🔤
方言翻訳機制作大作戦 その1
前回の続きです。
前回の記事
結論
及第点としました。理由は以下。
- 「ない」が「にゃ」「ねぇ」に変換されている(「否定」を学習できた)
- 「かたつむり」が「まいまい」に置き換えられている(単語自体が変化したものも学習できている)
- 推論で使う単語に未知語が含まれると文章全体が
<unk>となる
課題は山積しているので、調査を続けます。
結果
-
既知語のみ
input :「行ったなあ」
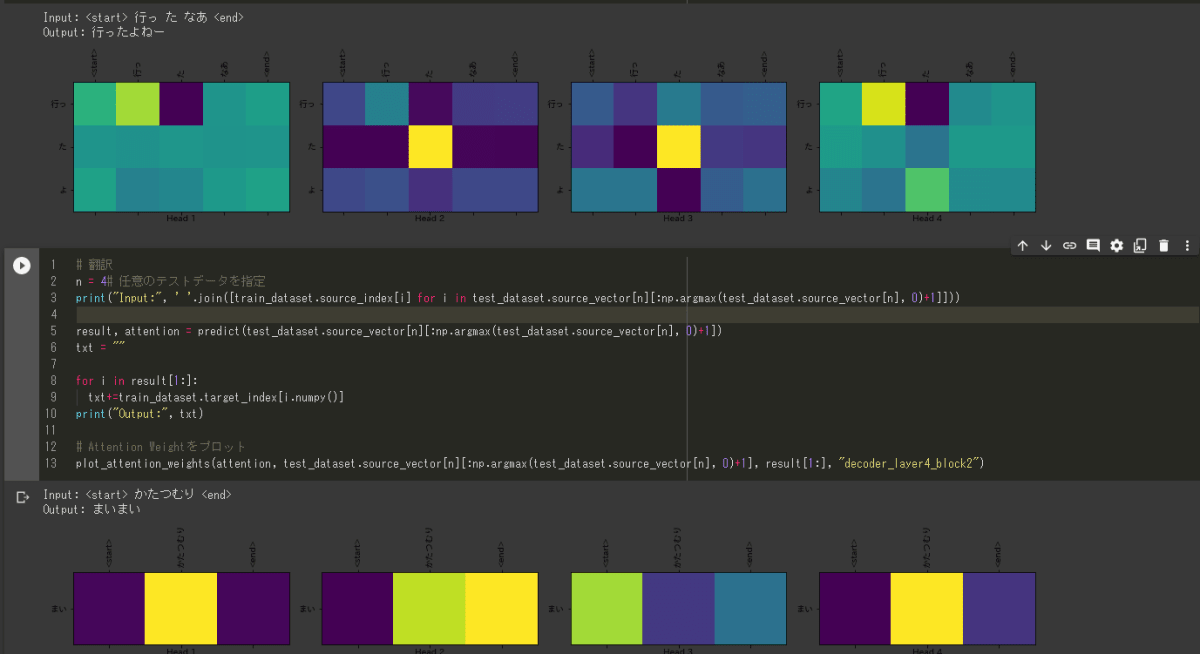
-
未知語含む
input :「中村ではない」
今回は「中村」を含む文章を学習させていない。
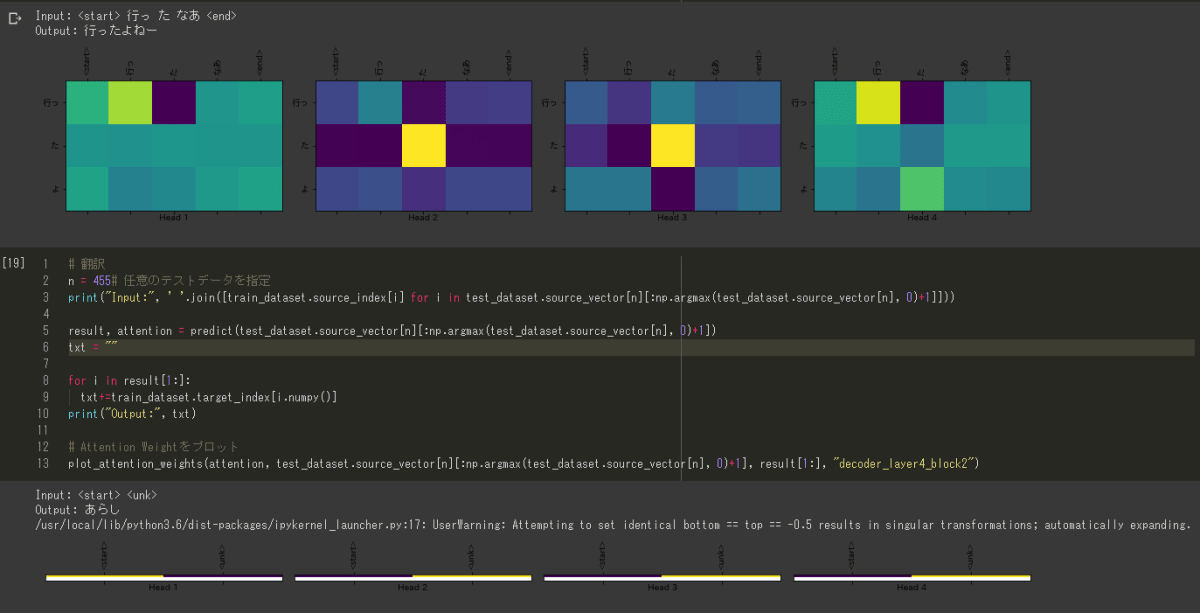
やっぱり<unk>は機能しないじゃないか!
改善点
カタカナで記載された方言訳を擬似的に平仮名に置き換えました。
本当は鼻濁音は「カ゜」としたいのですが、それをすると前回の二の舞に略
(標準語をカタカナに開く作業をやめました)
やったこと
- 方言アライメントを用意する(ネットサーフィンしまくりました)
- アライメントをtsvに変換する(リポジトリ内 Hiraki_Sudahi.ipynbで実行可能です)
- カタカナで記載された方言訳を擬似的に平仮名に置き換える**(変更点)**
- 参考ソースコードを用いてアライメントをベクトル化する
- Tensorflowを用いて学習・予測する
課題
方言訳に余計な文字がくっつく-> アライメント(コーパス)が足りない?
推論で使う単語に未知語が含まれると文章全体が<unk>となる -> これもコーパス不足?
(因みに、「中村」をコーパスに入っていた「山田」に変えると上手く動きます)
おわりに
コーパスを増殖させる方法を編み出したら、また記事を書きます。
Discussion