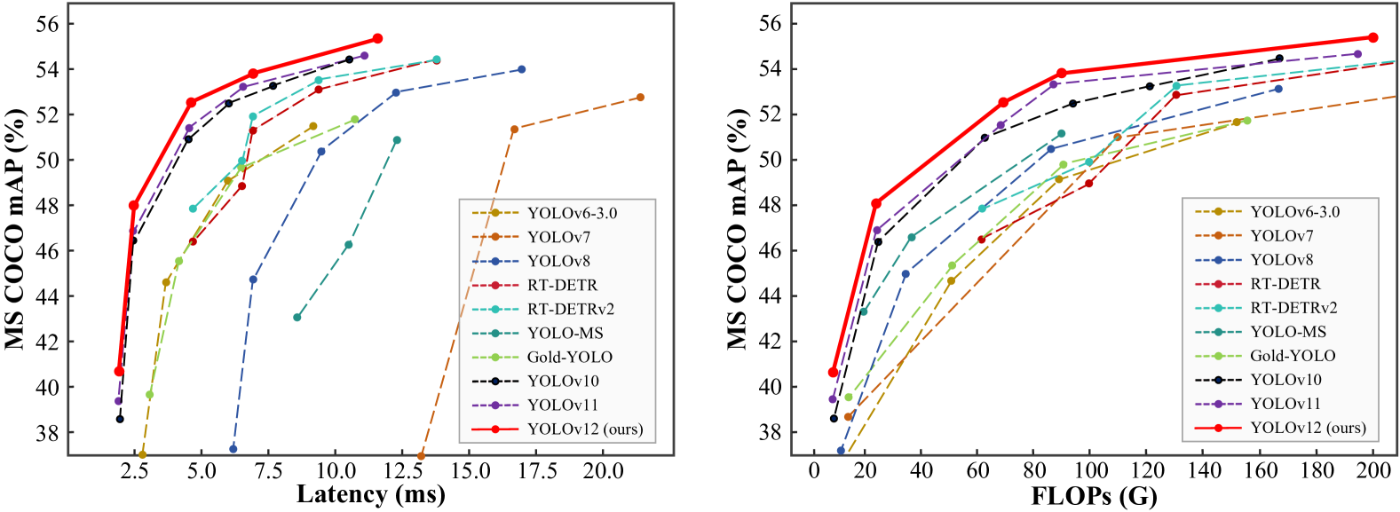
[1]の図1より抜粋
YOLOv12は、精度において人気のあるすべてのリアルタイム物体検出器を上回ると述べています。
実際に[1]の図1でもそれが見て取れます。
図の左の横軸はレイテンシー(処理時間: ms)、縦軸はMS COCOというデータセットにおける平均精度(%)を示しています。たしかに同水準のレイテンシーのモデルと比較すると、精度は1番高いことが見て取れますね。
図の右の横軸はFLOPsは、Floating Point Operationsの略で、アルゴリズムやAIモデルが実行する浮動小数点演算の総量を示す指標です。コンピュータの処理能力を図るFLOPSとは異なるので注意してください。縦軸は先ほどと同様の平均精度(%)になります。
こちらにおいても、同水準の計算量を持つモデルの中では精度がすべて上回ってますね。
というわけで、YOLOv12の論文を読んでみました!
YOLOv12を動かしてみた
ソースコードや結果は下記記事を参照ください!
Google Colabで動きます。
参考文献
[1] Yunjie Tian, Qixiang Ye, David Doermann "YOLOv12: Attention-Centric Real-Time Object Detectors" arXiv:2502.12524, 2025
[2] 片岡裕雄 監修,山本晋太郎,徳永匡臣,箕浦大晃,邱玥(QIU YUE),品川政太朗. Vision Transformer入門. 技術評論社. 2022
[3] 田村雅人, 中村克行. Pythonで学ぶ画像認識 機械学習実践シリーズ. インプレス. 2023
Discussion