YOLOEの仕組みを整理してみた
概要
YOLOEと呼ばれるモデルがultralyticsで公開されました。今回は私なりにYOLOEの仕組みについて整理してみました。
本記事は、下記の記事 を日本語に翻訳し、筆者自身が理解のために補足・解説を加えたものです。内容の正確性については可能な限り努めていますが、誤訳などがある場合はご容赦ください。
背景
“see anything” がコンセプトのモデルになっている。
- 主に三つのタスクで検出およびセグメンテーションが可能
- Text prompts: 探してる単語をモデルに教える
- Visual prompts: 探したいサンプル画像をモデルに示す
- Prompt-free operation: ガイダンスなしに全てをモデルで同定する
- YOLO-Worldのようなモデルと比較して、3倍の訓練速度と1.4倍の推論速度の向上を達成した
従来の物体検出の問題
- 例えば、”車”と”人間”を検出するセキュリティシステムがあったとする
- ある日、”スクーター”に乗った”人間”がやってくる
- 従来のシステムだと、”スクーター”を学習していないため、検出に失敗してしまう
上記は閉じた語彙システムの限界であり、今までは明示的に学習をする必要があった。
アーキテクチャ
オープンボキャブラリーな検出に対応するために、近年のYOLOと同様の構造から出力された特徴量を基に構築されている。
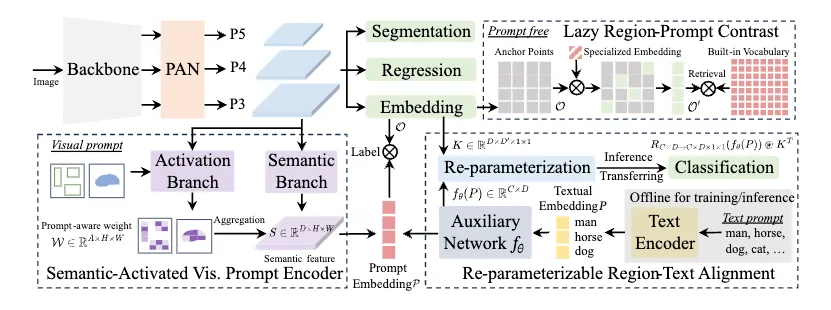
- Base Network
- YOLOv8あるいはYOLOv11で使用されたBackboneを使用
- PAN (Path Aggregation Network)
- 複数のスケールに対応(YOLOv8のNeckに相当する)
- Core Heads
- Regression Head
- 物体検出のbboxの座標を予測する
- Segmentation Head
- セグメンテーション用のプロトタイプマスクと係数を生成
-
Object Embedding Head (今回のプロンプト周りで使用する特徴量)
- 各アンカーポイントでの視覚内容を表現する埋め込み特徴量を作成
- Regression Head
Processing Pipeline
- Image Input
- 入力としての画像を受け取る
- Feature Extraction
- BackboneとPANが階層的に複数のスケールの特徴量を抽出する
- Anchor Points
- 画像をアンカーポイントのグリッドに分割する(最近はアンカーフリーだったが、このアプローチは昔のYOLOと似てる)
- Object Embeddings
- 各アンカーポイントに対して、物体埋め込み(特徴ベクトル)を生成する
- Prompt Processing
- 入力タイプに依存して、三つの経路のいずれかが起動する(後述)
- Text Prompts: RepRTA pathway
- Visual prompts: SAVPE pathway
- No prompts: LRPC pathway
- 入力タイプに依存して、三つの経路のいずれかが起動する(後述)
- Embedding Matching
- 内積によって、オブジェクトの埋め込みとプロンプトの埋め込みを比較する
- Output Generation
- モデルは下記を出力する
- 検出された物体のbbox
- 正確な物体境界におけるセグメンテーションマスク
- prompt matchingに基づくクラスラベル
- モデルは下記を出力する
どのようにしてオープン語彙の課題を解決したのか
Re-parameterizable Region-Text Alignment (RepRTA)
モデルがテキストの説明を理解して、画像内の視覚要素に一致させることができるようになった。言葉を理解するだけでなく、探しているものを視覚的に識別する手助けできる機構を追加している。
技術的な詳細
目的:テキストと視覚特徴の意味的整合性(alignment)を学習すること
-
Text Encoder
- MobileCLIP-B(LT) のテキストエンコーダを用いて、テキストプロンプトを処理し、事前学習済みのテキスト埋め込みを獲得する
-
Embedding Cache
- 効率性を向上させるために、訓練データセットの全てのテキスト埋め込みは訓練開始前にキャッシュされる。これにより、訓練中に反復的にテキストエンコーダが実行されるのを防ぐ
-
Auxiliary Network Architecture
- auxiliary network (fθ) は、一つの線形層の後に、SwiGLU活性化ともう一つの線形層を持つlightweight SwiGLU FFNブロックで構成される
- テキスト埋め込みを改善し、視覚特徴量との整合性を改善させる
-
1~3 の数式
- テキストプロンプトをT, 文の長さをCとすると、初期埋め込みは、
P = Textencoder(T)
- より改善された埋め込みがAuxiliary Network Architectureを通して達成される
P^{'} = f\theta(P) \in \mathbb{R}^{C \times D}
- 訓練中、アンカーポイントの埋め込みベクトルOは、上記の洗練された埋め込みと内積を通して比較される。
Label = O \cdot P^{'T} - これは、概要図で言うど真ん中のLabelの内積で評価してる箇所に相当
- テキストプロンプトをT, 文の長さをCとすると、初期埋め込みは、
-
Re-parameterization Process
- 学習時と推論時に異なるネットワークを使い分けることで、性能(学習時の賢さ)と効率(推論の軽量さ)を両立するテクニック
- 学習時はテキスト情報とのアラインメントなどリッチな情報を活用し、推論時は標準のYOLOのような軽量モデルで処理できるようにする
大まかな構造を下記に示す。推論時には補助ネットワーク全体が不要になるので、軽量かつ高速化される。
[学習時]
+------------------------+
Text (P) → | fθ(P) |
+------------------------+
↓
+---------+
Feature (I) →→→→→ | Conv w/ K′ | →→→ Prediction
+---------+
[推論時]
Feature (I) →→→→→ | Conv w/ K′ | →→→ Prediction
^^^^^^^^^^^
これは fθ(P) を反映済みの「再パラメータ化カーネル」
ちなみに、元論文の説明は下記のようになっている。

ここで、(A)の一番上が学習時の挙動で、一番下が推論時の構造になっている。
- BatchNormlizationは、offsetを調整し、scaleを乗算する演算のため、convのbiasとconv1x1の係数に置き換えが可能
- さらにconv1x1の係数は、周囲を0で埋めれば、conv3x3の係数におきかえることが可能
- 以上により、図のすべての接続は、conv3x3のbias付きconv層に置き換えが可能 (それを表したのが中段の部分)
- 最後にそれぞれの係数を加算すれば、一つのconv3x3のbias付きconv層に置き換えが可能
数式で説明すると、下記のようになる。これによって、重みのチャネル方向Dを保持しつつ、出力チャネルCを別の特徴空間に射影するような新しい畳み込みカーネル
ソースコードのサンプルは、下記のようになる。
import torch
C, D = 4, 3
D_dash = 7
K = torch.randn(D, D_dash, 1, 1) # shape: (D, D', 1, 1)
F = torch.randn(C, D) # shape: (C, D)
# einsum を使って C×D→C×D×1×1 のテンソルに再構成
K_prime = torch.einsum('cd,dexy->cd', F, K)
print(K_prime.shape) # => torch.Size([C, D])
K_prime =
tensor([[ 1.0073, -0.3360, -1.0229],
[-1.4695, 0.0445, 1.7203],
[-1.1093, -0.1270, 2.8297],
[-1.3035, 0.3748, 0.0179]])
補足:Q. 学習後にK’を固定してるなら、未知のプロンプトにはどう対応するの?
A. 学習したテキスト埋め込みに最も近いクラスタ(carやtruck)を選んで、学習時に対応していたK’を使用する。これによって、類似した単語に準拠した物体を検出できるような仕組みになっている。
また、学習はepoch=30で実施している。
Semantic-Activated Visual Prompt Encoder (SAVPE)
目的:モデルが、検索クエリとして画像サンプルを使うことを可能にしている。サンプルと最もらしいものを見つけるVisual Promptで利用
技術的な詳細
-
Dual-Branch Architecture
- 二つの並列処理を実施する
- Semantic Branch: プロンプトに依存しないセマンティック特徴量の生成
- Activation Branch: 特徴集約のためのプロンプトを意識した重みを生成
- 二つの並列処理を実施する
- Semantic Branch Implementation
- PANで生成された{P3, P4, P5}を利用
- それぞれのスケールに対して、二つの3x3の畳み込み層を適用
- 特徴量をアップサンプリングして集約
- 意味のある特徴量
S \in \mathbb{R}^{{\tiny \wedge}}(D \times H \times W)
- Activation Branch Implementation (1.のb.)
- バイナリマスクでvisual promptを定式化
- マスクをダウンサンプリングして、3x3の畳み込み層を通して処理を行い、プロンプト特徴量に変換
FV \in \mathbb{R}^{\tiny \wedge}(A \times H \times W)
- 画像特徴量 (
FI \in \mathbb{R}^{\tiny \wedge}(A \times H \times W) - FVとFIを結合して、プロンプト依存の重みWを生成する
W \in \mathbb{R}^{\tiny \wedge}(A \times H \times W)
- プロンプトが示す領域内でソフトマックスを使用して重みを正規化
- Grouping and Aggregation
- セマンティック特徴量SをAのグループに分割する
- default to A=16
- 各グループは D/A のチャンネルを持っており、Wに対応するチャンネルから重みを共有する
- このアプローチにより、視覚的手がかりをより低い次元(A≪D)で処理することが可能になり、計算コストが削減される
- セマンティック特徴量SをAのグループに分割する
- 数学的な定式化
- 最終的なプロンプト埋め込みは集約によって生成される
P = Concat(G1,...,GA) - ここで、
G_{i} = W_{i+1} \cdot S^{T}[D/A_{i} : D/A_{i+1}] - この埋め込みは次にアンカーポイントの物体埋め込みを参照して、類似した視覚特徴量を同定する
- 最終的なプロンプト埋め込みは集約によって生成される
補足:epoch=2でSAVPEのみを学習している点に注意。
まとめ
- 重要なのは、意味的特徴とプロンプト固有の活性化との間の効率的な相互作用
- 最小限の計算オーバーヘッドで強力な視覚的マッチングを実現
- 視覚的プロンプトをより低い次元(A=16 vs. D=通常256または512)で処理することにより、SAVPEはモデルを軽量に保ちながら強力な性能を達成
Lazy Region-Prompt Contrast (LRPC)
目的: プロンプトを使わずに、あらゆる認識可能な物体を同定する
技術的な詳細
-
Problem Reformulation
(計算コストの高い)汎用的な言語モデルを使って物体の説明をするのではなく、検索問題に対するプロンプトフリーな検出問題として再定式化した
- まず、すべての物体を検出する
- そして、検出された領域と事前に定義された語彙を効率的にマッチングさせる
-
Specialized Prompt Embedding (SPE)
- 訓練中、YOLOEは 特殊なプロンプト埋め込み(Ps) を学習し、単一カテゴリとしてすべての物体を検出するように最適化する
-
LRPCで学習してるのは、SPEのみで、アンカーポイントに何か物体がいるかどうかを判定してるのみ(ultralyticsのdfl_lossと同じ)。単純なので、1epochで十分という位置付けになっている
- より詳しく述べると、パラメータが少ないのと、目的が単純なのと、Zero-shot性能の悪影響を防ぐ(過学習の抑制)の三つが目的
-
LRPCで学習してるのは、SPEのみで、アンカーポイントに何か物体がいるかどうかを判定してるのみ(ultralyticsのdfl_lossと同じ)。単純なので、1epochで十分という位置付けになっている
- この埋め込みは、同じデータセットを使って1エポックだけ学習されるが、すべてのオブジェクトは単一クラスとしてラベル付けされる
- 一般的な "物体らしさ" 検出器を作成するために利用される
- 訓練中、YOLOEは 特殊なプロンプト埋め込み(Ps) を学習し、単一カテゴリとしてすべての物体を検出するように最適化する
-
Built-in Vocabulary
- 4585種類の一般的な物体カテゴリの語彙を内蔵している
- 多様なオブジェクトのタイプと属性をカバーするタグリストから収集されており、テキストエンコーダを使用して事前に計算されたテキスト埋め込みを使用
-
Efficient Two-stage Detection Algorithm
- step1: Filtering
- 特殊なプロンプト埋め込みを適用して、オブジェクトのあるアンカーポイントを特定する
-
O' = \{\, \mathbf{o} \in O \mid \mathbf{o} \cdot \mathbf{P}_{s}^{\mathsf{T}} > \delta \,\} - Oは全てのアンカーポイント集合で、Psは特殊なプロンプト埋め込み、δはフィルタリングの閾値で0.001が設定されている
- ここで生成されるのは1xDのベクトルになる(Dは検出数)
- step2: Retrieval
- 語彙に対するアンカーポイントO’をフィルタリングする
- この "怠惰な "アプローチは、関連する領域に対して計算コストのかかるマッチングを実行するだけである。
- step1: Filtering
-
数学的な定式化
- フィルタリングされたアンカーポイント
o \in O^{'} Scores = o \cdot V^{T}
- Vは全ての語彙の埋め込み行列
- 予測されるカテゴリとして、最もスコアの高いものが選択される
- フィルタリングされたアンカーポイント
まとめ
重要な革新点は、すべての語彙(4,585語)に対してすべてのアンカーポイント(通常8,400以上)を処理する必要性を回避することである。最初にフィルタリングを行うことで、LRPCは計算を最大80%削減し、精度を落とすことなく1.7倍のスピードアップを達成した。これにより、競合他社が必要とする大規模な言語モデルへの依存を排除し、プロンプト・フリー検出をリアルタイム・アプリケーションに実用化している。
Reference
- YOLOEの元論文
- 海外の説明記事
- 途中で言及されていたYOLO-world
- ※ テンセント製だが、テンセントは2025年1月にCMCリストに入ったので、アメリカでの商用利用はアウトだと思われる
- Re-parameterizationが実装されてるRepVGGの解説と元論文
Discussion