BoostTrack解説と実装
はじめに
昨年、BoostTrackと呼ばれるトラッキングのアルゴリズムが登場しました。
これを拡張したものがBoostTrack++で、現在のトラッキングアルゴリズムとしては最新の手法になると思います。
今回はBoostTrackのアルゴリズムを紹介したいと思います。
概要
MOT (Multiple Object Tracking)で重要なのは信頼性のない検出を制御して、ID Switchを避ける必要があります。
1st associationでは、低いconfidenceのスコアに対して、二種類のconfidence scoreでboostを行います
- 既存のトラッキングされた物体との一致を仮定する
- 既に検出された物体との一致性を仮定する
また、検出されたconfidenceとtrackletの信頼度の高い方が暗黙的に好まれ、iouの曖昧性を低減させるたえに、新しく提案された「マハラノビス距離」と「形状の類似度」が導入されています。
用語の注意
- tracklet (トラックレット)
- 実は先行研究によって異なる定義と用途が用いられています
- 詳しくは、先行研究の2.3 Tracklet confidenceを参照してください
- 一般的には短い時間の画像データから抽出された点の「動きの軌跡」の集合を指すので、カルマンフィルタの予測値だと思えば良いです
- 実は先行研究によって異なる定義と用途が用いられています
背景
MOTとして、近年まで主に下記のような手法が提案されてきました。
- Kalman filterで物体を追跡
- 検出とtracklet間の割り当て問題を二部グラフに落とし込んでハンガリアン法で解く
- ハンガリアン法に必要なコスト行列を作るために、存在してるtrackletsと検出間の類似度はIoUを使って効率的に測定している
- よりOcculusionや群衆でのシーンを想定して、画像特徴量を利用したFastReIDが用いられている
False positiveな検出やghost trackの総数を減らすために、低いconfidence検出はフィルタリングされ、それを通過した検出サブセットが割り当てとして利用される必要があります。
新規性
- multiple-stage assignmentを回避するために、detection-tracklet confidenceという両者を組み合わせたスコアを用いています
- IoUだと群衆やoutlierに対応できないので、マハラノビス距離や形状類似度を導入しています
- 上記を組み合わせたコスト行列(+ReID)を導入してトラッキングを実現しました
論点をまとめると、、、
- MOTにおいて重要なのは割り当て問題
- 割り当てる物体のFalse Positive と Ghost Track
- 近年だとmultiple-stageにする方針があるが…適切か?
- 割り当てのためのコスト行列設計
- IoUだけで良いのか?
- 割り当てる物体のFalse Positive と Ghost Track
近年のmultiple-stage assignmentの課題とアプローチ
近年の代表的な手法としてはByteTrackが存在してますが、これは二段階の割り当てに分けており、一段階目ではconfidenceの高いオブジェクトを対象に割り当てを行い、二段階目では余った(low-confidenceな)検出オブジェクトや割り当てられなかったtrackletsを対象に割り当てを実施します。
しかし、この手法はFalse PositiveとGhost Trackingを低減させたものの、IDSWsが増大してしまう欠点がありました。これは、ByteTrackが**「二つの物体のbboxが非常に重複しており、一方のみが高いconfidenceがある」**ことを仮定しているためであり、この過程は2nd stage assignmentで誤った物体に割り当てを追跡を紐づけてしまう欠点があります。
特に、いくつかの先行研究でも多段階の割り当てアプローチは identitity switches について言及がされていません。理想としては、下記を満たしているMOTアルゴリズムが要求されます:
- MOTはオンラインで動作し、リアルタイム処理を行えるべき
- 類似度測定は、1st stage assignmentにおいて全てのトラックレット検出ペアを正しく一致させるのに十分な識別能力を有しているべき
- 全ての真陽性検出が使用され、偽陽性検出は一切使用されないようにすべき
False Positive と Ghost Trackのようで検出すべきケース
よって、先行研究では二段階の割り当てを回避しつつ、低い信頼度の検出を活用するために、二つのlow-confidenceな下記のbboxをブーストする手法を提案されました。
- 既に存在すると予測されたオブジェクト
- 逆説的だが、オブジェクトが「存在すべきではない」と判断されるような低信頼度のバウンディングボックス(bbox)
- 壁で隠れた場合など
例えば、
- 物体が部分的に隠れてしまった場合、confidenceは低いが、追跡された予測位置とのiouは本来高いはず
- このような物体のconfidenceをブーストすべき
- 物体の存在を予測しない位置に低信頼度で検出されるケース
- ノイズと見なされる可能性があるが、実際には部分的にしか見えない新規物体(例:シーンへの進入や縁に立つ状態)
上記のようなoutliersに相当するものをきちんと識別できるようにするために、マハラノビス距離を導入しています。
multiple-stage assignmentを避ける方法
多段階の割り当て問題の恩恵を受けるために、「detection-tracklet confidence」が導入されました。これによって、 high-confidence detections or trackletsの優れた方を好む方式にすることができるため、1st assignmentだけで大丈夫になります。
コスト行列の設計について
また、IoUのみで割り当てを実施してしまうと、混雑したシーンでIDの切り替えが多く発生してしまうため、上記のIoUや物体移動の運動特徴量に加えて、ReIDによる外観特徴量も使用しています。しかし、FPSが低下してリアルタイム応用の可能性が損なわれるかもしれません。
よって、コスト行列に対して三つの軽量なプラグインを導入することで割り当てのパフォーマンスを向上させます。
- IoUをスケールさせるためにdetection-tracklet confidenceを用いて、高いconfidenceのdetection-trackletのペアの類似度を増大させる
- マハラノビス距離を用いて評価されるtrackletの分散を考慮した類似度指標として用いる
- カイ二乗分布の信頼区間に依存する
- 群衆でIDがスイッチしてしまう可能性を低減させるために、移動してる物体の高いIoUによって起きてしまう不一致に起因する形状類似度を導入
- ただし、物体の形状(widthやheight)は比較的短時間で一定であるべき
提案手法
全体のフロー
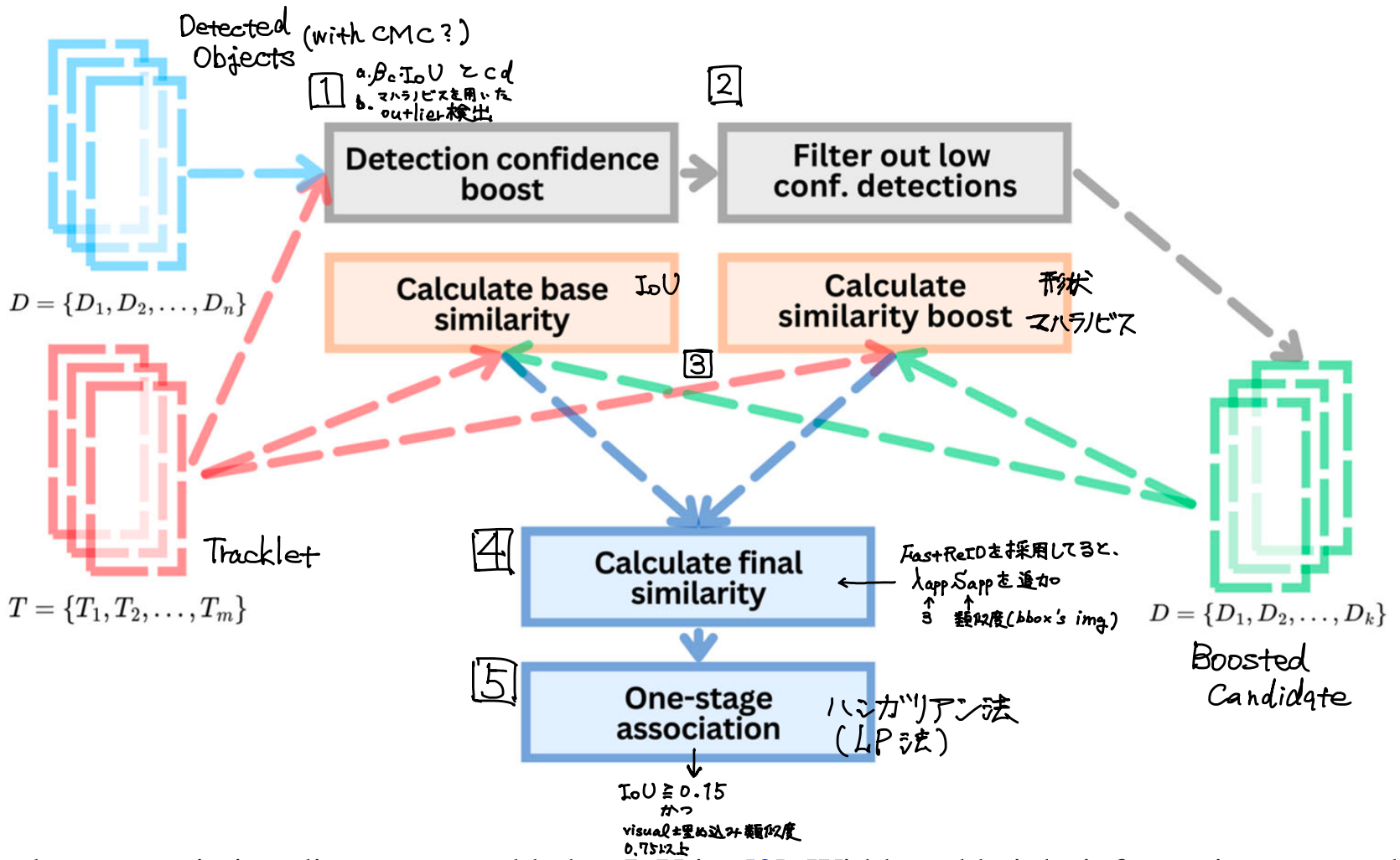
Detection-tracklet confidence similarity boost
まず、detectionsの集合を
また、
Tracklet confidence
直近で更新されたtracklets (検出に割り当てられて、カルマンフィルタの更新ステップが実行されたアクティブなtracklets)は、より信頼できる予測と高いconfidenceを持っているべきです。例えば、初期のノイジーな予測のために、新規のtrackletsはconfidenceが低いことがあります。
これらの要素を考慮して、下記のような指標を用意しています。
- 上式は若いTrackletsを定義しており、論文では
s_{init}=7
- 下式は古いTrackletsを定義しており、
last\_update(T_{j})
定式化
上記をまとめると、detection confidenceを
そして、confidence matrixを
これらのスコアを組み合わせると、類似度行列 Sは、スケールされた
ここで、
また、
Mahalanobis distance similarity boost
マハラノビス距離を用いた類似度計算は、いくつかの先行研究で検証されています。
- 状態推定として使われているカルマンフィルタ
- プロセスノイズや観測ノイズに関して、平均と共分散が既知である仮定以外に依存せず、厳密な性能評価ができる
- しかし、上記のノイズはガウシアンであることを仮定している
- マハラノビス距離は(非中心)カイ二乗分布であり、その値は自由度と信頼区間に依存する
- 大抵は95%信頼区間と自由度4が使われており、比較的低い形状パラメータ
\lambda = 0.02 (0, 0.948) - 先行研究では99%が採用されている
- 大抵は95%信頼区間と自由度4が使われており、比較的低い形状パラメータ
結果として、下記のように数式化することができます。
pythonの実装は、BoxMOTを参考にすると、下記のようになっています。
def get_mh_dist_matrix(self, detections: np.ndarray, n_dims: int = 4) -> np.ndarray:
if len(self.trackers) == 0:
return np.zeros((0, 0))
z = np.zeros((len(detections), n_dims), dtype=float)
x = np.zeros((len(self.trackers), n_dims), dtype=float)
sigma_inv = np.zeros((len(self.trackers), n_dims), dtype=float)
for i in range(len(detections)):
z[i, :n_dims] = convert_bbox_to_z(detections[i, :]).reshape(-1)[:n_dims]
for i, trk in enumerate(self.trackers):
x[i] = trk.kf.x[:n_dims]
sigma_inv[i] = np.reciprocal(np.diag(trk.kf.covariance[:n_dims, :n_dims]))
return ((z.reshape((-1, 1, n_dims)) - x.reshape((1, -1, n_dims))) ** 2 *
sigma_inv.reshape((1, -1, n_dims))).sum(axis=2)
上記のようにマハラノビス行列を作成して、下記の処理によって生成されます。
- カイ二乗分布のフィルタリング
- BoxMOTでは先行研究と同様に99%信頼区間が採用されている
- ソフトマックス正規化
- softmax_tempの温度パラメータは1なので、特別な処理はなし
- 補足:温度に関する説明はこちら
-
T > 1(高い温度): 入力値の差を小さくする効果がある。これにより、出力される確率の分布がより均一になる。つまり、最も高い確率を持つ要素と、それ以外の要素の確率の差が縮まる。 -
T < 1(低い温度): 入力値の差を大きくする効果がある。これにより、最も大きな入力値に対応する確率が1に近づき、他の入力値の確率は0に近づく。これは「ハードな」ソフトマックスと呼ばれ、最大値を選択する挙動に近くなる。 -
T = 1: 入力値がそのまま使われるため、特別なスケーリング効果はない。
-
def MhDist_similarity(mahalanobis_distance: np.ndarray, softmax_temp: float = 1.0) -> np.ndarray:
limit = 13.2767 # 99% conf interval https://www.mathworks.com/help/stats/chi2inv.html
mahalanobis_distance = deepcopy(mahalanobis_distance)
mask = mahalanobis_distance > limit
mahalanobis_distance[mask] = limit
mahalanobis_distance = limit - mahalanobis_distance
mahalanobis_distance = np.exp(mahalanobis_distance / softmax_temp) / np.exp(
mahalanobis_distance / softmax_temp).sum(0).reshape((1, -1))
mahalanobis_distance = np.where(mask, 0, mahalanobis_distance)
return mahalanobis_distance
Shape similarity boost
可能な限り他の類似度指標(IoU)による曖昧性を避けるために、形状に関する類似度指標を用意しています。
- 二つの物体が非常に被っている場合を考えると、一致してるtrackletsは非常に大きなIoUを有しており、誤った検出をするためIDが切り替わってしまうかもしれない
- しかしながら、短い時間のフレームでは物体の形状は比較的一定のはずである
- この仮定を用いて曖昧性を排除する
基本的に、直近に更新されてないtrackletの形状情報を信用してはなりません。例えば、人が一時的に手を振ると検出されるbboxの幅が大きくなることがあります。また、カメラ移動すると物体の高さも変化するはずです。そして、当然のことながらconfidenceも考慮して複合的に識別するべきです。
以上をまとめると、前述したdetection-tracklet confidenceを用いて下記のように定式化しています。
したがって、
まとめ:コスト行列設計
まとめると、類似度スコアは下記のように表現できます。
ただし、先行研究ではグリッドサーチによる手動最適化の結果、
Detection confidence boosting techniques
全てのlow-confidenceな検出結果が偽陽性であるとは限らないので、二つの事例についてはconfidenceスコアをブーストするような仕組みが導入されています。
Detecting likely objects (dlo)

例えば、あるオブジェクトが部分的に隠れてしまっている場合を考えます。これだとconfidenceは低い値になってしまい、bboxは閾値によってフィルタリングされてしまいます。しかし、カルマンフィルタで次の移動さきは予測できるはずです。この場合、detectionとtrackletのIoUは高いはずで、このような事象のbboxのconfidenceは高い値に補正されるべきです。
したがって、強化されたconfidence
ただし、
Detecting “unlikely” object (duo)
前述とは逆の物体として、例えば「追跡中のオブジェクトから遠く離れた低信頼度の検出」を、「以前から存在していたが未検出のオブジェクト」と見なしたい。このとき、下記のアプローチで外れ値を導出します。
- 外れ値の特定: まず、マハラノビス距離が高い点(遠い点)を特定します。
- 重要度の反転: 次に、その高い距離を、低い値に変換します。この後の処理で、この変換された値が「新しいオブジェクトである可能性」を示すスコアとして使われると推測されます。
先ほどの
これは、全てのbboxがあるtrackletに対してマハラノビス距離が大きい外れ値が採用されるようになっており、それらは13.2767に固定されます。また、limitとの差分をとったものがマハラノビス距離として採用されるようになっています。
mask = mahalanobis_distance > limit
mahalanobis_distance[mask] = limit
mahalanobis_distance = limit - mahalanobis_distance
つまり、下記のようにconfidenceが低く、最も近い既存のtrackletとのマハラノビス距離が2178.23である場合はマスクの対象となり、距離がゼロになるように上記のソースコードのように補正されます。この場合、過去に存在していた物体は新規の物体として検出されてしまうが、それはRe-ID情報を組み合わせることで、「隠れた既存のオブジェクトの追跡継続」と「未検出だった新しいオブジェクトの追跡開始」の両立を目指す方向になっていると考えられます。

その他の情報
使用した物体検出モデルやReIDについて
本研究ではYOLOX-Xが使用されており、CMCによる運動補正も行っています。
FastReIDが用いられており、OC-SORTと同じ重み付けのモデルが採用されています。また、前述の類似度スコアに対して
そのかわりに、資格情報は下記の閾値を超えたもののみが採用されるようになっています。
ただし、
参考資料
Discussion