選考チューニングのRLHFを数式ベースで理解する(報酬モデリング編)
大規模言語モデル入門および大規模言語モデル入門II出てくるRLHFについて、少し数式で詰まった部分があったので、メモがてら数式の意味を記載していこうと思います。
章番号や数式の番号は書籍のものなので、下記書籍を持ってないとなんのこっちゃだと思います。
対象は、4.5.1項および12.1.1項です。
報酬モデリングの数式
eq(12.1)
下記の式変形です。
シグモイド関数は、下記となるので、この形を目指していきます。
(手書きですみません)
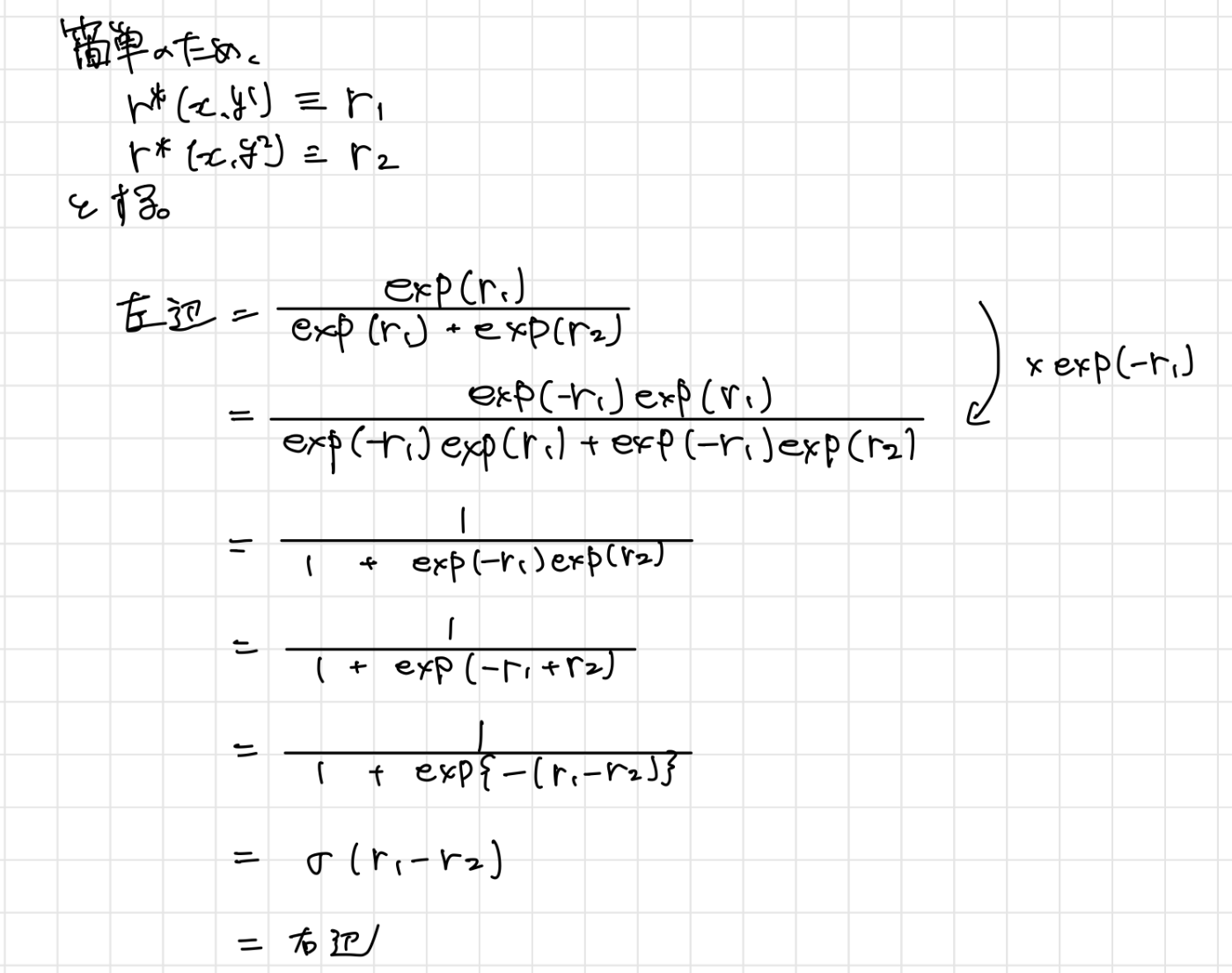
eq(4.2)およびeq(12.2)
多少の表記ゆれ(定義の違い)があるだけで同じものなので、eq(12.2)ベースでみていきます。
下記損失関数(12.2)を最小化するように学習させます。
ここで、
では、一つ一つ、どんな式なのか理解していきましょう。
こちらは簡単ですね。好ましい応答に対する報酬と好ましい応答に対する報酬の差です。
好ましい応答尾の報酬を大きくしたいため、
これにシグモイド関数を適用するとどうなるでしょう。
-
r_\theta(x, y^+) - r_\theta(x, y^-) \sigma(\cdot) -
r_\theta(x, y^+) - r_\theta(x, y^-) \sigma(\cdot)
さらに、これに
-
r_\theta(x, y^+) - r_\theta(x, y^-) \log \left( \sigma(\cdot) \right) -
r_\theta(x, y^+) - r_\theta(x, y^-) \log \left( \sigma(\cdot) \right) -\infty
となります。
つまり、
このようにしてチューニングされた報酬モデル
Discussion