はじめに
株式会社BTMの藤野です!
正規表現はソースコードの調査やデータの整形などでよく使うのですが、最近後読みについて使う機会があったので、先読みも含めて使い方を調べて纏めてみました。
正規表現の先読みと後読みの概要
正規表現における先読みと後読みは、指定したパターンがマッチする直前や直後に特定の条件が成立するかを確認できる記法です。
また、それぞれ肯定と否定があります。
(と言葉で説明しても良くわからないと思います、私もわかりません)
先読み
パターンがマッチした位置の直後に指定した条件が続くか、続かないかを確認します。
肯定先読みは (?=pattern) で、否定先読みは (?!pattern) で表記します。
肯定先読み
パターンがマッチした位置の直後に指定した条件が続くかを確認します。
例:ab(?=c) => ab の直後に c が存在する場合にのみマッチする

使用例
指定した単位の数字部分のみをマッチさせる
- パターン
\d+(?=円) - データ
100ドル 1000円 10000ペソ - 結果
下記のように単位が円であるデータの数字部分がマッチしました。
これはわかりやすいですね。
(この時円部分はマッチ対象外となります。)

否定先読み
肯定先読みとは反対で、パターンがマッチした位置の直後に指定した条件が続かないかを確認します。
ただ個人的に、肯定先読みと違い狙ったデータをマッチさせるのが難しい印象です。
例:ab(?!c) => ab の直後に c が存在しない場合にのみマッチする

使用例
指定した単位以外の数字部分のみをマッチさせる
-
パターン
\d+(?!.*円) -
データ(肯定先読みと同様のデータです)
100ドル 1000円 10000ペソ -
結果
下記のように単位が円以外であるデータの数字部分がマッチしました。
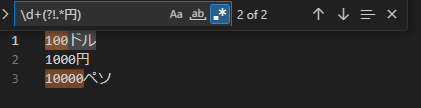
※ 単純に肯定先読みで使用したパターンを否定にするだけの
\d+(?!円)では円以外の値にマッチできませんでした。
これは数値部分の最終桁以外は円が直後に無くマッチしてしまうためです。

使用例で示したパターンでは
.*円とすることで円が続くいかなる文字列も否定させることで円以外の数値部分にマッチさせることができました。
後読み
パターンがマッチした位置の直前に指定した条件が存在するか、しないかを確認します。
肯定後読みは (?<=pattern) で、否定先読みは (?<!pattern) で表記します。
肯定後読み
パターンがマッチした位置の直前に指定した条件が存在するかを確認します。
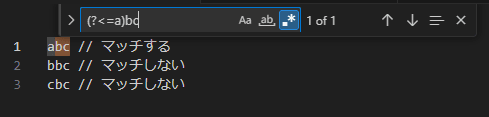
例:(?<=a)bc => bc の直前に a が存在する場合にのみマッチする
使用例
指定した都道府県から始まるデータの都道府県より後のデータをマッチさせる
- パターン
(?<=東京都)[一-龯]+ - データ
東京都葛飾区 大阪府大阪市北区 兵庫県神戸市兵庫区 神奈川県横浜市青葉区 東京都渋谷区 - 結果
下記のように東京都から始まるデータの東京都より後の文字列がマッチしました。

否定後読み
パターンがマッチした位置の直前に指定した条件が存在しないかを確認します。
否定後読みも個人的に難しい印象です
例:(?<!a)bc => bc の直前に a が存在しない場合にのみマッチする

使用例
ソースコード上のコメント以外の日本語文字列部分にマッチさせる
- パターン
(?<!\/\/.*)[あ-んア-ン一-龯]+ - データ
// ひらがな const a_gyo = "ひらがな" // カタカナ const ka_gyo = "カタカナ" // 漢字 const sa_gyo = "漢字" - 結果
下記のように//から始まるデータ以外の日本語にマッチしました

※ ただし、否定後読み中に*等の文字数が可変するような記法は使うエディタなどによってはエラーとなる可能性があります。(VSCode の「Find」機能ではうまくいきますが「Search」機能ではエラーとなりました)
その他の使用例
HTMLで指定したタグ内の値のみをマッチさせる
- パターン
(?<=<tag[^>]*>)[\s\S\r\n]+?(?=</tag>)
※tag部分には対象とするタグ名を指定します
-
データ
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title>HTMLサンプル</title> </head> <body> <div class="container"> <h1>サンプルページ</h1> <p>これは<span>サンプルです</span></p> <p>これも<span>サンプルです</span></p> </div> <div class="sub"> div の内容 </div> </body> </html> -
結果
肯定先読みと肯定後読みを組み合わせることでHTML上の特定の値のみをマッチさせることができました。-
divを指定した場合(
(?<=<div[^>]*>)[\s\S\r\n]+?(?=</div>))

-
spanを指定した場合(
(?<=<span[^>]*>)[\s\S\r\n]+?(?=</span>))

-
まとめ
正規表現の後読みと先読みはそれぞれ肯定と否定があります。
肯定はわかりやすい印象ですが否定は少しわかりにくかったです。
理解するのと使い慣れるまで時間がかかるかもしれませんが、慣れると効率的に処理できることも多くなるんじゃないかと思います。
私もまだまだ慣れていないので積極的に使っていきたいです!

Discussion