AWS で実現する高可用性 入門
はじめに 🐈⬛
「サイトが見れない😱‼️」
ある日突然、あなたのサービスでこんな事態が起きたら…?
これは他人事ではありません。クラウドサービスが普及した今でも、大規模なシステム障害は実際に起きています。
この記事では、「なぜ障害は起きるのか?」という基本から、障害に負けないシステムを作るための「高可用性(こうかようせい)」という考え方をご紹介します。
なぜシステム障害は起きるの? 🤔
実際に発生した大規模障害事例 📰
2019年 東京リージョン
冷却システムの故障によりEC2が7時間停止。日常的に利用されている決済サービスが軒並み停止しました。
2021年 東京リージョン
AWS Direct Connectサービスが6時間中断。この障害により、金融機関や航空会社などの一部システムに影響が発生しました。
障害から学ぶ 💡
同じ障害に見舞われても、「すぐに復旧するパターン」と「長時間停止するパターン」があります。この差は、一般的に以下のような「備え」の有無によるものと考えられています。
障害の影響が少ないサービスの特徴 ✅
- 分散配置:設備を複数のデータセンターに分けている
- 自動切り替え:障害時に自動で予備に切り替わる仕組みがある
障害の影響が大きいサービスの特徴 ❌
- 一点集中:設備が一つのデータセンターに集中している
- 手動での対応:障害時の切り替えが自動化されていない
この差が、「高可用性」という考え方の重要性を示しています。
💡アベイラビリティゾーン(AZ)とマルチAZ
ここで言う「データセンター」は、AWSではアベイラビリティゾーン(AZ)と呼ばれます。AZは、それぞれが独立した電源やネットワークを持つデータセンター群のことです。そして、複数のAZにシステムを分散させて配置する構成のことをマルチAZ構成と呼び、これがAWSにおける障害対策の基本となります。
障害はなくせない、でも備えはできる 🛡️
システム障害の原因は様々です。
- 機器の故障(サーバー、ネットワーク機器など)
- ソフトの問題(プログラムのバグ、設定ミス)
- 外部の要因(自然災害、停電)
どんなに優れたシステムでも、障害を100%防ぐことは困難です。
サーバー1台だけでウェブサイトを運用している場合、その1台が故障すると、サービスは完全に停止してしまいます。復旧には何時間、場合によっては何日もかかり、深夜の緊急対応に追われるといった事態にもなりかねません。
「障害はいつか必ず起きる」という前提で、被害を最小限に抑えるための「備え」が大切になります。
障害に強くするには?「高可用性」の考え方 💪
「高可用性」とは✨
「高可用性」とは、システムが「いつでも使える」状態を保つ能力のことです。万が一の障害でもサービスが止まらないようにする仕組みで、その強さは「稼働率」で示されます。例えば「稼働率99.9%」は、年間の停止時間が9時間未満であることを意味します。
どうやって実現するの❓
高可用性の基本は「冗長化」、つまり予備を用意しておくことです。
- Active-Standby:普段はメイン機だけが動き、故障したら予備機に自動で切り替わる。
- Active-Active:普段から複数台が一緒に動き、負荷を分散させながらお互いをカバーする。
これを実現するために、以下のようなAWSのサービスがよく利用されます。
- ロードバランサー (Elastic Load Balancing):アクセスを複数のサーバーにうまく振り分ける司令塔。
- フェイルオーバー (Route 53, RDS Multi-AZなど):障害を検知して、自動で予備機に切り替える仕組み。
- データ同期 (RDS Multi-AZなど):複数のデータベースの中身を常に同じ状態に保つこと。
イメージ図
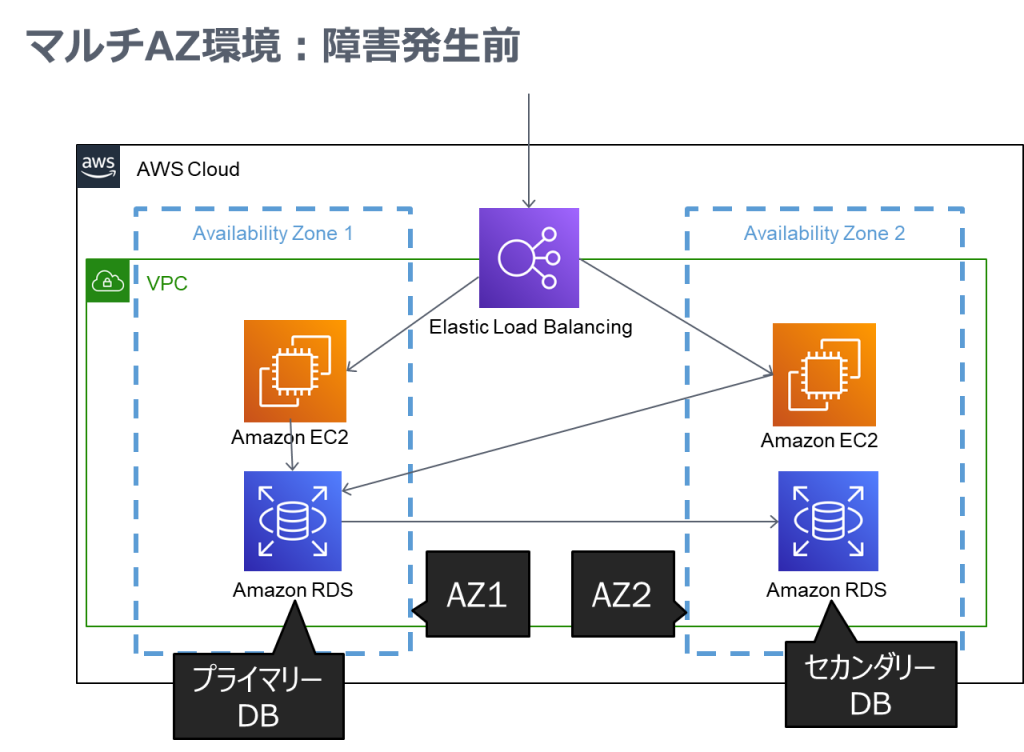

引用:Amazon RDSマルチAZ とリードレプリカの違い、高可用性と読み取りスケーリングの違いを理解する
高可用性のメリット・デメリット ⚖️
| メリット ❤️ | デメリット 💔 | |
|---|---|---|
| サービス | 障害が起きても止まらない | 仕組みが複雑になる |
| ユーザー | 障害に気づかず利用できる | (特になし) |
| 運用・費用 | 緊急対応が減る | サーバー代などの費用が約2倍になる |
高可用性を追求すると費用はかかりますが、サービス停止による機会損失や信頼の低下を防げる大きなメリットがあります。
実装でつまずきやすい技術的なポイント 🔧
高可用性の構成を組む際には、技術的な課題に直面することがあります。特にAWSで構築する際に注意したい点をご紹介します。
- セッション情報の管理:ユーザーのログイン情報などをサーバー内で管理している場合、障害でサーバーが切り替わるとセッションが維持できません。これを防ぐには、Amazon ElastiCache for Redisのような外部の専用サービスでセッションを一元管理する工夫が求められます。
- 古いシステムへの配慮:長年使われているシステムは、高可用性を前提とした設計になっていないことが多く、改修が難しい場合があります。
- バッチ処理の考慮:高可用性構成では、バッチが複数サーバーで二重実行される問題が起こるため、処理をWebサーバーから切り離し、AWS FargateやAWS Batchなどで独立して動かす必要があります。
段階的に進める場合の目標設定(RTOの目安) 🎯
いきなり完璧な高可用性を目指すのが難しい場合、RTO(目標復旧時間)を指標に、ステップごとの目標を立てるのがおすすめです。RTOとは「障害発生後、どれくらいの時間でサービスを復旧させるか」という目標時間のことです。
ステップ1:手動での復旧を目指す(RTOの目安:障害検知から数時間~1日)
- やること:定期的なバックアップ(AMIやEBSスナップショット)を取得し、障害時に手動で復旧できる手順を確立する。
- 効果:最悪の事態(データ消失、長期間の停止)を防ぐための基本です。
ステップ2:切り替えを半自動化する(RTOの目安:障害検知から数分~1時間)
- やること:予備のサーバー(スタンバイ機)を別のデータセンター(AZ)に用意し、障害時にはスクリプトなどで比較的スムーズに切り替えられるようにする。
- 効果:復旧作業が迅速化され、深夜の緊急対応などの負担が大きく減ります。
ステップ3:完全自動化で瞬時に復旧(RTOの目安:数秒~数分)
- やること:障害の検知から復旧までを完全に自動化する。(例:ALB + 複数のAZにまたがるAuto Scaling Group + Multi-AZ構成のRDS)
- 効果:ユーザーが障害に気づかないレベルでのサービス継続が実現できます。
高可用性検討の進め方 📊
ここまでの内容を、簡単なフローにすると以下のようになります。

まとめ 🤝
この記事では、システム障害の現実から、それに対する「高可用性」という備えの考え方、そして自社の状況に合わせた検討の進め方までを解説してきました。
サーバー費用が約2倍になるなど、高可用性の実現にはコストがかかります。しかし、サービスが停止することで売上や顧客の信頼に大きな影響が出るのであれば、それは「コスト」ではなく、未来の安心を守るための重要な「投資」と言えるでしょう。
まずは、
- 自分たちのサービスにとって、どのくらいの停止時間なら許容できるか?(RTO)
- そのために、どのレベルの備え(手動復旧 or 自動化)が必要か?
を検討することから始めてみてください。
この記事がサービスに最適な「障害への備え」を考える、はじめの一歩となれば幸いです🚀
Discussion