LLMを使用したドキュメント用リアルタイムナレッジグラフの構築
CocoIndexを使用すると、継続的なソース更新によるナレッジグラフの構築と維持が簡単になります。このブログでは、ドキュメントのリスト(CocoIndexのドキュメントを例として使用)を処理します。LLMを使用して各ドキュメント内の概念間の関係を抽出します。次の2種類の関係を生成します:
- 主語と目的語の間の関係。例:「CocoIndexは増分処理をサポートしています」
- ドキュメント内のエンティティの言及。例:「core/basics.mdx」は
CocoIndexと増分処理に言及しています。

私たちは常に改善を続けており、さらに多くの機能と例が近日中に公開される予定です。
最新情報を入手するには、GitHubリポジトリにスターを付けてフォローしてください。
前提条件
- PostgreSQLのインストール。CocoIndexは増分処理のために内部でPostgreSQLを使用しています。
- Neo4jのインストール、グラフデータベース。
- OpenAI APIキーの設定。または、LLMモデルをローカルで実行するOllamaに切り替えることもできます - ガイド。
ドキュメント
プロパティグラフターゲットに関する公式CocoIndexドキュメントはこちらで読むことができます。
ナレッジグラフを構築するためのデータフロー
ソースとしてドキュメントを追加する
docs/coreディレクトリからCocoIndexのドキュメントマークダウンファイル(.md、.mdx)を処理します(マークダウンファイル、デプロイされたドキュメント)。
@cocoindex.flow_def(name="DocsToKG")
def docs_to_kg_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
data_scope["documents"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="../../docs/docs/core",
included_patterns=["*.md", "*.mdx"]))
ここで flow_builder.add_source は KTable を作成します。
filename は KTable のキーです。

データコレクターを追加する
ルートスコープにコレクターを追加します:
document_node = data_scope.add_collector()
entity_relationship = data_scope.add_collector()
entity_mention = data_scope.add_collector()
-
document_nodeはドキュメントを収集します。例えば、core/basics.mdxはドキュメントです。 -
entity_relationshipは関係を収集します。例えば、「CocoIndexは増分処理をサポートしています」はCocoIndexと増分処理の間の関係を示します。 -
entity_mentionはドキュメント内のエンティティの言及を収集します。例えば、core/basics.mdxはCocoIndexと増分処理に言及しています。
各ドキュメントを処理し、要約を抽出する
ドキュメントの要約を抽出するための DocumentSummary データクラスを定義します。
@dataclasses.dataclass
class DocumentSummary:
title: str
summary: str
フロー内で、構造化された出力のためにcocoindex.functions.ExtractByLlmを使用します。
with data_scope["documents"].row() as doc:
doc["summary"] = doc["content"].transform(
cocoindex.functions.ExtractByLlm(
llm_spec=cocoindex.LlmSpec(
api_type=cocoindex.LlmApiType.OPENAI, model="gpt-4o"),
output_type=DocumentSummary,
instruction="Please summarize the content of the document."))
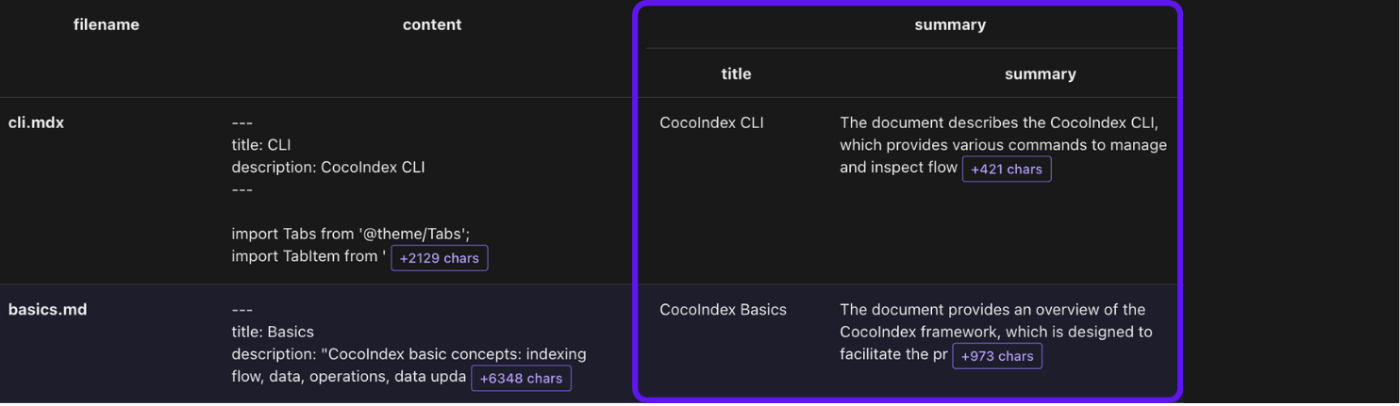
document_node.collect(
filename=doc["filename"], title=doc["summary"]["title"],
summary=doc["summary"]["summary"])
doc["summary"] は data_scope["documents"] の KTable に新しい列を追加します。
ドキュメントから関係を抽出する
関係を表すデータクラスを定義します。
@dataclasses.dataclass
class Relationship:
"""
Describe a relationship between two entities.
Subject and object should be Core CocoIndex concepts only, should be nouns. For example, `CocoIndex`, `Incremental Processing`, `ETL`, `Data` etc.
"""
subject: str
predicate: str
object: str
このデータクラスは、LLMが関係を正しく抽出するために、クラスレベルのドキュメント文字列に詳細な指示を入れることをお勧めします。
-
subject: ステートメントが関連するエンティティを表します (例: 'CocoIndex'). -
predicate: サブジェクトとオブジェクトを接続する関係のタイプまたはプロパティを説明します (例: 'supports'). -
object: サブジェクトが述語を介して関連するエンティティまたは値を表します (例: 'Incremental Processing').
この構造は、"CocoIndex supports Incremental Processing" のような事実を表します。そのグラフ表現は次のとおりです:

次に、cocoindex.functions.ExtractByLlm を使用してドキュメントから関係を抽出します。
doc["relationships"] = doc["content"].transform(
cocoindex.functions.ExtractByLlm(
llm_spec=cocoindex.LlmSpec(
api_type=cocoindex.LlmApiType.OPENAI,
model="gpt-4o"
),
output_type=list[Relationship],
instruction=(
"Please extract relationships from CocoIndex documents. "
"Focus on concepts and ignore examples and code. "
)
)
)
doc["relationships"] は各ドキュメントに新しいフィールド relationships を追加します。output_type=list[Relationship] は、変換の出力が LTable であることを指定します。
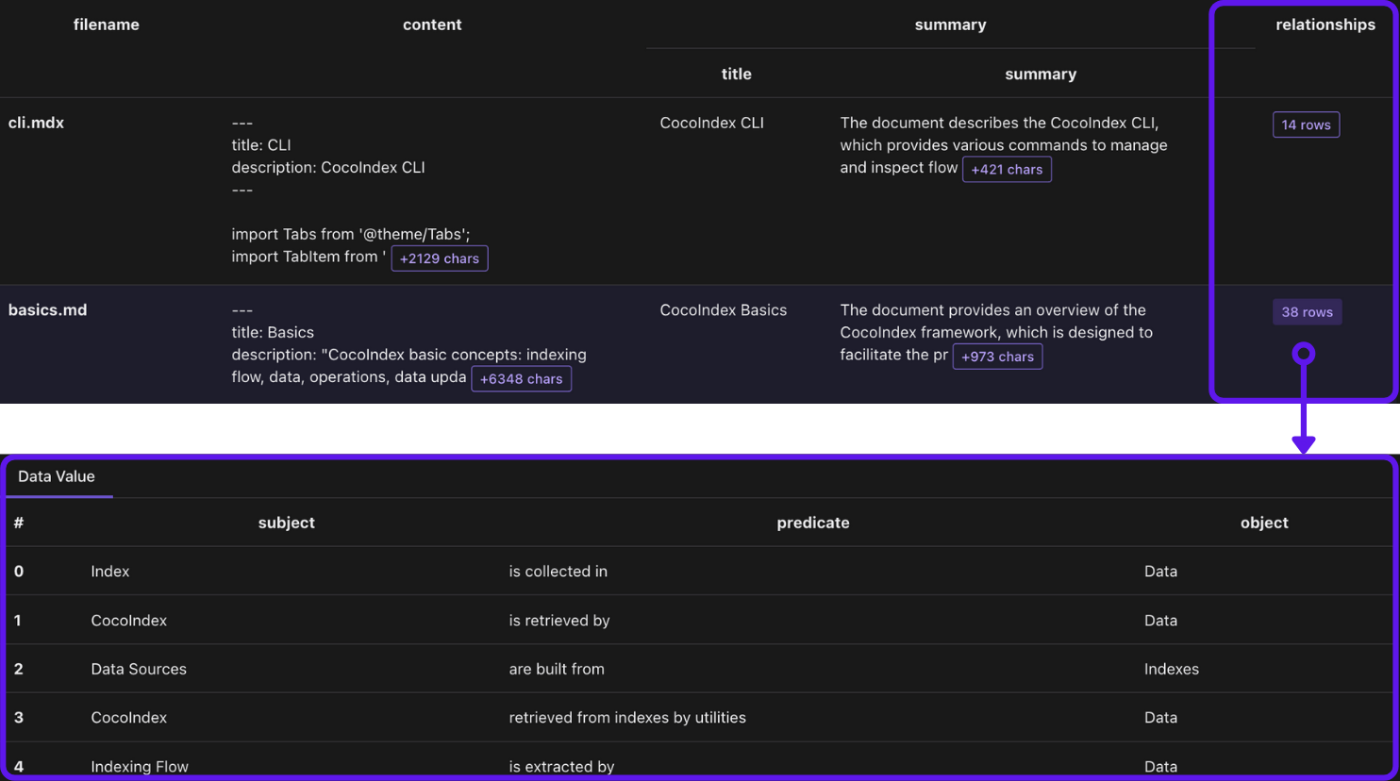
関係を収集する
with doc["relationships"].row() as relationship:
# relationship between two entities
entity_relationship.collect(
id=cocoindex.GeneratedField.UUID,
subject=relationship["subject"],
object=relationship["object"],
predicate=relationship["predicate"],
)
# mention of an entity in a document, for subject
entity_mention.collect(
id=cocoindex.GeneratedField.UUID, entity=relationship["subject"],
filename=doc["filename"],
)
# mention of an entity in a document, for object
entity_mention.collect(
id=cocoindex.GeneratedField.UUID, entity=relationship["object"],
filename=doc["filename"],
)
-
entity_relationshipはサブジェクトとオブジェクトの間の関係を収集します。 -
entity_mentionはドキュメント内のエンティティ(サブジェクトまたはオブジェクト)の言及を収集します。例えば、core/basics.mdxにはCocoIndex supports Incremental Processingの文があります。次のように収集します:-
core/basics.mdxはCocoIndexに言及しています。 -
core/basics.mdxはIncremental Processingに言及しています。
-
ナレッジグラフを構築する
基本的な概念
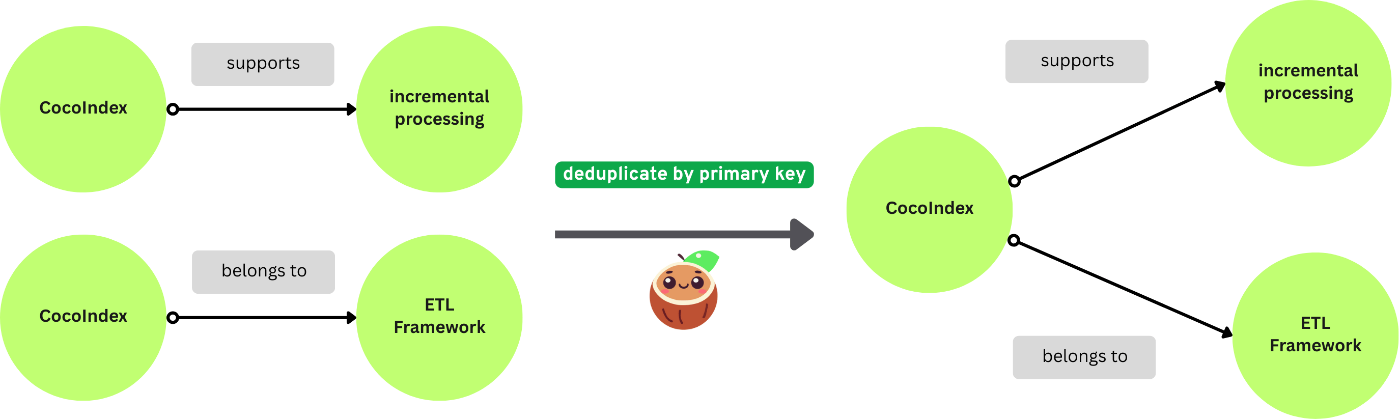
Neo4j のすべてのノードには2つのものが必要です:
- ラベル:ノードのタイプ。例:
Document、Entity。 - 主キーフィールド:ノードを一意に識別するフィールド。例:
Documentノードのfilename。
CocoIndex は主キーフィールドを使用してノードを照合し、重複を削除します。同じ主キーフィールドを持つ複数のノードがある場合、CocoIndex はそのうちの1つを保持します。
ノードをマッピングする2つの方法があります:
- ノードのコレクターがある場合、直接 Neo4j にエクスポートできます。
- ノードに接続するリレーションシップのコレクターがある場合、リレーションシップのコレクターから選択したフィールドを使用してノードをマッピングできます。ノードラベルと主キーフィールドを宣言する必要があります。
Neo4j 接続を構成する
conn_spec = cocoindex.add_auth_entry(
"Neo4jConnection",
cocoindex.storages.Neo4jConnection(
uri="bolt://localhost:7687",
user="neo4j",
password="cocoindex",
))
Neo4j に Document ノードをエクスポートする

document_node.export(
"document_node",
cocoindex.storages.Neo4j(
connection=conn_spec,
mapping=cocoindex.storages.Nodes(label="Document")),
primary_key_fields=["filename"],
)
これは document_node コレクターからラベル Document の Neo4j ノードをエクスポートします。
- ラベル
Documentの Neo4j ノードを宣言します。filenameを主キーフィールドとして指定します。 -
document_nodeコレクターからラベルDocumentの Neo4j ノードにすべてのフィールドを持っていきます。
Neo4j に RELATIONSHIP と Entity ノードをエクスポートする

Entity ノードの明示的なコレクターはありません。
これらは entity_relationship コレクターの一部であり、関係抽出中に収集されます。
Neo4j ノードとしてエクスポートするには、まず Entity ノードを宣言する必要があります。
flow_builder.declare(
cocoindex.storages.Neo4jDeclaration(
connection=conn_spec,
nodes_label="Entity",
primary_key_fields=["value"],
)
)
次に、entity_relationship を Neo4j にエクスポートします。
entity_relationship.export(
"entity_relationship",
cocoindex.storages.Neo4j(
connection=conn_spec,
mapping=cocoindex.storages.Relationships(
rel_type="RELATIONSHIP",
source=cocoindex.storages.NodeFromFields(
label="Entity",
fields=[
cocoindex.storages.TargetFieldMapping(
source="subject", target="value"),
]
),
target=cocoindex.storages.NodeFromFields(
label="Entity",
fields=[
cocoindex.storages.TargetFieldMapping(
source="object", target="value"),
]
),
),
),
primary_key_fields=["id"],
)
)
cocoindex.storages.Relationships は Neo4j でリレーションシップをマッピングする方法を宣言します。
リレーションシップには:
- ソースノードとターゲットノード。
- ソースとターゲットを接続するリレーションシップ。
異なるリレーションシップが同じソースとターゲットノードを共有する場合があります。
NodeFromFields は entity_relationship コレクターからフィールドを取得し、Entity ノードを作成します。
Neo4j に entity_mention をエクスポートする
entity_mention.export(
"entity_mention",
cocoindex.storages.Neo4j(
connection=conn_spec,
mapping=cocoindex.storages.Relationships(
rel_type="MENTION",
source=cocoindex.storages.NodesFromFields(
label="Document",
fields=[cocoindex.storages.TargetFieldMapping("filename")],
),
target=cocoindex.storages.NodesFromFields(
label="Entity",
fields=[cocoindex.storages.TargetFieldMapping(
source="entity", target="value")],
),
),
),
primary_key_fields=["id"],
)
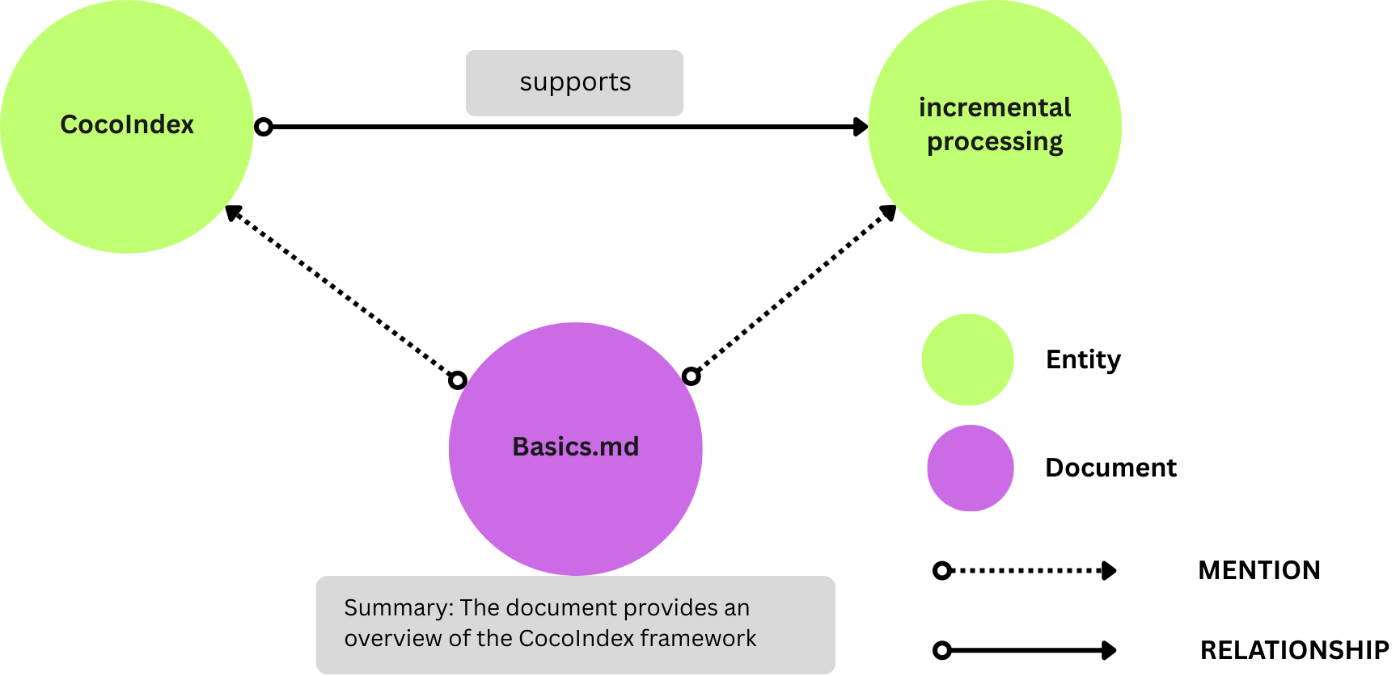
同様に、cocoindex.storages.Relationships を使用して entity_mention を Neo4j リレーションシップにエクスポートします。
これは次のようにリレーションシップを作成します:
-
entity_mentionコレクターからDocumentノードとEntityノードを作成します。 -
DocumentノードとEntityノードをリレーションシップMENTIONで接続します。
フローのメイン関数
最後に、フローのメイン関数は CocoIndex フローを初期化し、実行します。
@cocoindex.main_fn()
def _run():
pass
if __name__ == "__main__":
load_dotenv(override=True)
_run()
インデックスをクエリしてテストする
🎉 これですべての設定が完了しました!
-
依存関係をインストールします:
pip install -e . -
次のコマンドを実行してインデックスをセットアップして更新します。
python main.py cocoindex setup python main.py cocoindex updateターミナルでインデックスの更新状態を確認できます。例えば、次のような出力が表示されます:
documents: 7 added, 0 removed, 0 updated -
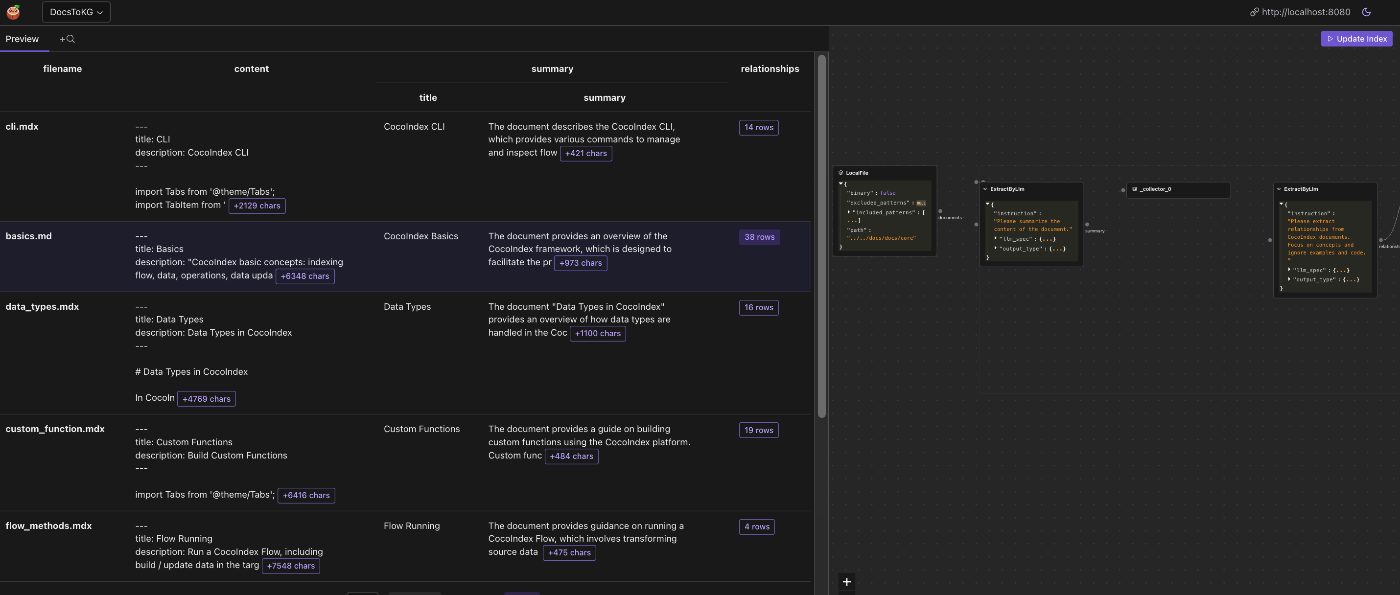
(オプション)CocoInsight を使用してインデックスの生成をトラブルシューティングし、パイプラインのデータラインを理解します。
現在は無料でベータ版です。CocoIndex サーバーに接続し、ゼロのパイプラインデータ保存を使用します。
次のコマンドを実行して CocoInsight を開始します:python3 main.py cocoindex server -c https://cocoindex.ioAnd then open the url https://cocoindex.io/cocoinsight.
ナレッジグラフを探索する
ナレッジグラフが構築されたら、Neo4j Browser で構築したナレッジグラフを探索できます。
開発環境では、資格情報を使用して Neo4j Browser に接続できます:
- ユーザー名:
Neo4j - パスワード:
cocoindex
これは config.yaml で事前に設定されています。
Neo4j Browser を http://localhost:7474 で開き、次の Cypher クエリを実行してすべてのリレーションシップを取得します:
MATCH p=()-->() RETURN p

サポートしてください
私たちは常に改善を続けており、さらに多くの機能と例が近日中に公開される予定です。
この記事がお好きなら、GitHub リポジトリ でスターを付けて私たちを支援してください。
ありがとうございました!
Discussion