AWS S3 [1]

初めましてのS3。
今日も自分なりにまとめていこう...
S3
"Amazon Simple Storage Servise"のこと。
これは、データの保存や格納を簡単に行える
"オブジェクトストレージ("オブジェクト"と言う単位で扱う記憶装置。データサイズやデータ数の保存制限がないため、大容量データの保存に適す。)"で、
AWSサービスのデータ格納先として使われる。
データやファイルを格納できるだけでなく
耐久性や拡張性などの面でも優れている。
Amazon S3特徴
- 容量無制限
- 高度な耐久性
- 使いやすい価格
- スケーラブルで安定した性能
どのようなファイル数やサイズ、リクエスト数であっても一定性能を発揮できるように、複数のストレージクラスが用意されている。(必要な性能やディスク容量を考える必要がない。)
レイテンシ
データ転送における指標の1つ。データ転送の要求を出してから、実際に結果が返ってくるまでにかかる時間のこと。
"レイテンシが低い(小さい)"= 遅延が短いことを指す。いいことってこと。
スループット
一定の時間内にどれだけの量のデータを転送できるか表したもの。
値が大きいほど性能の高いストレージ。
ストレージ比較
オブジェクトストレージ
それぞれのデータを"オブジェクト単位"で記憶するストレージ。
各データには、メタデータ(データについてのデータ)をつけて管理する。
ファイルの読み書きには、httpやhttpsが使われるので、"レイテンシは高くなる"が、大容量ストレージの構築に向いてる。
ブロックストレージ
データを"ブロック"の集合体として管理するストレージ。
OSはブロックストレージをファイルシステムとしてフォーマットし、"ファイル単位"で操作できるようにする。
OSに物理的または、高速ネットワークで接続することにより、低いレイテンシを実現できる。
レイテンシ
データ転送における指標の1つ。データ転送の要求を出してから、実際に結果が返ってくるまでにかかる時間のこと。
"レイテンシが低い(小さい)"= 遅延が短いことを指す。いいことってこと。
ファイルストレージ
NFSやSMBなどのファイル共有プロトコルによってファイルを管理するストレージ。
ネットワークプロトコルが介在する分、"レイテンシが高くなる"
Amazon Elastic File System(EFS)は、NFSを使用するファイナルストレージ。
NFSとは
Network File Systemの略。
コンピューターネットワークを通じて別々のマシン間でファイルを共有できるようにするプロトコル。
NFSはリモートのファイルをローカルにあるように扱うことができ、まるで自分のマシンにファイルが存在するかのように作業できる。
SMBとは
"ネットワークを通じてコンピューター間で、データやリソースを共有するための中核となるもの"
主にwindowsベースのシステムとその他のシステムとの間での、
データ通信を可能にするためのプロトコル。
"SMBプロトコル"は、
クライアントとサーバー間でのファイルや印刷データの共有、それらのシリアルポートを通じた通信をサポートしている。
SMBは、OSI(Open System Interconnection)モデルのセッション層で動作するため、特定のネットワーク層のプロトコルに依存することなく独立して」動作できるのが特徴。
文字だけだと、理解しづらいため、図。
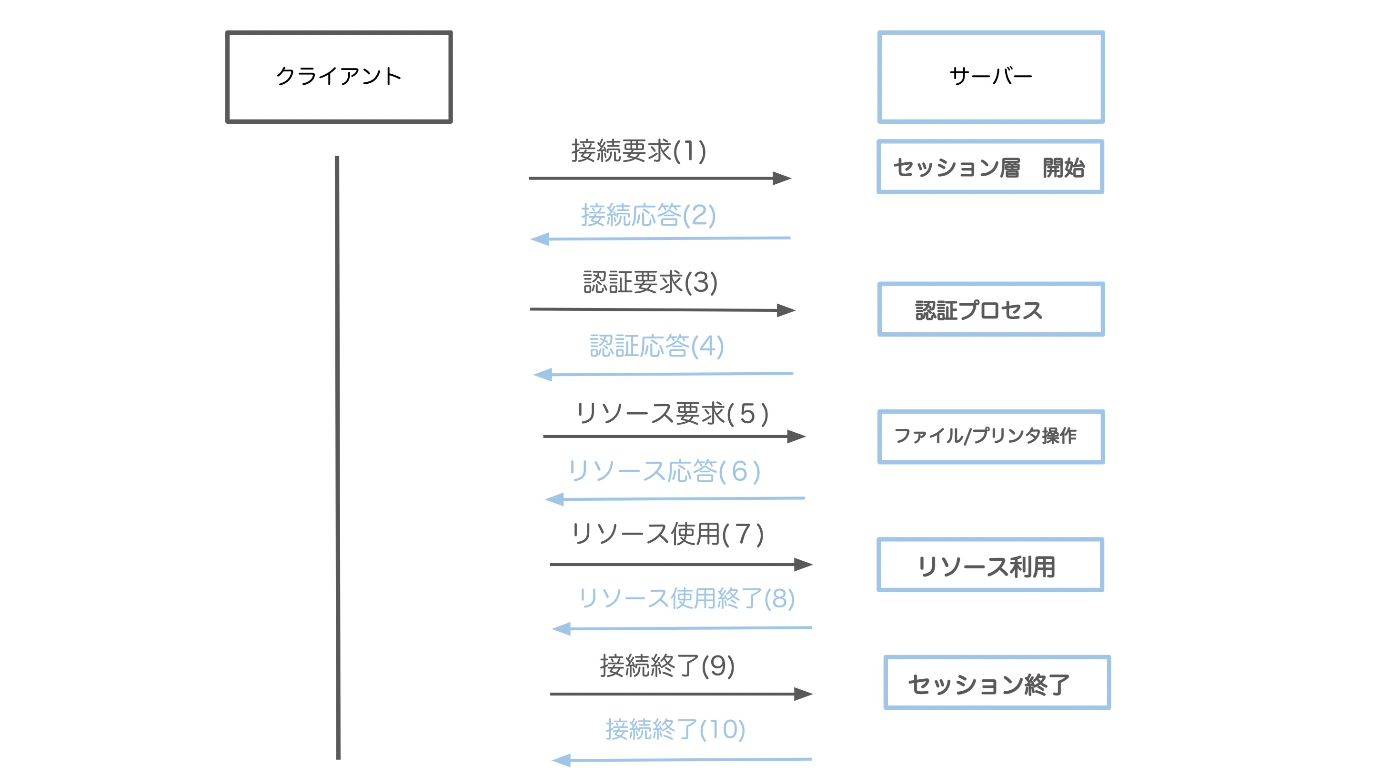
- 図のように、セッション層で動作するSMBプロトコルは、単一の接続要求だけでなく、複数のステップを含む一連の通信手順を経て動作する。
- これにより、セキュアかつ効率的なリソース共有が実現される。
S3の高い信頼性
・ S3に保存されるデータは、"最低3つのアベイラビリティゾーン"に、自動的に保存される。
・ また、1つのアベイラビリティゾーンに保存されたファイルは、複数のデバイス上に保存されるため、どれか1つに障害が発生したとしても、使い続けることができる。
(一部該当しないS3ストレージクラスもある。)
用語
バケット🧺
・ オブジェクト(物)の保存場所。
・ AWSアカウント内に複数作成できる。
・ バケット名は、必ずグローバルに「一意(ユニーク)」にする。
・ バケット名は、バケット内のオブジェクトにアクセスする際のURLの一部として、そのまま利用できる。
オブジェクト
・クラスとかインスタンスとかファイルとか要は、作った"物"って考えるとわかりやすい。
・ バケット名に保存されているファイル本体
・ 1つのバケットに格納できるオブジェクト数は無制限、ファイルサイズは5TBまで。
キー
・オブジェクトの識別子
オブジェクト名は、
バケット名+キー+バージョンの組み合わせで、必ず一意。
メタデータ
・ オブジェクトに付属する属性情報。名前と値のセット...
"システム定義"メタデータ と、
"ユーザー定義"メタデータがある。
S3の整合性
S3は、複数の場所にデータを複製することで、
サービスの可用性(システムが継続して稼働できる能力)と、
信頼性を高めている。
以前は、データの更新や削除は、
すぐに上書きされず結果的に反映される結果整合性(Eventual Consistency)と言うモデルをサポートしていたけど、
アップデートにより、更新後すぐに最新バージョンのデータに反映されるようになる、
強い一貫性(Strong Consistency)と言うモデルをサポートするようになった。
ストレージクラス
オブジェクトへのアクセス頻度や冗長性(余裕がある・二重化など)に応じて、ストレージのクラスを選択できる。
これによって、コストを抑えることができる。

※S3 Glacierは、バックアップなどアクセスがほとんどないオブジェクトを格納する
S3アーキテクチャ(要はS3の構造/構成)
表面上は全く見えないが、
AmazonS3は以下のようなアーキテクチャ(構造/構成)
をAWSリージョンに展開して提供している。
<仕組みのイメージ>

[流れ]
・ エンドユーザーは、S3オブジェクトを操作する為に、リクエストを発行。
・ リクエストはインターネットを経由してS3のリージョンごとのロードバランサに到達する(ロードバランサは、S3のエンドポイントと呼ばれる)
・ ロードバランサは、いずれかのAPIサーバーにリクエストを転送する
・ APIサーバーは、
「メタデータを操作する場合は、"メタデータストレージ"」
「ファイル本体を操作する場合は、"BLOBストレージ"」
に、アクセスし、エンドユーザーがリクエストした処理を実行する。
S3ファイル操作の特徴
S3のバケット🧺にアクセスするツールは、いくつかあるけど、
それぞれのツールの機能はこれらの操作に対応するか、
操作の組み合わせになっている。
GET
・ オブジェクトを "ダウンロードする" (S3バケットでキーを指定)
・ ファイルの一部だけをダウンロードすることも可能
PUT
・ オブジェクトを "アップロードする" (S3バケットでキーを指定)
・ 1回のPUT(アップロード)で、最大5GBまでアップロードできる。
・ 5GB以上の場合は、
オブジェクトをいくつかに分けて、
複数回アップロードして結合する。(マルチパートアップロード)
・ マルチパートアップロードでは、5TB(5120GB)までアップロードできる
LIST
・ S3バケット内のオブジェクト "一覧を取得する"
・ キー名に「Prefix」をつけると、その「Prefix」を持つオブジェクトだけに限定できる。
・ 1回のオペレーションで、最大1000オブジェクトまで取得できる
COPY
・ S3内のオブジェクトを"複製する"
・ 転送は、サーバー間で行われる
・ 異なる*ロケーション間でコピーすると、帯域料金が発生する。
* ロケーションは、データ配信の速度を向上させるための拠点のこと。
(リージョンは、複数のデータセンター。データとアプリケーションを運用するための拠点。)
DELETE
・ 任意のオブジェクトを "削除する"
・ 1回のオペレーションで、複数のオブジェクトをまとめて削除できる。
HEAD
・ オブジェクトの"メタデータを取得する"
RESTORE(復元)
・ Glacierにアーカイブされているオブジェクトを"復元"。
上記オペレーションを行える状態にする
SERECT
・ CSV、JSON、Parque形式のオブジェクトに対して、SQL(言葉)クエリ(命令)を実行して、抽出し、結果を得る。
・ 複数のオブジェクトを一括で変更する *バッチオペレーションがある。多くのオブジェクトに同じ処理を繰り返し行うときは、バッチオペレーションも検討する必要がある。
* バッチオペレーションとは、AmazonS3のデータ管理機能のこと。Amazon S3マネジメントコンソールから、単一のAPIリクエストによって、数十億個ものオブジェクトを大規模に管理できる。
CSV / JSON / Parque

S3の操作実践
- バケットを作成して、PUT(アップロード)、GET(ダウンロード)を試す。
PUT(アップロード)ver.
- サービス検索で、S3を検索。クリック。
- バケットを一度も作成していないときは、[バケットを作成する]をクリック
- バケット名🧺を入力する。
バケット名は、他と重複しない名前で設定する必要がある。エラーが表示された場合には、他の名前を試す。
[ブロックパブリックアクセスのバケット設定]や、バケットのバージョニングなどは、デフォルトのまま進めてよい。(今は) - [バケット作成]をクリック
- S3ダッシュボードに戻ると、作成されたバケットが表示される。
- ここで、PUTの作業。
[アップロード]をクリックして、ファイルをアップロードする。
バケット名をクリックしても、バケットには、まだ何もアップロードしてないので中身は空。 - [アップロード]をクリックすると、アップロード用のウィンドウが表示される。
任意のファイルを選択して追加する。(複数選択可能)。 - [アップロード]をクリック忘れないように!
(忘れると、ただファイル選択されただけで終わっている。)
GET(ダウンロード)ver.
上記で、アップロードしたファイル名部分をクリックすると、メタ情報が表示される。
- 概要タブの[ダウンロード]をクリック
- ブラウザが起動して、ダウンロードが始ま理、ローカルフォルダにファイルが保存される。これで、GET(ダウンロード)操作は完了。
今日は、ここまで...。
む、難しすぎる...。
Discussion