Athena Federated QueryでCloudWatchログを解析してみた
概要
Athenaでは通常、S3内のデータを解析するのに使っていたが、
CloudWatch Logsからも解析できるようにする必要があったので、
Athena Federated Queryという機能について調査をしてみた。
Agenda
Athena Federated Queryとは?
Amazon S3以外のデータソースをAthenaで解析したい時に使える機能。
Federated Queryではその場でデータをクエリしたり、
複数のデータソースからデータを抽出してS3に保存するパイプラインを構築したりできる。
Lambda上で起動するdata source connectorを使って、federated queryを実装する必要がある。
data source connectorはターゲットデータソースとAthena間の変換を行える拡張機能のようなもの。AthenaとLambdaまたはServerless Application Repositoryを利用することでデプロイできる。
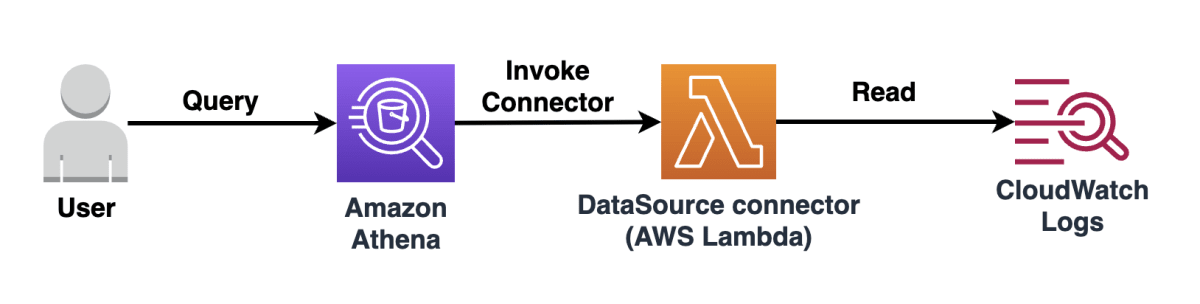
以下の流れでデータソースから情報を取得できる
- ユーザーがデータソースに対してクエリ送信
- Athenaが対応するData Source Connector(Lambda)を呼び出す
- datasource connectorはデータソースから必要なデータを取得
- 要求されたデータをユーザーに返す
Data Source ConnectorはAthena Query Federation SDKを使って自作することもできる。
その他考慮事項
以下のような点に注意
-
Federated QueryはAthena Engine Version 2 以上でないと使えない
-
Federated Data SourceでVIEWテーブルを作成できる。作成したVIEWはAWS Glueで保管される
-
INSERT INTOなどの書き込みクエリはサポートしていない
-
利用料金は、通常のAthenaデータスキャン料金 + Lamda実行料金がかかる
以下、引用したもの連携データソース (S3 に保存されていないデータ) の SQL クエリは、プロビジョニングされたキャパシティを使用しない限り、データソース間で Athena が集約したテラバイト (TB) 単位で切り上げられ、クエリごとに最小 10 MB が課金されます。このようなクエリではアカウントの AWS Lambda 関数も呼び出され、Lambda の使用には標準料金が課金されます。横串検索によって呼び出される Lambda 関数は、Lambda の無料利用枠の対象となります。詳しくは、Lambda の価格ページをご覧ください。
https://aws.amazon.com/jp/athena/pricing/
利用可能なデータソースコネクタ(data source connectors)
事前にAWS上でビルドされているコネクタがいくつかあり、ユーザーはそれを利用すればすぐにdata source connectorをデプロイすることができる。
ユーザー側は、使用したいコネクタを選択して、自分のアカウント上にデプロイするだけ。
以下のリンクで利用可能なコネクタがあるので、サービスに応じて必要なものを探してみるのが良い
Amazon Athena CloudWatch connector
ここでは今回利用予定のCloudWatch connectorのみ紹介。
このコネクタはAthenaとCloudWatch間の通信を可能にし、CloudWatch LogsのデータをSQLでクエリできる様になる。
仕様は以下の通り
- LogGroupsをスキーマとしている
- 各LogStreamをテーブルとしてマッピング
- LogGroup内のLogStreamを全てクエリ対象にできる様に
all_log_streamsビューがマップされている
CloudWatch connectorでマッピングされるテーブルには、以下のスキーマが含まれる
| Scheme | Type | Description |
|---|---|---|
| log_stream | VARCHAR | 対象のLogStreamの名前 |
| time | INT64 | ログが生成された時間(epoch time) |
| message | VARCHAR | ログメッセージ |
以下は指定されたLogStreamに対するSELECTクエリの実行例
SELECT *
FROM "lambda:cloudwatch_connector_lambda_name"."log_group_path"."log_stream_name"
LIMIT 100
以下はall_log_streamsビューで全LogStreamsを対象にしてSELECTクエリの実行例
SELECT *
FROM "lambda:cloudwatch_connector_lambda_name"."log_group_path"."all_log_streams"
LIMIT 100
Federated Queryを使ってみよう
Federated Queryを実行するには、以下のプロセスが必要です。
- Spill bucketの作成
- Data source connector (Lambda関数)のデプロイ
- Lambda関数のデータソースへの接続
順にやっていきましょう
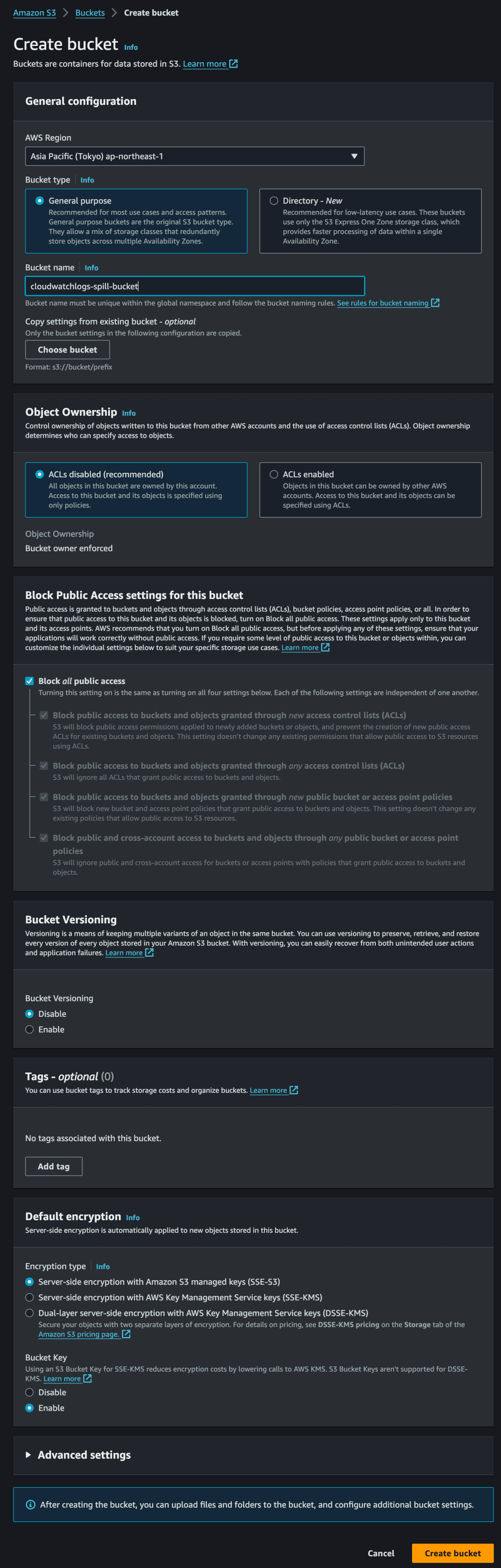
Spill Bucketの作成
Data Source Connectorデプロイ時に、Spill Bucketが必要なので、
事前にS3上から作成しておく。
Data source connectorのデプロイ
-
https://console.aws.amazon.com/athena/ で Athena コンソールを開きます。
-
ナビゲーションペインで、[Data source] (データソース) をクリックします。
-
[Data sources] (データソース) タブで [Connect data source] (データソースを接続する) を選択します。
-
フェデレーションデータソースとして [Amazon CloudWatch Logs] を選択
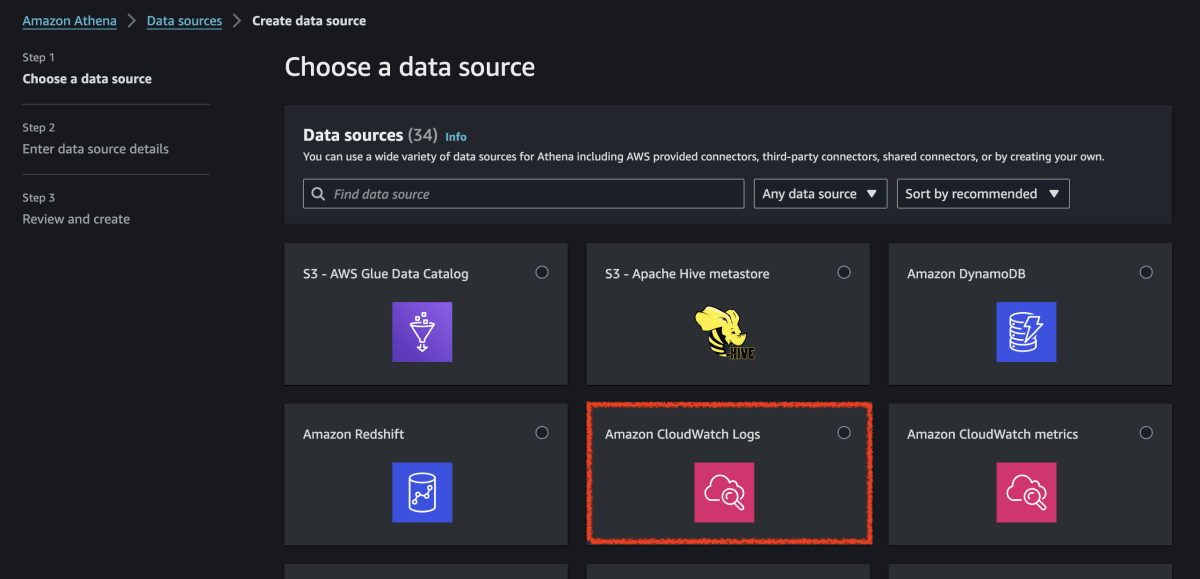
-
[Next] (次へ) をクリックします。
-
[Data source details] (データソースの詳細) ページの [Data source name] (データソース名) に、Athena からデータソースをクエリする際に SQL ステートメントで使用する名前 (例えば
CloudWatchLogs) を入力します。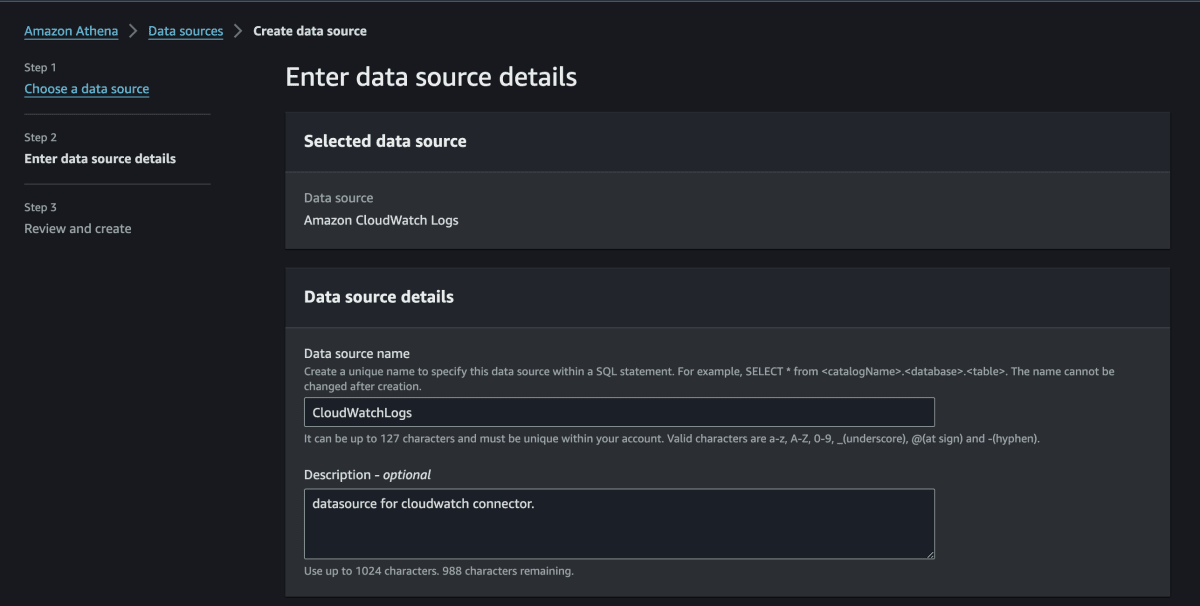
-
Lambda 関数を使用する場合、[Lambda 関数の作成] を選択します。選択したコネクタの機能ページが AWS Lambda コンソールで開きます。このページには、コネクタに関する詳細情報が表示されます。
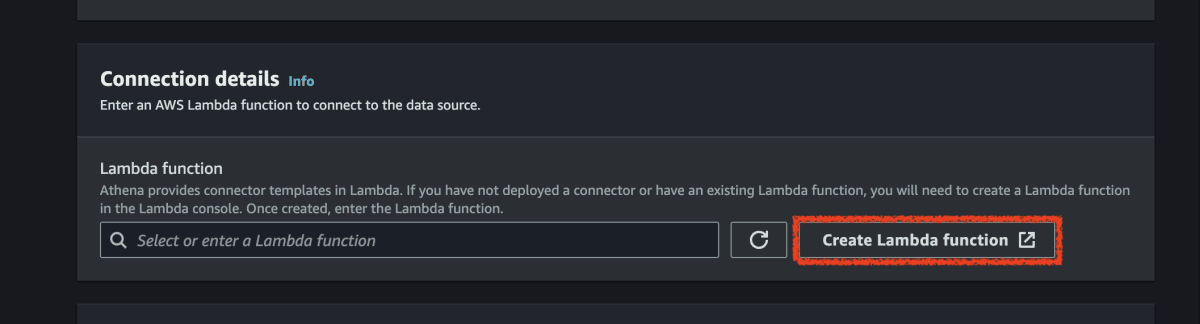
-
[アプリケーションの設定] で、各アプリケーション設定の説明をよく読み、要件に対応する値を入力します。表示されるアプリケーション設定は、データソースのコネクタによって異なります。最低限必要な設定は次のとおりです。
-
AthenaCatalogName – ターゲットとなるデータソースを示す小文字の Lambda 関数の名前です (例えば、
cloudwatchlogs)。 - [SpillBucket] – Lambda 関数のレスポンスサイズ制限を超えるデータを保存するための、アカウント内の Simple Storage Service (Amazon S3) バケット。事前に作成しておいたバケット名を記載。
-
AthenaCatalogName – ターゲットとなるデータソースを示す小文字の Lambda 関数の名前です (例えば、
-
[I acknowledge that this app creates custom IAM roles and resource policies] (このアプリがカスタム IAM ロールとリソースポリシーを作成することを承認します) を選択します。
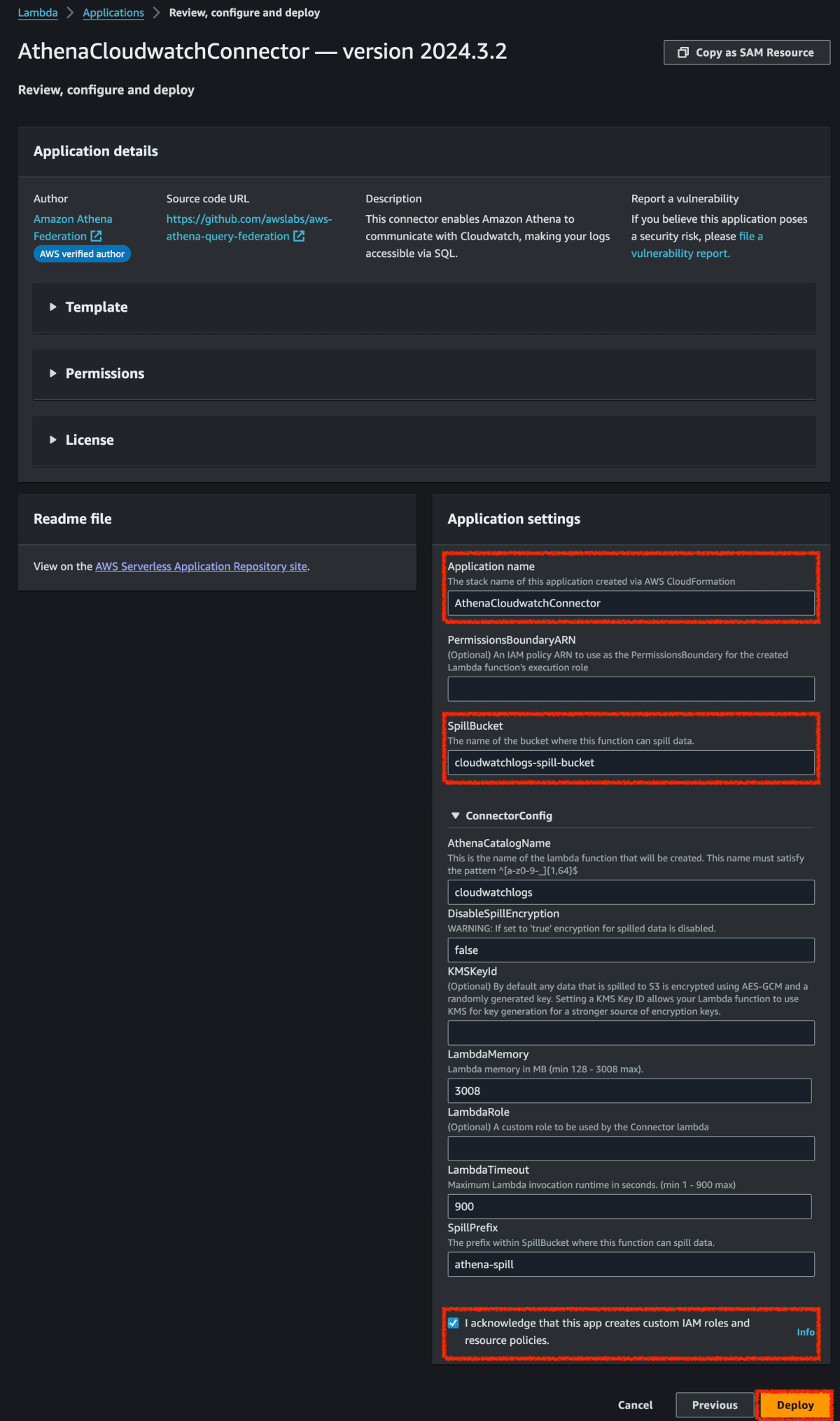
-
[デプロイ] を選択します。デプロイが完了すると、Lambda 関数が Lambda コンソールの [リソース] セクションに表示されます。
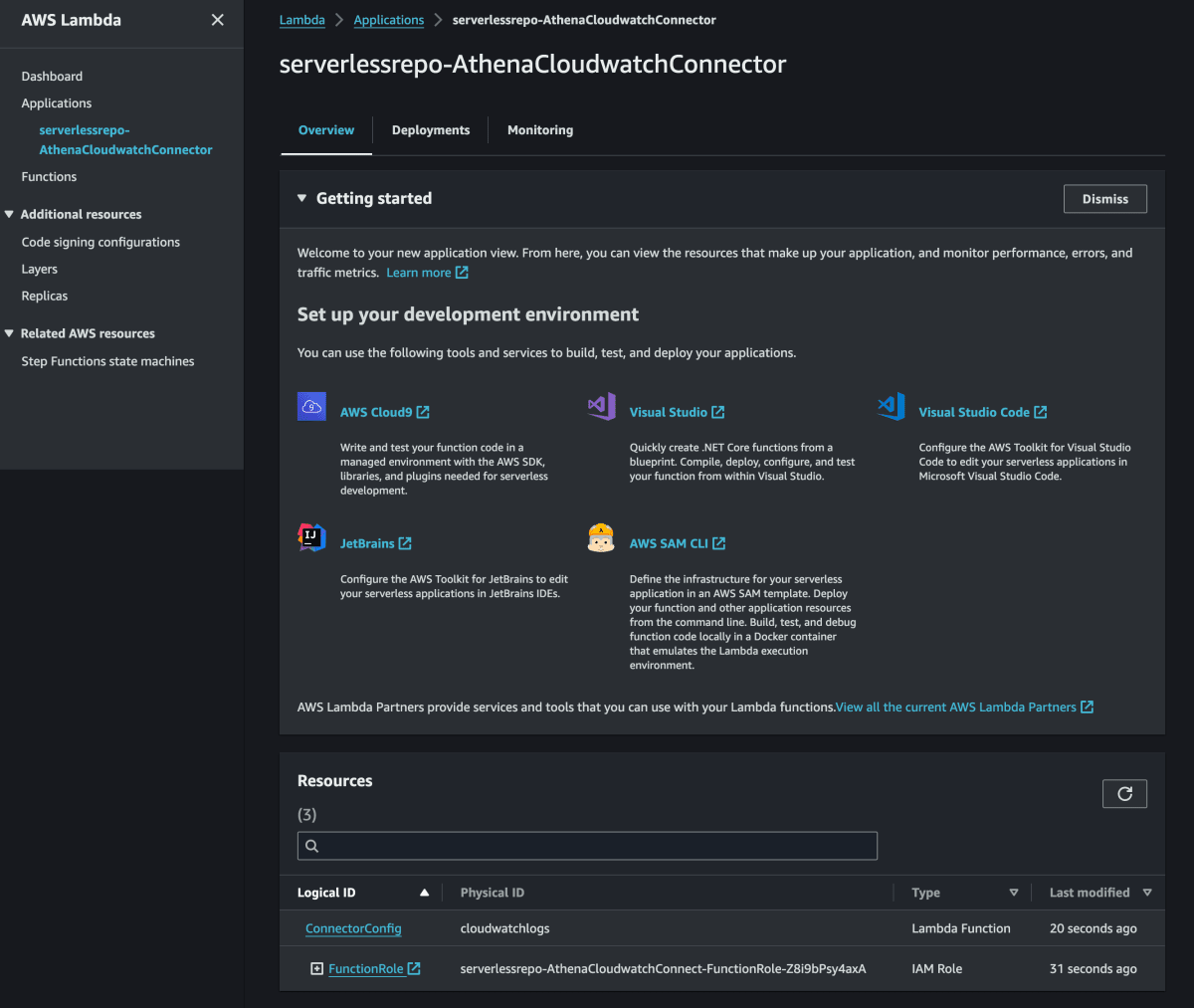
データソースへの接続
データソースコネクタをアカウントにデプロイしたら、Athena を接続できます。
-
Athena コンソールの [Connect data sources] (データソースを接続) ページに戻ります。
-
[接続の詳細] セクションで、[Lambda 関数を選択または入力] 検索ボックスの横にある更新アイコンを選択します。
-
Lambda コンソールで作成した関数の名前を選択します。Lambda 関数の ARN が表示されます。
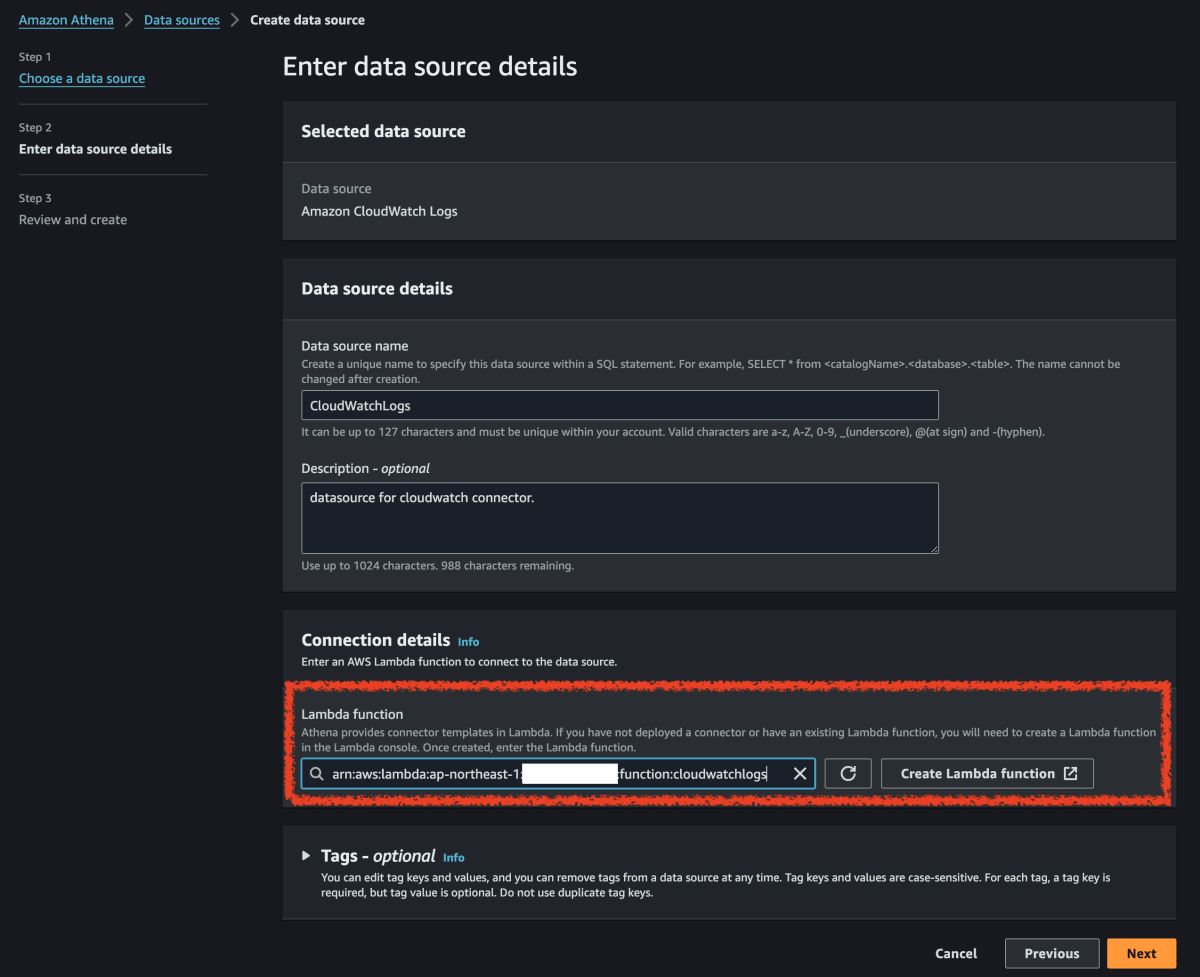
-
[Next] (次へ) をクリックします。
-
[Review and create] (確認と作成) ページで、データソースの詳細について確認し、[Create data source] (データソースの作成) を選択します。
-
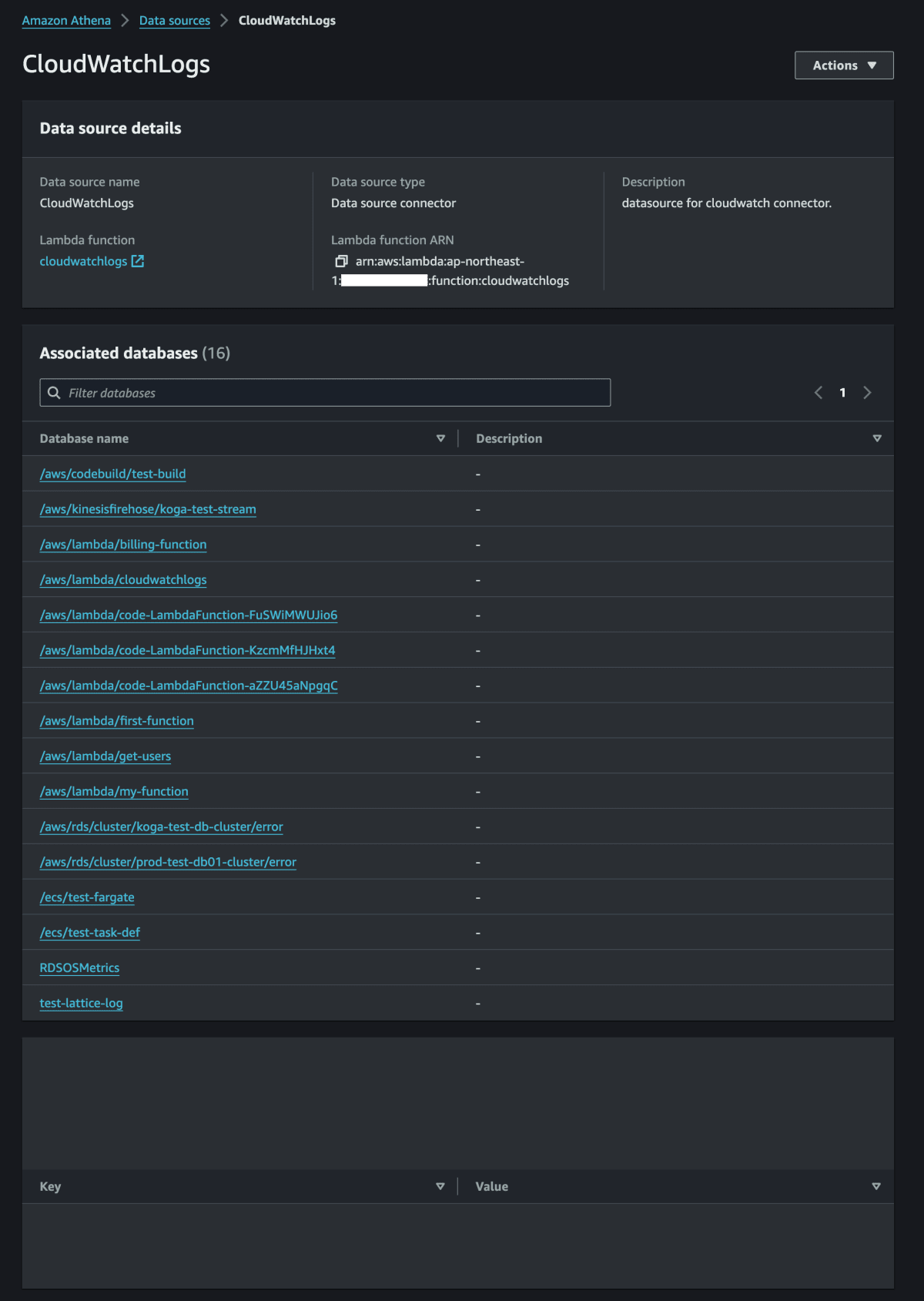
データソースのページの [データソースの詳細] セクションには、新しいコネクタに関する情報が表示されます。これで、Athena クエリでコネクタを使用できるようになりました。
CloudWatchコネクタを使用するAthenaクエリを作成
-
https://console.aws.amazon.com/athena/ で Athena コンソールを開きます。
-
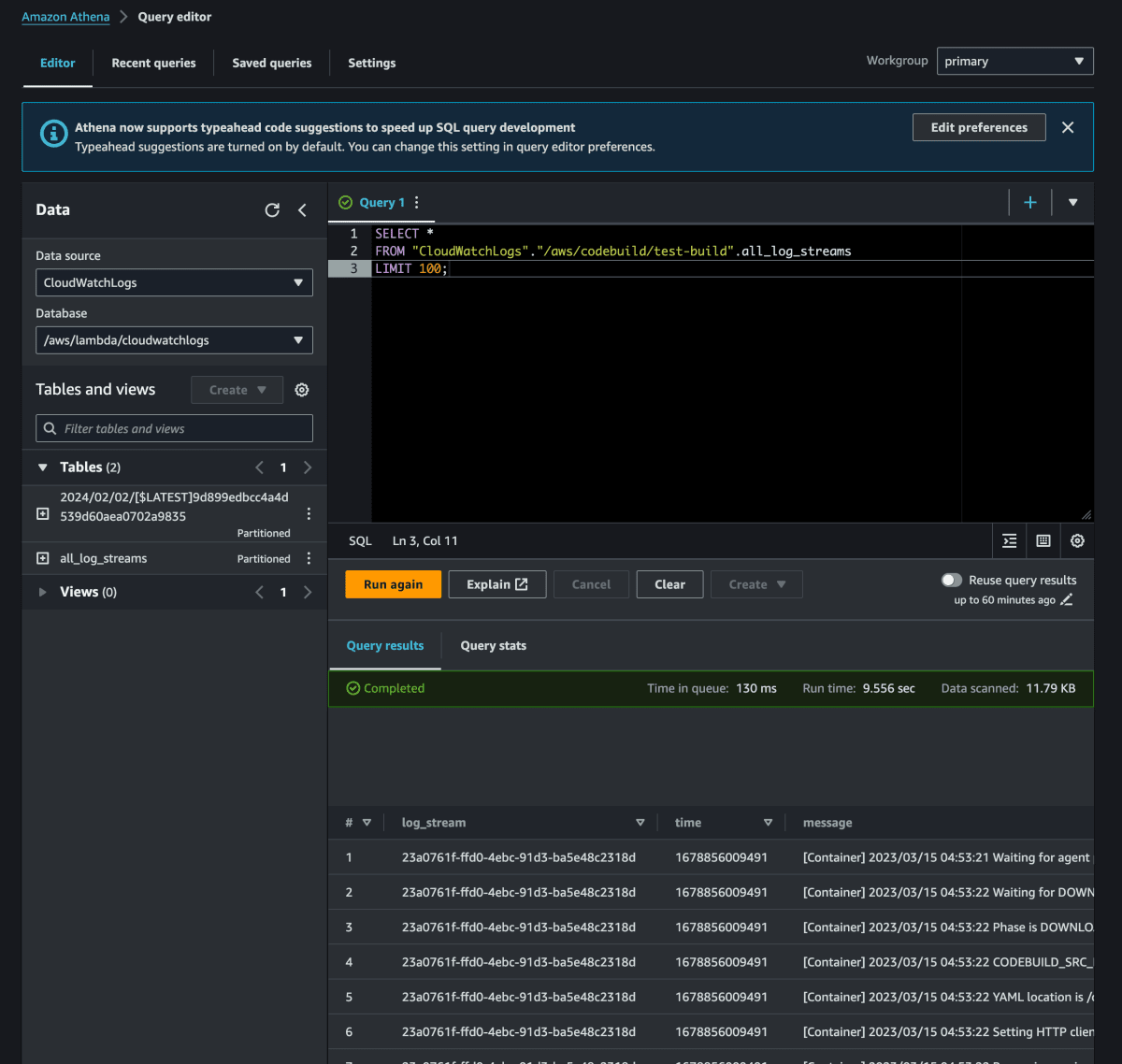
Athena クエリエディタで、
FROM句に次の構文を使用する SQL クエリを作成します。FROM MyCloudwatchCatalog.database_name.table_name
以下の例では、指定したCloudWatch Logs ロググループの all_log_streams ビューへの接続に Athena CloudWatch コネクタを使用します。all_log_streams ビューは、ロググループ内のすべてのログストリームのビューです。このクエリ例では、返される行数を 100 に制限します。
CloudFormationテンプレート
ハンズオンの内容をCloudFormationテンプレートで一発構築できるようにした。
Discussion