ローカルで始めるエッジAI MLOps:M5Stackで快適度予測システムの構築【環境センサー×TensorFlow Lite】
はじめに
MLOPSとは「機械学習モデルを作って終わりじゃなくて、実際に動かし続けるための仕組み」です。
MLOPSを必要最低限の構成でデータ通信費・学習コストがかからないように構築しました。Wifi環境やラズパイ、M5STACKやセンサーは必要です。。。
この記事で説明すること
・クラウド(データ通信、学習費用)費用は一切かかりません
・ラズパイでモデルを学習するため、GPU付きクラウドインスタンス不要
・毎日決まった時刻にモデルが自動で再学習・デプロイされる
・環境センサーで快適度を予測する実践的なユースケース
この記事で説明しないこと
・MLOPSのセキュリティ関連は説明していません。
必要なもの
ハードウェア:
ソフトウェア:
- Python 3.x(ラズパイ側)
- Arduino IDE + M5Stackライブラリ
- TensorFlow / Keras
- 無料のAMBIENTアカウント
費用:
- ハードウェア代
- wifi通信料
-データ通信料・学習費用: ¥0/月
システムの構成要素について
1. エッジデバイスでの推論(M5Stack)
M5Stack上でTensorFlow Lite Microを使い、リアルタイムに環境データから快適度を予測します。センサーから取得した温度・湿度・気圧データを使って、WBGT(暑さ指数)とTHI(不快指数)を計算し、過去24時点のデータを使った時系列予測を行います。予測結果は画面に表示され、ユーザーは現在の環境が快適かどうかを判断できます。
2. 無料クラウドでのデータ蓄積(AMBIENT)
AMBIENTの無料枠(3,000データポイント/日)を使い、センサーデータをクラウドに保存します。M5StackからWiFi経由で60秒ごとにデータを送信し、Web APIで簡単にデータを取得できます。
ここでは学習処理は行わず、データの保存のみに使用します。これにより、クラウドでの計算コストを完全にゼロにできます。
IoTデータの可視化サービス
3. ローカルでのモデル学習とデプロイ(Raspberry Pi)
学習処理を全てラズパイで実行することで、クラウドコンピューティング費用をゼロにします。
今回の設定では毎日深夜3時(時刻は変更可能)に自動で以下が実行されます:
システム構成図の説明
以下が今回構築するシステムの全体構成です。
システムフロー詳細
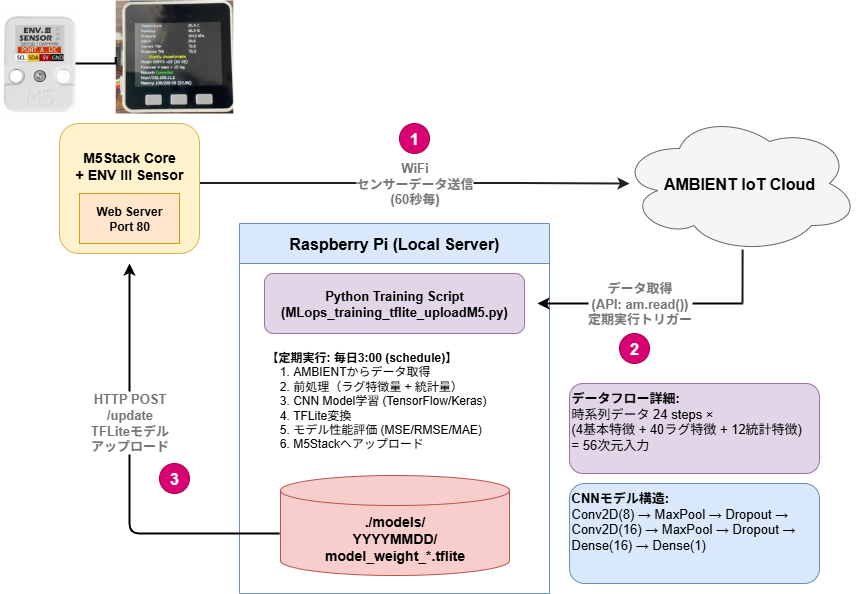
センサーデータ取得と推論
M5StackはENV IIIセンサーから環境データ(温度・湿度・気圧)を取得し、ローカルで推論を実行します。
データ取得の仕組み:
センサーから取得した生データを使って、まず暑さ指数(WBGT)と不快指数(THI)を計算します。これらの指数は、単なる温度だけでなく、湿度も考慮した人間が感じる快適さの指標です。
// 暑さ指数(WBGT)の計算例
WBGT = (temperature * 0.003289 + 0.01844) * humidity +
(0.6868 * temperature - 2.022);
// 不快指数(THI)の計算例
THI = (temperature * 0.81 + humidity * 0.01 *
(temperature * 0.99 - 14.3) + 46.3);
取得したデータはリングバッファに保存され、時系列データとして管理されます。このバッファが24時点分のデータで満たされたら、推論を開始します。
特徴量エンジニアリングの工夫:
単にセンサーの値を使うだけでなく、より予測精度を高めるために以下の特徴量を作成します:
- 基本特徴量(4次元): 温度、湿度、気圧、WBGT
- ラグ特徴量(40次元): 過去10時点のデータ(4特徴 × 10時点)
- 統計量(12次元): 移動平均、標準偏差、範囲(4特徴 × 3統計量)
合計で56次元の入力特徴量を作成します。これにより、単なる現在の値だけでなく、時間的な変化のパターンも学習できます。
推論の実行:
TensorFlow Lite Microを使って、M5Stack上で直接推論を実行します。作成した特徴量をテンソルにコピーし、モデルを実行すると、将来の不快指数が予測されます。予測結果は正規化された値として出力されるため、元のスケールに戻して表示します。
データのクラウド送信
60秒ごとにセンサーデータと推論結果をAMBIENTに送信します。WiFi接続が確立している場合のみ送信を行い、ネットワークエラーに対応します。
送信するデータは以下の通りです:
- d1: 温度
- d2: 湿度
- d3: 気圧
- d4: 暑さ指数(WBGT)
- d5: 不快指数(THI) - これが正解ラベルとなります
- d6: 予測値(モデルが予測した不快指数)
void sendToAmbient() {
if (WiFi.status() == WL_CONNECTED) {
ambient.set(1, temperature);
ambient.set(2, humidity);
ambient.set(3, pressure);
ambient.set(4, WBGT);
ambient.set(5, THI); // 正解ラベル
if (predicted_comfort > 0) {
ambient.set(6, predicted_comfort); // 予測値
}
ambient.send();
}
}
このようにして、実測値と予測値の両方を記録することで、後からモデルの性能を評価できます。
定期学習(Raspberry Pi)
毎日深夜3時に自動でモデル学習が実行されます。Pythonのscheduleライブラリを使って、指定した時刻に処理を自動実行します。
学習プロセスの詳細:
1. データ取得
AMBIENTのAPIを使って、蓄積されたセンサーデータを取得します。取得したデータはPandas DataFrameに変換し、カラム名をわかりやすい名前にマッピングします。
# カラム名のマッピング例
column_mapping = {
'd1': 'temp', # 温度
'd2': 'humi', # 湿度
'd3': 'atm', # 気圧
'd4': 'hot', # WBGT
'd5': 'uncon', # THI(正解ラベル)
'created': 'timestamp'
}
2. 特徴量エンジニアリング
M5Stack側と同じ特徴量を作成します。これにより、学習時と推論時で同じデータ表現が使われ、モデルが正しく動作します。
ラグ特徴量は、Pandasのshift関数を使って簡単に作成できます。例えば、1時点前のデータはX['temp_lag_1'] = X['temp'].shift(1)のように作成します。
統計量はrolling関数を使って計算します。移動平均、標準偏差、範囲(最大値-最小値)を5時点のウィンドウで計算します。
作成した特徴量は正規化(Min-Maxスケーリング)を行い、0から1の範囲に収めます。これにより、学習が安定し、収束が速くなります。
3. CNNモデルの構築
時系列データに対して2D畳み込みを適用するCNNモデルを構築します。モデルの構造は以下の通りです:
- 入力: (24時点, 56特徴, 1チャンネル)
- Conv2D層1: 8フィルタ、カーネルサイズ(4, 3)
- MaxPooling層1: プールサイズ(3, 3)
- Dropout層1: 0.1
- Conv2D層2: 16フィルタ、カーネルサイズ(4, 1)
- MaxPooling層2: プールサイズ(3, 1)
- Dropout層2: 0.1
- Flatten層
- Dense層1: 16ユニット
- Dropout層3: 0.1
- 出力層: 1ユニット(回帰問題)
Dropoutを各層に入れることで、過学習を防ぎ、汎化性能を向上させます。
4. 学習の実行
Early Stoppingを使って、検証損失が改善しなくなったら学習を早期終了します。これにより、無駄な計算時間を削減し、最良のモデルを自動的に保存できます。
学習が完了したら、テストデータで評価を行い、MSE(平均二乗誤差)、RMSE(二乗平均平方根誤差)、MAE(平均絶対誤差)を計算します。これらの指標をログに記録することで、モデルの改善状況を追跡できます。
5. TensorFlow Lite変換
学習したKerasモデルをTensorFlow Lite形式に変換します。M5Stack(ESP32)で動作させるため、以下の設定を行います:
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # TFLiteの標準演算
tf.lite.OpsSet.SELECT_TF_OPS # 一部のTensorFlow演算も許可
]
変換されたモデルはバイナリファイルとして保存され、元のKerasモデルよりもサイズが小さく、推論速度も高速化されます。
モデルのアップロード
学習が完了したら、HTTP POST経由でM5Stackにモデルをアップロードします。
アップロードの仕組み:
Pythonのrequestsライブラリを使って、TFLiteモデルファイルをM5StackのWebサーバーに送信します。M5Stack側では、受信したファイルを一時ファイル(/model.tflite.new)として保存します。
アップロードが完了したら、以下の処理を行います:
- モデルバージョン番号をインクリメント
- 既存のモデルをバックアップ(
.bak拡張子) - 新しいモデルを有効化
- 自動再起動
// バージョン更新
modelVersion++;
saveModelVersion(modelVersion);
// 新旧ファイルの入れ替え
if(SPIFFS.exists("/model.tflite")) {
SPIFFS.remove("/model.tflite.bak");
SPIFFS.rename("/model.tflite", "/model.tflite.bak");
}
SPIFFS.rename("/model.tflite.new", "/model.tflite");
再起動後、M5Stackは新しいモデルをロードして推論を開始します。もし新モデルに問題があれば、バックアップから復元できます。
定期実行の設定:
Pythonのscheduleライブラリを使って、毎日指定した時刻に学習を実行します。
# 毎日3時に実行
schedule.every().day.at("03:00").do(trainer.run_training_and_upload)
# 無限ループで待機
while True:
schedule.run_pending()
time.sleep(60) # 1分ごとにチェック
スクリプト起動時に初回学習も実行するため、システムを立ち上げた直後からモデルが利用可能になります。
まとめ
本記事では、エッジAI MLOpsシステムを構築する方法を解説しました。
・クラウド費用¥0: AMBIENTの無料枠でデータ蓄積
・ ローカル学習: ラズパイで全ての学習処理を実行
・ 自動化: 毎日決まった時刻にモデルが自動更新
・ エッジ推論: M5Stack上でリアルタイム予測
・ 実用的: 環境センサーによる快適度予測という実用例
Discussion