ケーススタディ:クレーム分析|独立性の検定
はじめに
マーケティングの現場で重要視される“顧客の属性による行動傾向の違い”の把握について、
この記事では、マーケティング関連の顧客データを用いて、「クレームの有無」と各属性との関係をカイ二乗検定によって統計的に検証するプロセスを紹介します。
クレーム以外にも、「満足度」「購入有無」にも活用できます。
分析目的
以下が統計的に関連があるのかを検証
①既婚者と独身でクレーム有無に差があるか?
②子供の有無とクレーム有無に関連があるか?
③収入とクレーム有無に関連があるか?
使用データ
- データセット:Customer Personality Analysis(Kaggle)
- 顧客マーケティングデータ(顧客の基本情報・購買履歴・クレーム有無などを含む)
- サンプル数:2,240件
- 使用変数:
-
Complain:過去2年間に顧客がクレームを申し立てたかどうか(1=あり、0=なし) -
Marital_Status:婚姻状況(例:Single, Married, Together など) -
Kidhome:世帯内の子供の人数 -
Income:年間世帯収入
-
使用手法
分析ステップ
ステップ1:データの基礎俯瞰
| Column | 欠損値 | データ型 |
|---|---|---|
Complain |
なし | int |
Marital_Status |
なし | object |
Kidhome |
なし | int |
Income |
あり(24/2,240) | float |
-
Complainの分布:

1(クレーム有)が圧倒的に少ない
ステップ2:前処理
- 除外処理:
-
Incomeが欠損のデータを除外:2,240 → 2,216件 -
Marital_Statusが「Absurd(不明)」と「YOLO(「人生一度きり」というスラング的回答)」を除外:2,216 → 2,212件
-
-
Marital_Status:現在法的に未婚 or 既婚 でカテゴリを再定義- 'Married':'Married'
- 'Not Married':'Single', 'Together', 'Divorced', 'Widow', 'Alone'

-
Kidhome:子供無0 or 有1 のカテゴリで再定義
-
Income:- 収入の小さい順から3分割で「低(S)」「中(M)」「高(L)」のカテゴリで再定義
- サンプルサイズが小さいかったため、「中」「高」を結合し検定を行う

ステップ3:クロス集計表作成
-
仮説①:既婚者と独身でクレーム有無に差があるか?
- 実測値
Complain 無 有 合計 既婚 849 8 857 独身 1,342 13 1,355 合計 2,191 21 2,212 - 期待度数
Complain 無 有 合計 既婚 848.86 8.14 857 独身 1,342.14 12.86 1,355 合計 2,191 21 2,212 期待度数5以下のセルがないので、カイ二乗検定が使用できそう
-
仮説②:子供の有無とクレーム有無に関連があるか?
- 実測値
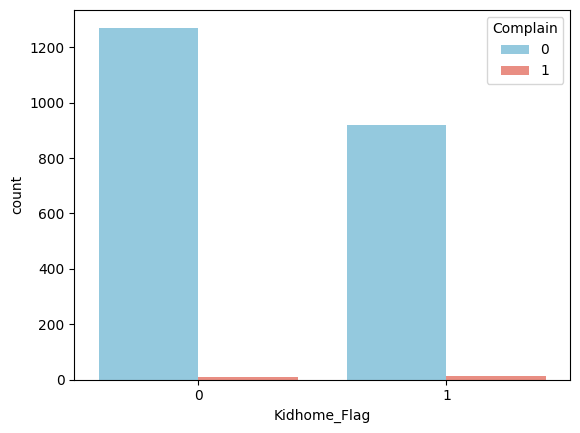
Complain 無 有 合計 子供無 1,271 8 1,279 子供有 920 13 933 合計 2,191 21 2,212 - 期待度数
Complain 無 有 合計 子供無 1,266.86 12.14 1,279 子供有 924.14 8.86 933 合計 2,191 21 2,212 期待度数5以下のセルがないので、カイ二乗検定が使用できそう
-
仮説③:収入とクレーム有無に関連があるか?
- 実測値
Complain 無 有 合計 低 726 12 738 中・高 1,465 9 1,474 合計 2,191 21 2,212 - 期待度数
Complain 無 有 合計 低 730.99 7.01 738 中・高 1,460.01 13.99 1,474 合計 2,191 21 2,212 期待度数5以下のセルがないので、カイ二乗検定が使用できそう
ステップ4:検定実施
ステップ3の結果から、期待度数5以下のセルがないため、カイ二乗検定で評価
※ 期待度数5以下のセルはないがサンプルサイズが小さいため、念のためFisherの正確確率検定も実施
-
独立性の検定(カイ二乗検定) → 手法の説明はこちら
仮説①:既婚者と独身でクレーム有無に差があるか?- カイ二乗統計量:0.0 p値:1.0
- 設定有意水準:0.05(両側検定)
- 帰無仮説:棄却できない
- 解釈:既婚者or独身とクレーム有無は独立(=関係があるとはいえない)
仮説②:子供の有無とクレーム有無に関連があるか?
- カイ二乗統計量:2.61 p値:0.106
- 設定有意水準:0.05(両側検定)
- 帰無仮説:棄却できない
- 解釈:子供の有無とクレーム有無は独立(=関係があるとはいえない)
仮説③:収入とクレーム有無に関連があるか?
- カイ二乗統計量:4.367 p値:0.037
- 設定有意水準:0.05(両側検定)
- 帰無仮説:棄却
- 解釈:収入とクレーム有無は独立でない(=関係がある可能性がある)
-
独立性の検定(Fisherの正確確率検定) → 手法の説明はこちら
仮説①:既婚者と独身でクレーム有無に差があるか?- オッズ比:1.028 p値:1.0
- 設定有意水準:0.05(両側検定)
- 帰無仮説:棄却
- 解釈:既婚者or独身とクレーム有無は独立(=関係があるとはいえない)
仮説②:子供の有無とクレーム有無に関連があるか?
- オッズ比:2.245 p値:0.07690
- 設定有意水準:0.05(両側検定)
- 帰無仮説:棄却
- 解釈:子供の有無とクレーム有無は独立(=関係があるとはいえない)
仮説③:収入とクレーム有無に関連があるか?
- オッズ比:0.372 p値:0.03327
- 設定有意水準:0.05(両側検定)
- 帰無仮説:棄却
- 解釈:収入とクレーム有無は独立でない(=関係がある可能性がある)
Fisherの正確確率検定結果も、カイ二乗検定と同様の結論となった
-
関連の方向性確認
収入レンジ別クレーム率の確認クレーム有 合計 クレーム率 低 12 738 1.63% 中・高 9 1,474 0.61% 合計 21 2,212 0.95% - 解釈:低収入者のほうが、中・高に比べてクレーム率が高い
オッズ比の確認
- オッズ比:0.372
- 解釈:
「低」を分子、「中・高」を分母とした場合の オッズ比 < 1 のため、
「低」収入者のほうがクレームしやすい
示唆と次のアクション
-
分析結果:
- 既婚者or独身、子供の有無とクレーム有無に関係があるとはいえない
- 収入とクレーム有無に関係がある可能性がある
- 低収入者のほうがクレームしやすい傾向がみられた
-
今回の示唆:
- 低収入者に対するサポートやキャンペーン施策が不十分である可能性がある
- 顧客の収入水準によって、サービスに対する期待や満足の閾値が異なる可能性がある
低収入層は支払対価に対する期待が相対的に高いため、サービスの不満点に敏感である可能性がある
-
Next分析案:
-
他要因との組み合わせでさらに要因深堀(収入 × 子供有無 等)
今回の分析でもかなりサンプルサイズが少なかったため、
サンプルサイズを増やすことを先に検討したほうがよさそう -
クレーム内容のテキスト分析:
低収入者はどのような内容でクレームを入れているか?を確認 -
クレーム後の行動分析:
クレーム後の離脱や購入停止、その後の利用行動をもとに、
クレーム対応次第でその後の行動に差が出るか?クレーム=解約兆候になるか?を分析 -
満足・推奨との関係:
クレームを出した人のNPS(Net Promoter Score)アンケートとの関係性を分析
-
他要因との組み合わせでさらに要因深堀(収入 × 子供有無 等)
-
ビジネスアクション案
-
カスタマーサポート強化:
低収入層向けのFAQやチャットボットなどで即時対応できる仕組みを強化 -
アンケートのタイミング調整:
低収入層に対して「早期の不満拾い上げアンケート」を導入しクレームに至る前の解決を目指す -
セグメント別対応:
セグメント分けして、パーソナライズされた対応やDM送付を実施
-
カスタマーサポート強化:
Discussion