FastAPIとPostgreSQLで実践的な開発:複数モデルの管理とデータベース操作の実装
初めに
前回の記事では、FastAPI と SQLAlchemy を使用して基本的なデータベース操作を行う方法を探りました。また、Alembic を通じて、データベースマイグレーションの設定方法についても詳細に解説しました。これらの基礎知識については、前回の記事で詳しく説明していますので、まだご覧になっていない方は是非一度ご覧ください。
この記事では、更に一歩進み、FastAPI と SQLAlchemy を使用してよりより実践的なデータベース操作を実行するテクニックに焦点を当てます。具体的には、以下のトピックについて探求していきます。
-
複数モデルの管理:
システムが成長するにつれて、複数のモデルが存在するようになります。これらのモデル間には、多くの場合、様々なリレーションシップが形成されます。このセクションでは、これらの複雑なリレーションシップを効果的に管理し、操作する方法について学びます。 -
データベース操作の実装:
基本的なデータベースのクエリの他に、より複雑なクエリの作成方法について学びます。これには、レコードの追加、更新、削除、取得が含まれます。SQLAlchemy には、これらのタスクを簡単かつ効率的に行うための多くのツールと機能が用意されています。
1: 複数モデルの管理とリレーションシップ
前回の記事では、基本的なUserモデルを作成しました。今回は、このUserモデルを基に、新たに2つのモデルを作成し、それらの間のリレーションシップを構築します。具体的には、PostモデルとCommentモデルを作成し、これらのモデルをUserモデルと関連付けます。
1.1 Postモデルの作成
まず、app/modelsディレクトリの下にpost.pyを作成し、各ユーザーが作成できるPostモデルを作成します。
import uuid
from datetime import datetime
from sqlalchemy import Column, DateTime, ForeignKey, String
from sqlalchemy.orm import relationship
from app.db.base_class import Base
class Post(Base):
__tablename__ = "posts"
id = Column(String, primary_key=True, default=lambda: str(uuid.uuid4()))
user_id = Column(String, ForeignKey("users.id"), nullable=False)
title = Column(String(100), nullable=False)
content = Column(String(1000), nullable=False)
created_at = Column(DateTime, default=datetime.utcnow)
updated_at = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
user = relationship("User", back_populates="posts")
comments = relationship("Comment", back_populates="post")
このPostモデルは、user_idを外部キーとしてUserモデルにリンクします。また、Userモデル内でpostsとCommentモデル内でpostとして逆リレーションシップを設定します。
コードの詳細説明
-
__tablename__ = "posts": このクラスがデータベース内でどのテーブルに対応するかを指定しています。ここではpostsテーブルと定義しています。 -
id = Column(String, primary_key=True, default=lambda: str(uuid.uuid4())):postsテーブルにはidという名前のカラムが存在し、これがテーブルの主キー(primary_key)となります。主キーは、テーブル内の各行を一意に識別するためのキーです。
uuid4()関数を使用して一意のUUIDを生成し、それを文字列に変換してidカラムのデフォルト値として設定します。これにより、新しいPostオブジェクトが作成される際に、idが指定されなければ、一意のidが自動的に生成されます。 -
title = Column(String(100), nullable=False): この行は、titleという名前のカラムを定義しています。nullable=Falseはこのカラムが空の値を許さないことを意味します。 -
content = Column(String(1000), nullable=False): ここでは、contentという名前のカラムを定義しています。このカラムもnullable=Falseなので空の値(null)は許されません。また、文字列(String)で1000字以内でないといけません。 -
created_atおよびupdated_atカラム: これらは、ポストが作成された日時や更新された日時を保持します。default=datetime.utcnowは、デフォルトで現在のUTC時刻が設定され、onupdate=datetime.utcnowは、行が更新されるたびに現在のUTC時刻で更新されます。
1.2 Commentモデルの作成
次に、app/modelsディレクトリの下にcomment.pyを作成し、各Postに対してユーザーが追加できるCommentモデルを作成します。
import uuid
from datetime import datetime
from sqlalchemy import Column, DateTime, ForeignKey, String
from sqlalchemy.orm import relationship
from app.db.base_class import Base
class Comment(Base):
__tablename__ = "comments"
id = Column(String, primary_key=True, default=lambda: str(uuid.uuid4()))
user_id = Column(String, ForeignKey("users.id"), nullable=False)
post_id = Column(String, ForeignKey("posts.id"), nullable=False)
content = Column(String, nullable=False)
created_at = Column(DateTime, default=datetime.utcnow)
updated_at = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
user = relationship("User", back_populates="comments")
post = relationship("Post", back_populates="comments")
このCommentモデルは、user_idとpost_idを外部キーとして、それぞれUserモデルとPostモデルにリンクします。また、UserモデルとPostモデル内で、それぞれcommentsとして逆リレーションシップを設定します。
コードの詳細説明
-
__tablename__ = "comments": このクラスがデータベース内でどのテーブルに対応するかを指定しています。ここではcommentsテーブルと定義しています。 -
id = Column(String, primary_key=True):commentsテーブルにはidという名前のカラムが存在し、これがテーブルの主キーとなります。
uuid4()関数を使用して一意のUUIDを生成し、それを文字列に変換してidカラムのデフォルト値として設定します。これにより、新しいCommentオブジェクトが作成される際に、idが指定されなければ、一意のidが自動的に生成されます。 -
content = Column(String, nullable=False): この行は、contentという名前のカラムを定義しています。nullable=Falseはこのカラムが空の値を許さないことを意味します。 -
created_atおよびupdated_atカラム: これらは、コメントが作成された日時や更新された日時を保持します。default=datetime.utcnowは、デフォルトで現在のUTC時刻が設定され、onupdate=datetime.utcnowは、行が更新されるたびに現在のUTC時刻で更新されます。
1.3 リレーションシップの構築
これらのモデルが作成された後、SQLAlchemyのrelationship機能を使用して、各モデル間のリレーションシップを定義します。具体的には、Userモデルに以下のようにリレーションシップを追加します。
import uuid
from datetime import datetime
from app.db.base_class import Base
from sqlalchemy import Column, DateTime, String
from sqlalchemy.orm import relationship
class User(Base):
__tablename__ = "users"
id = Column(String, primary_key=True, default=lambda: str(uuid.uuid4()))
name = Column(String(20), nullable=False, default="default_name")
created_at = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
updated_at = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
posts = relationship("Post", back_populates="user")
comments = relationship("Comment", back_populates="user")
これにより、一つのUserが複数のPostを持ち、一つのPostが複数のCommentを持つ、という一対多のリレーションシップが構築されます。
また、PostやCommentと同様にidをUUIDを用いて一意に定まるようにしました。
1.4 モデルのインポートと初期化
FastAPIやSQLAlchemyを使用する際、モデル間にリレーションシップがある場合、それぞれのモデルは適切にインポートされる必要があります。これによって、SQLAlchemyはモデル間のリレーションシップを適切に設定し、エンティティ間のマッピングを構築することができます。
例えば、UserモデルがPostモデルやCommentモデルとリレーションシップを持っている場合、これらのモデルも適切にインポートされる必要があります。これは通常、models パッケージの__init__.py ファイル内で行われます。
# app/models/__init__.py
from .user import User
from .post import Post
from .comment import Comment
このようにすることで、アプリケーションが起動し、モデルがロードされる際に、関連する全てのモデルが一緒にロードされます。これにより、SQLAlchemyはモデル間のリレーションシップを正しく解決し、適切に初期化できます。
なぜこれが必要なのか?
SQLAlchemyは、宣言的なモデル定義を使用して、Pythonオブジェクトとデータベーステーブルをマッピングします。これにより、Pythonコード内でデータベース操作をより簡単に、より「Pythonic」に行うことができます。しかし、これらのモデルが相互に関連している場合、一つのモデルを使用する前に、関連する全てのモデルが正しくインポートされ、初期化されている必要があります。これによって、リレーションシップが正しく設定され、エンティティ間で正確な参照が可能になります。
例えば、UserモデルがPostモデルにリレーションシップを持っている場合、Userインスタンスを通じて関連するPostインスタンスにアクセスすることができます。しかし、Postモデルが正しくインポートされていないと、SQLAlchemyはUserとPost間のリレーションシップを正しく解決できません。このため、モデル間のリレーションシップが存在する際には、関連する全てのモデルを適切にインポートすることが極めて重要です。
用語説明
エンティティ(Entity):
エンティティは、データベースに格納される「もの」または「オブジェクト」を指します。例えば、ユーザー情報やブログ投稿などがエンティティとなります。データベースにおいて、各エンティティは一意のデータを持ち、他のエンティティと関連付けることができます。この関連付けが、リレーションシップです。
参考リンク:
Pythonic:
「Pythonic」という言葉は、Pythonプログラミング言語の哲学やアイディアを表現するために使われます。Pythonには、「シンプルで読みやすく、明示的であること」が重視されています。Pythonicなコードは、Pythonのコーディング規約や慣習に従っており、他のPython開発者にとって読みやすく、理解しやすいコードです。Pythonicなコードを書くことで、コードがクリーンでメンテナンスしやすくなり、バグの発生リスクが低減します。
1.5 外部キーとリレーションシップの説明
1.5.1 外部キー
外部キーは、あるテーブルのカラムが他のテーブルの特定のカラム(主に主キー)を参照することを意味します。外部キーの使用によって、異なるテーブル間でのデータの整合性が保たれます。SQLAlchemyでは、ForeignKeyクラスを使用して外部キーを定義します。
例えば、Commentモデルにおいて、以下のようにuser_idとpost_idを外部キーとして定義しています。
user_id = Column(String, ForeignKey("users.id"), nullable=False)
post_id = Column(String, ForeignKey("posts.id"), nullable=False)
ここで、ForeignKey("users.id")は、このカラムがusersテーブルのidカラムを参照することを意味します。
1.5.2 リレーションシップ
リレーションシップは、モデル間の関連性を定義するためのものです。SQLAlchemyのrelationship関数を用いて、モデル間のリレーションシップを定義できます。リレーションシップには一対一、一対多、多対多など、さまざまなタイプが存在します。
例えば、UserモデルとPostモデル間では、一人のユーザーが複数のポストを持つことができるため、一対多のリレーションシップを定義します。
class User(Base):
# ... other fields ...
posts = relationship("Post", back_populates="user")
この例では、relationship("Post", back_populates="user")によって、UserモデルとPostモデル間のリレーションシップが定義されています。back_populates="user"は、Postモデル側でも相互にアクセスできるように設定するためのものです。もちろん、Postモデルにuserというリレーションシップ関係がないといけません。
back_populatesはオプションで、指定しないと一方向のリレーションシップのみが設定されます。これは便利である一方で、双方向にアクセスする必要がない場合は、指定しない方が適切かもしれません。
1.5.3 リレーションシップの利用
リレーションシップが定義されると、各モデルインスタンスを通じて関連するオブジェクトにアクセスできます。たとえば、あるユーザーが作成した全てのポストを取得するには、以下のようにアクセスできます。
user = session.query(User).first() # sessionはSQLAlchemyのセッションオブジェクト
users_posts = user.posts
同様に、あるポストに対する全てのコメントを取得するには、以下のようにアクセスできます。
post = session.query(Post).first()
posts_comments = post.comments
これにより、異なるテーブル間のデータを効率的かつ直感的に扱うことができます。
2章: マイグレーションとデータベースの更新
先ほど作成したPostモデルとCommentモデルをデータベースに反映させるために、再びマイグレーションを行います。マイグレーションは、モデルの変更をデータベースに適用するための重要なプロセスであり、新しいモデルの追加や既存モデルの変更をデータベースに適用することができます。
2.1 マイグレーションの準備
まず、マイグレーションを行うために、migration/env.py ファイルに新しく作成したモデルをインポートします。このインポートにより、Alembicはこれらのモデルの存在を認識し、マイグレーションファイルを生成できるようになります。
migration/env.pyに以下の行を追加します。
from app.models.post import Post # noqa
from app.models.comment import Comment # noqa
2.2 マイグレーションの実行
新しいモデルをインポートしたら、次にマイグレーションファイルを生成します。プロジェクトディレクトリで以下のコマンドを実行して、マイグレーションファイルを作成します。
pipenv run alembic revision --autogenerate -m "add post and comment models"
生成されたマイグレーションファイルには、新たに追加されたPostモデルとCommentモデルに基づいて、postsテーブルとcommentsテーブルが作成されるSQL文が含まれています。
次に、以下のコマンドを実行して、マイグレーションをデータベースに適用します。
pipenv run alembic upgrade head
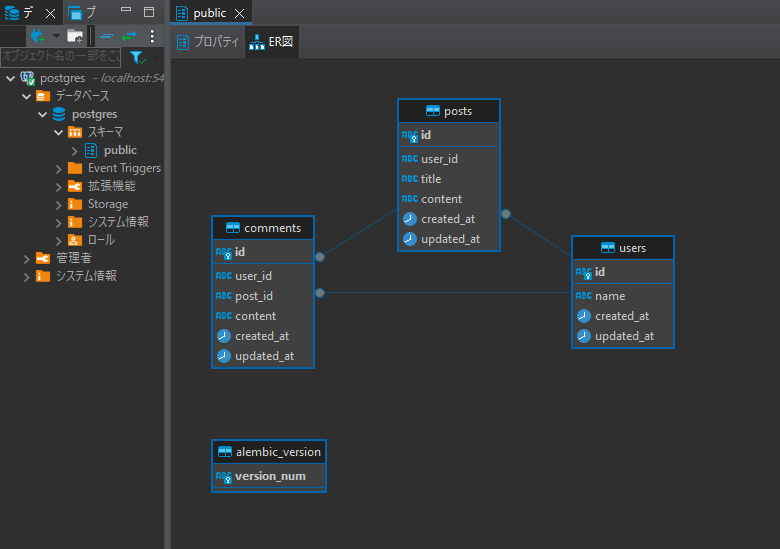
2.3 DBeaverでの確認
マイグレーションが完了したら、DBeaverを使用してデータベースを確認します。DBeaverを開いて接続し、新しく作成されたpostsテーブルとcommentsテーブルが存在することを確認します。また、これらのテーブルの構造が定義したモデルと一致していること、外部キーが正しく設定されていることも確認します。
これにより、新たに作成したPostモデルとCommentモデルがデータベースに反映され、これらのモデルを使用してデータベース操作を行うことができるようになります。
以上で、新しいモデルの作成とマイグレーションのプロセスは完了です。次のセクションからは、実際にバックエンドのロジックを考えていきます。
3章: バックエンドのロジックの基礎構築
次のセクションではバックエンドのロジックを考えていきます。まずは、中身のないエンドポイントを作成し、アプリケーションの基本構造を整えます。
3.1 基本設定の変更
まずはじめに、app 直下の main.py ファイルを以下のように編集します。
from fastapi import FastAPI
from app.core.config import settings
app = FastAPI(
title=settings.PROJECT_NAME, openapi_url=f"{settings.API_V1_STR}/openapi.json"
)
この段階での変更はこれだけですが、この状態ではまだアプリケーションには何もエンドポイントが存在していません。
コードの詳細説明
-
app = FastAPI(title=settings.PROJECT_NAME, openapi_url=f"{settings.API_V1_STR}/openapi.json"): この行は、FastAPIのインスタンスを作成し、APIの基本設定を行っています。以下、パラメータの詳細です。-
title=settings.PROJECT_NAME:titleパラメータは、APIのタイトルを設定します。この場合、settings.PROJECT_NAMEからプロジェクト名を取得し、APIのタイトルとして設定しています。 -
openapi_url=f"{settings.API_V1_STR}/openapi.json":openapi_urlパラメータは、OpenAPIのスキーマ定義を取得できるURLを設定します。
この場合、f"{settings.API_V1_STR}/openapi.json"でURLを動的に生成しています。settings.API_V1_STRは、APIのバージョン1に対応するURLのプレフィックス(例えば/api/v1)を含みます。これにより、OpenAPIのスキーマ定義が特定のURLからアクセス可能になります。
-
3.2 APIディレクトリの作成とバージョン管理
先ほどまでと同様に、全てのエンドポイントを main.py に書くとコードが冗長になりますので、より整理された構造を作ります。具体的には、appの下にapiフォルダを作り、その下にさらにapi_v1フォルダを作ります。そして、これらのフォルダには__init__.pyファイルを作成し、フォルダがPythonパッケージとして認識されるようにします。
app/
└── api/
├── __init__.py
└── api_v1/
└── __init__.py
ここで、「なぜapi_v1のようにバージョンで分けるのか?」という疑問が生まれるかもしれません。これは、将来的にAPIのバージョンがアップデートされた場合に、既存のコードの変更を最小限に抑えるためです。例えば、api_v2フォルダを新たに作成し、バージョン1とは異なる機能やエンドポイントを提供することができます。このようにバージョンごとにフォルダを分けることで、異なるバージョンのAPIを同時に管理・運用することが可能になります。
3.3 エンドポイントの設定とメインアプリケーションの更新
次に、api_v1フォルダにapi_router.pyを作成します。また、api_v1フォルダ内にendpointsフォルダを作成し、その中に__init__.pyファイルとusers.pyファイルを作成します。
users.pyでは、以下のように空のGETエンドポイントを設定します。
from fastapi import APIRouter
router = APIRouter()
@router.get("/")
async def read_users():
return {"message": "This is an empty endpoint"}
次に、api_router.pyでこのエンドポイントをインクルードします。
from fastapi import APIRouter
from app.api.api_v1.endpoints import users
router = APIRouter()
router.include_router(users.router, prefix="/users", tags=["users"])
この設定により、/users/へのGETリクエストに対して、指定したメッセージが返されます。
ここでのinclude_routerメソッドは、特定のルータ内の全てのルーティングを、指定したプレフィックスとタグを使用してインクルードします。これにより、APIのエンドポイントが整理され、管理しやすくなります。
::details 今回の例では
include_routerメソッドは、FastAPIで提供される強力な機能の一つで、開発者がAPIの構造をモジュール化し、整理するのを助けます。具体的には、別のファイルに定義されたルート(エンドポイント)を、主APIルータに簡単に組み込むことができます。これにより、APIの各セクションを個別のファイルで管理し、プロジェクトの構造をクリーンに保つことができます。
この機能を使用する主な利点は、APIのセクションごとに別々のルーターを作成し、それぞれを独立して開発・テストすることができる点にあります。最終的にこれらのルーターをメインのアプリケーションルーターに統合することで、大規模なプロジェクトでも管理しやすいAPIを構築できます。
上記のコード例では、users.pyファイル内に定義されたrouterオブジェクト(users.routerとして参照)をapi_router.pyファイルのメインルーターに組み込んでいます。include_routerメソッドを使用して、/usersというURLプレフィックスと"users"というタグをこのルーターに割り当てます。
-
prefix="/users": このパラメータにより、users.router内で定義された全てのエンドポイントのURLが/usersで始まるようになります。例えば、users.py内の@router.get("/")は/users/のURLでアクセス可能になります。 -
tags=["users"]: このパラメータは、OpenAPIドキュメント(Swagger UIなど)で関連するエンドポイントをグループ化するのに役立ちます。これにより、ドキュメントがより読みやすく、使いやすくなります。
この方法で、FastAPIアプリケーションの各部分を分離して管理することができ、各セクションを独立して開発し、後で統合することが容易になります。これは、特にチームで作業する場合や、大規模なAPIプロジェクトを管理する場合に非常に便利です。
:::
最後に、main.pyを更新して、作成したrouterをインクルードします。
from fastapi import FastAPI
from app.api.api_v1.api_router import router
from app.core.config import settings
app = FastAPI(
title=settings.PROJECT_NAME, openapi_url=f"{settings.API_V1_STR}/openapi.json"
)
app.include_router(router, prefix=settings.API_V1_STR)
main.pyにrouterをインクルードすることで、アプリケーションは新しく定義したエンドポイントを認識し、settings.API_V1_STRをプレフィックスとして使用します。これにより、例えばsettings.API_V1_STRが"/api/v1"であれば、/usersエンドポイントは/api/v1/usersとしてアクセス可能になります。この変更により、APIのバージョン管理が容易になり、ルーティングが正確に行われるようになります。
3.4 エンドポイントの動作確認
新しく作成したエンドポイントが正しく機能しているかを確認します。backendディレクトリで以下のコマンドを実行して、FastAPIアプリケーションを起動します。
pipenv run uvicorn app.main:app --reload
アプリケーションが起動したら、ブラウザを開いてhttp://127.0.0.1:8000/docsにアクセスします。/docsはFastAPIが提供する自動生成されたAPIドキュメントで、Swagger UIを通じてAPIの詳細を確認できます。
ここで/api/v1/users/エンドポイントにアクセスし、GETメソッドを試してみます。正しく設定されていれば、設定したレスポンスが返されることを確認できます。
写真付き説明
アプリケーションが起動したら、ブラウザを開いてhttp://127.0.0.1:8000/docsにアクセスします。

ここで出てくる画面は、FastAPIによって自動生成されたAPIドキュメントで、Swagger UIを通じて、利用可能なエンドポイントとその仕様を確認できます。
GETタブをクリックして開きます。
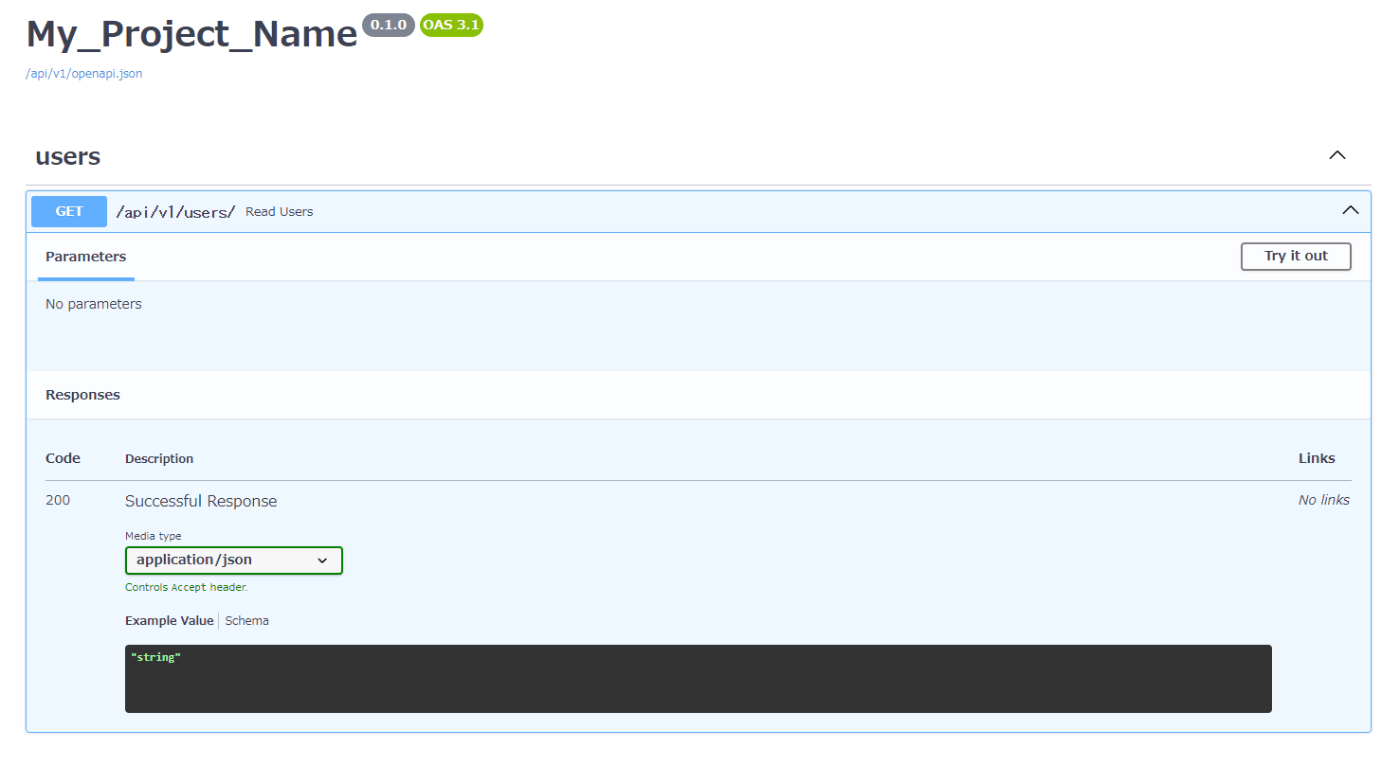
その後、Try it outボタンを押すと、Executeボタンが現れます。Executeボタンを押して、リクエストを送信します。
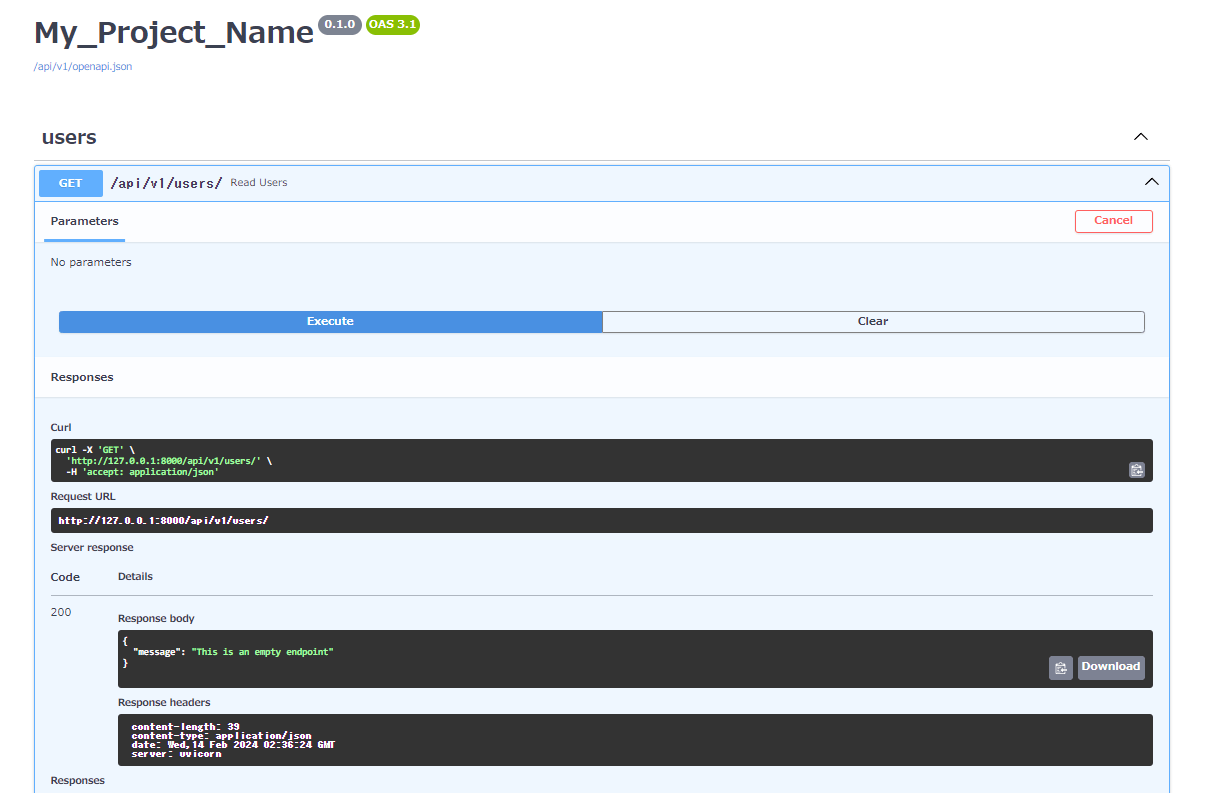
正しく実行されると、Response codeは200を示し、Response bodyには設定したレスポンスが表示されます。
4: Userエンドポイントの実装
本セクションでは、users.pyにて、Userモデルに対する基本的なCRUDエンドポイントを実装します。これにより、ユーザーの作成、読み込み、更新、削除がAPIを通じて行えるようになります。
4.1 Userエンドポイントの設計
まずは、Userに対する基本的なエンドポイントを考え、それぞれどのようなHTTPメソッドとパスを持つかを決定します。一般的なRESTful APIの設計に従い、以下のようにエンドポイントを設計します。
- ユーザーの作成:
POST /users/ - ユーザーの一覧取得:
GET /users/ - 特定のユーザーの取得:
GET /users/{user_id} - ユーザー情報の更新:
PATCH /users/{user_id} - ユーザーの削除:
DELETE /users/{user_id}
4.2 エンドポイントの実装
設計したエンドポイントをendpointsディレクトリ下のusers.pyに実装します。FastAPIの機能を利用することで、バリデーションやレスポンスの形式定義が簡単に行えます。しかし、まず、リクエストやレスポンスで扱うデータの形式を定義する必要があります。これを行うために、appディレクトリの下にschemasディレクトリを作成し、Pythonがこの新しいディレクトリをパッケージとして認識できるように__init__.pyファイルも作成します。
4.2.1 データベースセッションの依存性
エンドポイントでデータベースとのやりとりを行うために、データベースセッションを提供する依存性を作成します。この依存性は、app/api/deps.pyに作成します。このファイルは、エンドポイントで使用する共通の依存性を管理する場所として利用されます。
deps.pyに以下のコードを追加します。
from typing import Generator
from app.db.session import SessionLocal
def get_db() -> Generator:
"""DB接続を行うジェネレータ関数
Yields:
Generator: DBセッション
"""
try:
db = SessionLocal()
yield db
finally:
db.close()
このget_db関数は、ジェネレータ関数としてデータベースセッションを提供します。この関数が呼び出されると、新しいセッションが作成され、エンドポイントの処理が終了した後にセッションが閉じられます。
DBSessionの依存性注入の利点
DBセッションの依存性注入を使用することで、FastAPIアプリケーションにおけるデータベース操作が大幅に改善され、開発者にとって以下のような多くの利点があります。これらの利点を、具体的な例を交えて説明します。
自動リソース管理
get_db関数は、データベースセッションを安全に開始し、操作が完了したら自動的に閉じます。これにより、データベース接続が不必要に開かれたままになることがなく、リソースリークを防ぐことができます。
例: エンドポイントでデータベースからユーザー情報を取得する場合、get_dbを依存性として使用することで、リクエストごとに新しいデータベースセッションが生成され、処理が終われば自動的にそのセッションが閉じられます。開発者はセッションの開閉を意識する必要がなく、エラーが発生してもセッションは確実に閉じられるため、安全にデータベース操作ができます。
エラーハンドリングの改善
依存性注入を使用することで、エラー発生時のセッション処理がシンプルになります。例外が発生しても、finallyブロックによってデータベースセッションは安全に閉じられるため、例外処理を明確に行うことができます。
テストの容易さ
依存性注入を利用すると、テスト時に実際のデータベースセッションの代わりにモックやファクトリーを簡単に注入できます。これにより、実際のデータベースに影響を与えることなく、エンドポイントの動作をテストすることが可能になります。
例: ユニットテストを行う際、get_db関数の代わりにテスト用のデータベースセッションを生成するモック関数を注入することができます。これにより、テスト中にデータベースの状態を変更しても、テスト終了後に影響が残ることがなく、テストの信頼性が高まります。
コードの再利用性と分離
依存性注入により、データベースセッションの管理ロジックをエンドポイントのビジネスロジックから分離することができます。これにより、データベースセッションを必要とする他のエンドポイントでもget_db関数を再利用でき、DRY(Don't Repeat Yourself)原則に従った開発が可能になります。
例: 複数のエンドポイントでユーザー情報の取得や更新を行う場合、それぞれのエンドポイントでget_dbを依存性として注入することで、一貫したデータベースセッション管理が行えます。これにより、コードの見通しが良くなり、メンテナンスが容易になります。
依存性注入を利用することで、FastAPIアプリケーションのデータベース操作がより効率的かつ安全になり、開発プロセスがスムーズに進むようになります。
4.2.2 Pydanticモデルの定義
次に、リクエストとレスポンスに用いるデータの形式をPydanticモデルを使用して定義します。この定義を行うために、先ほど作成したschemasディレクトリ内に、例えばuser.pyといったファイルを作成し、必要なスキーマを定義します。
from typing import Optional
from pydantic import BaseModel
# ユーザー作成時のスキーマ
class UserCreate(BaseModel):
name: Optional[str] = "default_name"
# ユーザー読み取り時のスキーマ
class UserResponse(BaseModel):
id: str
name: str
model_config = {"from_attributes": True}
model_config = {"from_attributes": True}について
ここでmodel_config = {"from_attributes": True}を設定しています。この設定は、PydanticモデルがORMモデル(例えば、SQLAlchemyモデル)のインスタンスを、その属性を読み取ることで正しく解釈できるようにします。
この設定がない場合、ORMモデルのインスタンスは単に通常のオブジェクトとして扱われ、その属性はPydanticモデルによって読み取られません。これは、FastAPIがデータベースモデルからPydanticモデルへの自動変換を行う際に必要となります。例えば、データベースセッションを通じてデータベースから取得したユーザーモデルのインスタンスを、User Pydanticモデルに変換できるようにするためには、この設定が不可欠です。
model_config = {"from_attributes": True}設定によって、CRUD操作やエンドポイントの実装が、データベースモデルとPydanticモデル間でシームレスに行えるようになります。
__init__.pyの更新について
schemasディレクトリにPydanticモデルを定義した後、これらのスキーマを他の場所で簡単にインポートできるようにするために、schemasディレクトリの__init__.pyファイルを更新することが推奨されます。特に、以下のようなインポートスタイルを適用することが有用です。
from app.schemas.user import * # noqa
この方法では、全てのスキーマを一箇所でインポートし、アプリケーション全体で利用できるようにします。ただし、この方法を採用すると、モデル名が重複する可能性があるため、コードを読む際に、その名前がデータベースモデルを指しているのか、Pydanticスキーマを指しているのかがわかりにくくなることがあります。
この問題を回避するためには、以下のようなインポートスタイルを採用すると良いでしょう。
# 他のファイルでのschemasモジュールの使用例
from app import schemas
このスタイルを使用することで、schemas.Userやschemas.UserCreateのように、スキーマを使用する際に明示的にschemasモジュールを指定することになります。これにより、スキーマかデータベースモデルかが一目でわかり、コードの可読性とメンテナンス性が向上します。
4.2.3 エンドポイントの実装
最後に、app/api/api_v1/endpoints/users.pyにて、エンドポイントを実装します。
ユーザーの作成: `POST /users/`の作成
エンドポイントを実装する前に、必要なCRUD操作を定義します。まず、app/crudディレクトリを作成し、このディレクトリ内で、ユーザーに関するCRUD操作を定義します。ディレクトリを作成したら、その中に__init__.pyファイルを作成し、Pythonがディレクトリをパッケージとして認識できるようにします。
次に、app/crud/user.pyファイルを作成し、以下のようにcreate_user関数を定義します。
from sqlalchemy.orm import Session
from app import (
models, # データベースモデルをインポート
schemas, # 作成したPydanticモデルをインポート
)
def create_user(db: Session, user: schemas.UserCreate) -> models.User:
"""ユーザーを作成するCRUD操作
Args:
db (Session): データベースセッション
user (schemas.UserCreate): 作成するユーザーの情報
Returns:
UserModel: 作成されたユーザーのモデル
"""
db_user = models.User(
**user.model_dump()
) # Pydanticモデルからデータベースモデルを作成
db.add(db_user)
db.commit()
db.refresh(db_user)
return db_user
また、CRUD関数も今までと同様に__init__.pyに追加します。crudディレクトリ下の__init__.pyを以下のように編集します。
from app.crud.user import * # noqa
CRUD関数が準備できたら、次にエンドポイントを実装します。app/api/api_v1/endpoints/users.pyにて、以下のようにエンドポイントを実装します。
from fastapi import APIRouter, Depends, HTTPException
from sqlalchemy.orm import Session
from app import (
crud, # ユーザー作成のロジックを含む関数をインポート
schemas, # 作成したPydanticモデルをインポート
)
from app.api import deps # 作成した依存性をインポート
router = APIRouter()
@router.post("/", response_model=schemas.UserResponse, status_code=201)
async def create_user_endpoint(
user: schemas.UserCreate, db: Session = Depends(deps.get_db)
) -> schemas.UserResponse:
"""ユーザーを作成するエンドポイント
Args:
user (schemas.UserCreate): 作成するユーザーの情報
db (Session, optional): DBセッション. Defaults to Depends(get_db).
Raises:
HTTPException: ユーザーが作成できなかった場合に発生
Returns:
UserResponse: 作成されたユーザーの情報
"""
created_user = crud.create_user(db, user)
if created_user:
return created_user
else:
raise HTTPException(status_code=400, detail="User could not be created")
このエンドポイントでは、ユーザーの作成処理を行い、作成したユーザーの情報を返します。response_modelにはレスポンスとして返すモデルを指定し、status_code=201で、リソースの作成に成功したことをクライアントに通知します。model_config = {"from_attributes": True}の設定により、ORMモデルのインスタンスをPydanticモデルに自動変換して、適切な形式でクライアントに返すことが可能になります。
ユーザーの一覧取得: `GET /users/` の作成
ユーザーの一覧を取得するためのエンドポイントを実装します。まず、app/crud/user.pyに新しいCRUD関数を定義します。
from typing import List
from sqlalchemy.orm import Session
from app import models, schemas
def get_users(db: Session) -> List[models.User]:
"""ユーザーの一覧を取得するCRUD操作
Args:
db (Session): データベースセッション
Returns:
List[models.User]: 取得されたユーザーの一覧
"""
return db.query(models.User).all()
次に、app/api/api_v1/endpoints/users.pyに新しいエンドポイントを追加します。
from typing import List
from fastapi import APIRouter, Depends, HTTPException
from sqlalchemy.orm import Session
from app import (
crud, # ユーザー作成のロジックを含む関数をインポート
schemas, # 作成したPydanticモデルをインポート
)
from app.api import deps # 作成した依存性をインポート
router = APIRouter()
@router.get("/", response_model=List[schemas.UserResponse])
async def read_users(db: Session = Depends(deps.get_db)) -> List[schemas.UserResponse]:
"""ユーザーの一覧を取得するエンドポイント
Args:
db (Session, optional): DBセッション. Defaults to Depends(deps.get_db).
Returns:
List[schemas.UserResponse]: 取得されたユーザーの一覧
"""
users = crud.get_users(db)
return users
このエンドポイントによって、クライアントはデータベースに存在するすべてのユーザーの一覧を取得できるようになります。しかし、実際のアプリケーションでは、データベースに大量のユーザーが存在する可能性があります。その場合、一度にすべてのユーザーを取得すると、パフォーマンスの低下やレスポンスタイムの増加を招くことがあります。このような問題を回避するために、ページネーションを実装することが一般的です。ページネーションにより、一度に取得するデータの量を制限し、アプリケーションのパフォーマンスを向上させることができます。しかし、この記事ではページネーションの実装については取り上げません。ページネーションの詳細については、別の記事で詳しく説明する予定です。
また、POSTメソッドのエンドポイントとGETメソッドのエンドポイントが共にURLパス/を使用している点について疑問を持つかもしれません。この構成は実際に問題ありません。FastAPI(および多くのWebフレームワーク)では、同じパスでも異なるHTTPメソッドによって異なる処理を定義することができます。この場合、POST /エンドポイントは新しいユーザーを作成するために使用され、GET /エンドポイントはユーザーの一覧を取得するために使用されます。これにより、リソースに対する異なる操作を明確に区別でき、APIの設計がシンプルかつ直感的になります。
特定のユーザーの取得 `GET /users/{user_id}`の作成
特定のユーザーを取得するためのエンドポイントを実装します。まず、app/crud/user.pyに新しいCRUD関数を定義します。
また、以下からはimport文を省略します。ご了承ください。
def get_user_by_uid(db: Session, user_id: str) -> models.User:
"""ユーザーの詳細を取得するCRUD操作
Args:
db (Session): データベースセッション
user_id (str): 取得するユーザーのID
Returns:
models.User: 取得されたユーザーの情報
"""
return db.query(models.User).filter(models.User.id == user_id).first()
`filter`メソッド
SQLAlchemyのfilterメソッドは、SQLのWHERE句に相当する機能を提供します。これを使用することで、データベースから特定の条件に一致する行を選択的に取得することができます。filterメソッドは、クエリオブジェクトに対して呼び出され、条件式を引数として受け取ります。この条件式は、モデルの属性と比較演算子を用いて定義されます。
filterメソッドの使用例
例えば、models.User.id == user_idという条件式では、models.Userモデルのid属性が、関数に引数として渡されたuser_idと等しい場合に一致するレコードを選択します。この条件に一致するレコードのみがクエリの結果として返されます。
filterメソッドの動作
以下のステップで動作します:
-
条件式の作成:
filterメソッドに渡される条件式を、モデルの属性と比較演算子を使って定義します。この式は、SQLクエリのWHERE句に変換されます。 - クエリの実行: 条件式に一致するレコードをデータベースから選択するためのSQLクエリが実行されます。
-
結果の取得: クエリの実行結果として、条件に一致したレコードがPythonオブジェクトとして返されます。返されるオブジェクトは、指定したモデルクラス(この例では
models.User)のインスタンスです。
次に、app/api/api_v1/endpoints/users.pyに新しいエンドポイントを追加します。
@router.get("/{user_id}", response_model=schemas.UserResponse)
async def read_user(user_id: str, db: Session = Depends(deps.get_db)) -> schemas.UserResponse:
"""ユーザーの詳細を取得するエンドポイント
Args:
user_id (str): 取得するユーザーのID
db (Session, optional): DBセッション. Defaults to Depends(deps.get_db).
Exceptions:
HTTPException: ユーザーが見つからない場合に発生
Returns:
schemas.UserResponse: 取得されたユーザーの情報
"""
user = crud.get_user_by_uid(db, user_id)
if user is None:
raise HTTPException(status_code=404, detail="User not found")
return user
ユーザー情報の更新 `PATCH /users/{user_id}`の作成
特定のユーザーの情報を更新するエンドポイントを作成します。まずは、このエンドポイントのリクエストボディを作成します。schemas/user.pyに以下を追加します。
# ユーザー更新時のスキーマ
class UserUpdate(BaseModel):
name: str
次に、app/crud/user.pyに新しいCRUD関数を定義します。
def update_user(db: Session, user_id: str, user: schemas.UserUpdate) -> models.User:
"""ユーザーを更新するCRUD操作
Args:
db (Session): データベースセッション
user_id (str): 更新するユーザーのID
user (schemas.UserUpdate): 更新するユーザーの情報
Returns:
models.User: 更新されたユーザーの情報
"""
db_user = db.query(models.User).filter(models.User.id == user_id).first()
for key, value in user.model_dump().items():
setattr(db_user, key, value)
db.commit()
db.refresh(db_user)
return db_user
次に、app/api/api_v1/endpoints/users.pyに新しいエンドポイントを追加します。
@router.patch("/{user_id}", response_model=schemas.UserResponse)
async def update_user(
user_id: str, user: schemas.UserCreate, db: Session = Depends(deps.get_db)
) -> schemas.UserResponse:
"""ユーザーを更新するエンドポイント
Args:
user_id (str): 更新するユーザーのID
user (schemas.UserCreate): 更新するユーザーの情報
db (Session, optional): DBセッション. Defaults to Depends(deps.get_db).
Exceptions:
HTTPException: ユーザーが見つからない場合に発生
Returns:
schemas.UserResponse: 更新されたユーザーの情報
"""
# ユーザーが見つからない場合は404エラーを返す
existing_user = crud.get_user_by_uid(db, user_id)
if existing_user is None:
raise HTTPException(status_code=404, detail="User not found")
updated_user = crud.update_user(db, user_id, user)
return updated_user
このエンドポイントの実装では、特定のユーザーの情報を更新する処理を行います。しかし、更新操作を実行する前に、更新対象のユーザーがデータベースに実際に存在するかを確認する必要があります。この確認作業は、existing_user = crud.get_user_by_uid(db, user_id)によって行われます。ユーザーが見つからない場合には、HTTPExceptionを発生させてステータスコード404(Not Found)と共に適切なエラーメッセージを返します。
この手法には、関数の責任を明確に区分するという設計上の意図があります。具体的には、update_user CRUD関数はユーザーの更新処理に専念し、ユーザー存在の確認はエンドポイントのレベルで行うことで、関数ごとに一つの責任を持たせる(シングル・レスポンシビリティ・プリンシプル)ことを目指しています。これにより、コードの可読性が向上し、各関数が独立して動作するためのテストが容易になります。また、将来的に同じCRUD操作を異なる文脈で再利用する際に、より柔軟な対応が可能になります。
ユーザーの削除 `DELETE /users/{user_id}`の作成
ユーザーを削除するためのエンドポイントを実装します。まず、app/crud/user.pyに新しいCRUD関数を定義します。
def delete_user(db: Session, user_id: str) -> models.User:
"""ユーザーを削除するCRUD操作
Args:
db (Session): データベースセッション
user_id (str): 削除するユーザーのID
Returns:
models.User: 削除されたユーザーの情報
"""
db_user = db.query(models.User).filter(models.User.id == user_id).first()
db.delete(db_user)
db.commit()
return db_user
deleteメソッドで、検索されたレコードをデータベースから削除します。その後、commitメソッドで、削除操作がデータベースに永続化されます。返値は削除前の最終状態です。
次に、app/api/api_v1/endpoints/users.pyに新しいエンドポイントを追加します。
@router.delete("/{user_id}", response_model=schemas.UserResponse)
async def delete_user(user_id: str, db: Session = Depends(deps.get_db)) -> schemas.UserResponse:
"""ユーザーを削除するエンドポイント
Args:
user_id (str): 削除するユーザーのID
db (Session, optional): DBセッション. Defaults to Depends(deps.get_db).
Exceptions:
HTTPException: ユーザーが見つからない場合に発生
Returns:
schemas.UserResponse: 削除されたユーザーの情報
"""
# ユーザーが見つからない場合は404エラーを返す
existing_user = crud.get_user_by_uid(db, user_id)
if existing_user is None:
raise HTTPException(status_code=404, detail="User not found")
deleted_user = crud.delete_user(db, user_id)
return deleted_user
レスポンスについて
このエンドポイントの実装では、指定されたユーザーIDに対応するユーザーを削除し、削除されたユーザーの情報をレスポンスとして返しています。しかし、実際のアプリケーションでは、エンドポイントの要件に応じて、異なるレスポンス戦略を採用することがあります。
例えば、削除操作の後に削除されたオブジェクトのデータを返す必要がない場合、ステータスコード200(OK)や204(No Content)のみを返すことが一般的です。204ステータスコードは、リクエストが成功したことを示しつつも、クライアントに返すコンテンツがない場合に特に適しています。
- ステータスコード200 (OK): 操作が成功し、何らかのメッセージや、場合によっては操作に関する追加情報を含むレスポンスボディを返す場合に使用します。
- ステータスコード204 (No Content): 操作が成功したが、レスポンスボディに何も返さない場合に使用します。これは、削除操作のように、サーバー上で何かが成功したが、それについてクライアントに返す具体的なデータがない場合に理想的です。
エンドポイントの実装においては、APIの使用者にとって最も意味のある情報を選択してレスポンスとして提供することが重要です。削除されたエンティティの情報を返すことで、クライアントがどのオブジェクトが削除されたのかを確認できる利点がある一方で、レスポンスとしてステータスコードのみを返すことで、APIのシンプルさと効率性を高めることができます。
最終的なレスポンス戦略は、APIの設計原則、およびエンドポイントを使用するクライアントのニーズに基づいて決定されるべきです。
5章: Postエンドポイントの実装
この章では、Postエンドポイントの実装に移ります。前章でUserエンドポイントについて詳細に説明したように、基本的なCRUD操作とそのエンドポイントの実装方法については既に理解していることとします。このため、Postエンドポイントに関しては、具体的なコード例を一つずつ詳細に解説するのではなく、全体的な設計と実装の流れについて概説します。
5.1 Postエンドポイントの設計
Postに対する基本的なエンドポイントは以下の通りです:
- 投稿の作成:
POST /posts/ - 投稿の一覧取得:
GET /posts/ - 特定の投稿の取得:
GET /posts/{post_id} - 特定のユーザーの投稿を取得:
GET /users/{user_id}/posts - 投稿情報の更新:
PATCH /posts/{post_id} - 投稿の削除:
DELETE /posts/{post_id}
これらのエンドポイントは、Userエンドポイントと同じパターンに従います。ただし、投稿に対する操作では、ユーザーとの関連性を考慮する必要があります。
5.2 エンドポイントの実装ポイント
5.2.1 関連性の管理
Postエンドポイントを実装する際、PostモデルがUserモデルとどのように関連しているかを考慮する必要があります。投稿は特定のユーザーによって作成されるため、投稿を作成、更新するエンドポイントでは、そのユーザーの認証と認可を適切に処理する必要があります(今回は行いません)。
5.2.2 レスポンスの形式定義
投稿データのバリデーションは、Userエンドポイントと同様に重要です。schemasディレクトリ内に適切なPydanticモデルを定義し、リクエストデータの構造と内容を定義します。これにより、APIを通じて返されるデータの形式が統一され、APIの利用者にとって予測可能になります。
`schemas/post.py`
from typing import Optional
from pydantic import BaseModel
class PostBase(BaseModel):
"""投稿のベースモデル"""
title: str
content: str
class PostCreate(PostBase):
"""投稿の作成モデル"""
user_id: str
class PostResponse(PostBase):
"""投稿のレスポンスモデル"""
id: str
user_id: str
model_config = {"from_attributes": True}
class PostUpdate(PostBase):
"""投稿の更新モデル"""
title: Optional[str] = None
content: Optional[str] = None
5.2.3 CRUD操作の実装
crudディレクトリ内に、Postモデルに対するCRUD操作を定義します。これには、データベースセッションを通じてPostモデルのインスタンスを作成、更新、削除、取得する関数が含まれます。これらの関数は、エンドポイントから呼び出され、具体的なデータベース操作を担当します。
`crud/post.py
from sqlalchemy.orm import Session
from app import models, schemas
def create_post(db: Session, post: schemas.PostCreate) -> models.Post:
"""投稿を作成する関数
Args:
db (Session): DBセッション
post (PostCreate): 作成する投稿の情報
Returns:
models.Post: 作成された投稿
"""
db_post = models.Post(**post.model_dump())
db.add(db_post)
db.commit()
db.refresh(db_post)
return db_post
def get_posts(db: Session) -> list[models.Post]:
"""投稿の一覧を取得する関数
Args:
db (Session): DBセッション
Returns:
list[models.Post]: 取得された投稿の一覧
"""
return db.query(models.Post).all()
def get_post_by_id(db: Session, post_id: str) -> models.Post:
"""投稿の詳細を取得する関数
Args:
db (Session): DBセッション
post_id (str): 取得する投稿のID
Returns:
models.Post: 取得された投稿
"""
return db.query(models.Post).filter(models.Post.id == post_id).first()
def update_post(db: Session, post_id: str, post: schemas.PostCreate) -> models.Post:
"""投稿を更新する関数
Args:
db (Session): DBセッション
post_id (str): 更新する投稿のID
post (PostCreate): 更新する投稿の情報
Returns:
models.Post: 更新された投稿
"""
db_post = db.query(models.Post).filter(models.Post.id == post_id).first()
for key, value in post.model_dump().items():
setattr(db_post, key, value)
db.commit()
db.refresh(db_post)
return db_post
def delete_post(db: Session, post_id: str) -> models.Post:
"""投稿を削除する関数
Args:
db (Session): DBセッション
post_id (str): 削除する投稿のID
Returns:
models.Post: 削除された投稿
"""
db_post = db.query(models.Post).filter(models.Post.id == post_id).first()
db.delete(db_post)
db.commit()
return db_post
def get_posts_by_user_id(db: Session, user_id: str) -> list[models.Post]:
"""ユーザーの投稿一覧を取得する関数
Args:
db (Session): DBセッション
user_id (str): 取得するユーザーのID
Returns:
list[models.Post]: 取得された投稿の一覧
"""
return db.query(models.Post).filter(models.Post.user_id == user_id).all()
5.3 エンドポイントの作成
Postエンドポイントの実装します。実装後は/docsでAPIが実際に動くか確認してみてください。
`/posts`エンドポイント
import文などは省略しています。
@router.post("/", response_model=schemas.PostResponse, status_code=201)
async def create_post_endpoint(
post: schemas.PostCreate, db: Session = Depends(deps.get_db)
) -> schemas.PostResponse:
"""投稿を作成するエンドポイント
Args:
post (schemas.PostCreate): 作成する投稿の情報
db (Session, optional): DBセッション. Defaults to Depends(get_db).
Raises:
HTTPException: ユーザーが存在しない場合に発生
Returns:
PostResponse: 作成された投稿の情報
"""
# ユーザーが存在するか確認
user = crud.get_user_by_uid(db, user_id=post.user_id)
if not user:
raise HTTPException(status_code=404, detail="User not found")
created_post = crud.create_post(db, post)
if created_post:
return created_post
else:
raise HTTPException(status_code=400, detail="Post could not be created")
@router.get("/", response_model=List[schemas.PostResponse])
async def read_posts(db: Session = Depends(deps.get_db)) -> List[schemas.PostResponse]:
"""投稿の一覧を取得するエンドポイント
Args:
db (Session, optional): DBセッション. Defaults to Depends(deps.get_db).
Returns:
List[schemas.PostResponse]: 取得された投稿の一覧
"""
posts = crud.get_posts(db)
return posts
@router.get("/{post_id}", response_model=schemas.PostResponse)
async def read_post(
post_id: str, db: Session = Depends(deps.get_db)
) -> schemas.PostResponse:
"""投稿の詳細を取得するエンドポイント
Args:
post_id (str): 取得する投稿のID
db (Session, optional): DBセッション. Defaults to Depends(deps.get_db).
Raises:
HTTPException: 投稿が存在しない場合に発生
Returns:
schemas.PostResponse: 取得された投稿の情報
"""
post = crud.get_post_by_id(db, post_id)
if not post:
raise HTTPException(status_code=404, detail="Post not found")
return post
@router.patch("/{post_id}", response_model=schemas.PostResponse)
async def update_post(
post_id: str, post: schemas.PostUpdate, db: Session = Depends(deps.get_db)
) -> schemas.PostResponse:
"""投稿を更新するエンドポイント
Args:
post_id (str): 更新する投稿のID
post (schemas.PostUpdate): 更新する投稿の情報
db (Session, optional): DBセッション. Defaults to Depends(deps.get_db).
Returns:
schemas.PostResponse: 更新された投稿の情報
"""
# 投稿が存在するか確認
existing_post = crud.get_post_by_id(db, post_id)
if not existing_post:
raise HTTPException(status_code=404, detail="Post not found")
updated_post = crud.update_post(db, post_id, post)
return updated_post
@router.delete("/{post_id}", response_model=schemas.PostResponse)
async def delete_post(
post_id: str, db: Session = Depends(deps.get_db)
) -> schemas.PostResponse:
"""投稿を削除するエンドポイント
Args:
post_id (str): 削除する投稿のID
db (Session, optional): DBセッション. Defaults to Depends(deps.get_db).
Returns:
schemas.PostResponse: 削除された投稿の情報
"""
# 投稿が存在するか確認
existing_post = crud.get_post_by_id(db, post_id)
if not existing_post:
raise HTTPException(status_code=404, detail="Post not found")
deleted_post = crud.delete_post(db, post_id)
return deleted_post
`/users`エンドポイント
import文などは省略しています。
@router.get("/{user_id}/posts", response_model=List[schemas.PostResponse])
async def read_user_posts(
user_id: str, db: Session = Depends(deps.get_db)
) -> List[schemas.PostResponse]:
"""ユーザーの投稿の一覧を取得するエンドポイント
Args:
user_id (str): 取得するユーザーのID
db (Session, optional): DBセッション. Defaults to Depends(deps.get_db).
Exceptions:
HTTPException: ユーザーが見つからない場合に発生
Returns:
List[schemas.PostResponse]: 取得された投稿の一覧
"""
# ユーザーが見つからない場合は404エラーを返す
existing_user = crud.get_user_by_uid(db, user_id)
if existing_user is None:
raise HTTPException(status_code=404, detail="User not found")
posts = crud.get_posts_by_user_id(db, user_id)
return posts
6章: Commentエンドポイントの実装
この章では、Commentエンドポイントの実装を扱います。UserやPostエンドポイントに関する基本的なCRUD操作と実装方法の理解を前提として、Commentエンドポイントの設計と実装の全体的な流れについて概説します。
6.1 Commentエンドポイントの設計
Commentモデルに関連する基本的なエンドポイントは以下のように設計されます:
- コメントの作成:
POST /posts/{post_id}/comments - 特定投稿のコメント一覧取得:
GET /posts/{post_id}/comments - コメント情報の更新:
PATCH /comments/{comment_id} - コメントの削除:
DELETE /comments/{comment_id}
このエンドポイント設計は、コメントが投稿に対して関連付けられていることを反映しています。コメントは特定の投稿の下に存在するため、その関連性をURLパスに明示的に示しています。
6.2 エンドポイントの実装ポイント
6.2.1 関連性の管理
Commentエンドポイントの実装では、コメントがどの投稿に属しているかを明確に管理する必要があります。コメントを作成する際には、そのコメントが関連付けられる投稿のIDをパスパラメータから取得し、適切に処理します。
6.2.2 レスポンスの形式定義
コメントのデータバリデーションも重要です。schemasディレクトリに適切なPydanticモデルを定義し、リクエストデータの構造と内容を検証します。
今回の実装では、従来のものと少し異なる点があります。具体的には、レスポンスに異なるmodelが含まれており、これが原因でmodel_config = {"orm_mode": True}を使用してmodelからPydanticのスキーマへ自動変換する際にエラーが発生します。この問題に対処する方法については、本章の後半で詳しく説明します。
`schemas/comment.py
from typing import Optional
from pydantic import BaseModel
class CommentBase(BaseModel):
"""コメントのベースモデル"""
content: str
class CommentCreate(CommentBase):
"""コメントの作成モデル"""
user_id: str
class CommentResponse(CommentBase):
"""コメントのレスポンスモデル"""
id: str
user_id: str
post_id: str
model_config = {"from_attributes": True}
class CommentUpdate(CommentBase):
"""コメントの更新モデル"""
content: Optional[str] = None
class CommentWithUserResponse(CommentResponse):
"""コメントのレスポンスモデル(ユーザー情報付き)"""
user_name: str
model_config = {"from_attributes": True}
6.2.3 CRUD操作の実装
crudディレクトリにCommentモデルに対するCRUD操作を定義します。これらの関数はエンドポイントから呼び出され、コメントの作成、取得、更新、削除などのデータベース操作を行います。
`crud/comment.py`
from sqlalchemy.orm import Session
from app import models, schemas
def create_comment_for_post(
db: Session, comment: schemas.CommentCreate, post_id: str
) -> models.Comment:
"""投稿にコメントを作成する関数
Args:
db (Session): DBセッション
comment (schemas.CommentCreate): 作成するコメントの情報
post_id (str): コメントを作成する投稿のID
Returns:
models.Comment: 作成されたコメントの情報
"""
db_comment = models.Comment(**comment.dict(), post_id=post_id)
db.add(db_comment)
db.commit()
db.refresh(db_comment)
return db_comment
def get_comments_for_post(db: Session, post_id: str) -> list[models.Comment]:
"""投稿に対するコメントの一覧を取得する関数
Args:
db (Session): DBセッション
post_id (str): 取得するコメントの投稿のID
Returns:
list[models.Comment]: 取得されたコメントの一覧
"""
return db.query(models.Comment).filter(models.Comment.post_id == post_id).all()
def get_comment_by_id(db: Session, comment_id: str) -> models.Comment:
"""コメントの詳細を取得する関数
Args:
db (Session): DBセッション
comment_id (str): 取得するコメントのID
Returns:
models.Comment: 取得されたコメント
"""
return db.query(models.Comment).filter(models.Comment.id == comment_id).first()
def update_comment(
db: Session, comment_id: str, comment: schemas.CommentUpdate
) -> models.Comment:
"""コメントを更新する関数
Args:
db (Session): DBセッション
comment_id (str): 更新するコメントのID
comment (schemas.CommentUpdate): 更新するコメントの情報
Returns:
models.Comment: 更新されたコメント
"""
db_comment = (
db.query(models.Comment).filter(models.Comment.id == comment_id).first()
)
for key, value in comment.model_dump(exclude_unset=True).items():
setattr(db_comment, key, value)
db.commit()
db.refresh(db_comment)
return db_comment
def delete_comment(db: Session, comment_id: str) -> models.Comment:
"""コメントを削除する関数
Args:
db (Session): DBセッション
comment_id (str): 削除するコメントのID
Returns:
models.Comment: 削除されたコメント
"""
db_comment = (
db.query(models.Comment).filter(models.Comment.id == comment_id).first()
)
db.delete(db_comment)
db.commit()
return db_comment
6.3 エンドポイントの実装
Commentエンドポイントを実装した後は、特に/posts/{post_id}/commentsのようなネストされたリソースに対する操作が期待通りに動作するかを確認することが重要です。実装が完了したら、/docsエンドポイントでSwagger UIを通じてAPIの動作を確認し、各エンドポイントが適切に機能していることをテストします。
`endpoints/comments.py
import文などは省略しています。
@router.patch("/{comment_id}", response_model=schemas.CommentResponse)
async def update_comment_endpoint(
comment_id: str, comment: schemas.CommentUpdate, db: Session = Depends(deps.get_db)
) -> schemas.CommentResponse:
"""コメントを更新するエンドポイント
Args:
comment_id (str): 更新するコメントのID
comment (schemas.CommentUpdate): 更新するコメントの情報
db (Session, optional): DBセッション. Defaults to Depends(get_db).
Raises:
HTTPException: コメントが見つからない場合に発生
Returns:
CommentResponse: 更新されたコメントの情報
"""
# コメントが存在するか確認
db_comment = crud.get_comment_by_id(db, comment_id=comment_id)
if not db_comment:
raise HTTPException(status_code=404, detail="Comment not found")
updated_comment = crud.update_comment(db, comment_id, comment)
return updated_comment
@router.delete("/{comment_id}", response_model=schemas.CommentResponse)
async def delete_comment_endpoint(
comment_id: str, db: Session = Depends(deps.get_db)
) -> schemas.CommentResponse:
"""コメントを削除するエンドポイント
Args:
comment_id (str): 削除するコメントのID
db (Session, optional): DBセッション. Defaults to Depends(get_db).
Raises:
HTTPException: コメントが見つからない場合に発生
Returns:
CommentResponse: 削除されたコメントの情報
"""
# コメントが存在するか確認
db_comment = crud.get_comment_by_id(db, comment_id=comment_id)
if not db_comment:
raise HTTPException(status_code=404, detail="Comment not found")
deleted_comment = crud.delete_comment(db, comment_id)
return deleted_comment
今回の実装では、従来と異なりレスポンスに異なるモデルが含まれる場合があります。これにより、model_config = {"orm_mode": True}を使用したモデルからPydanticスキーマへの自動変換時にエラーが発生する可能性があります。この問題に対処する方法については、本章の後半で説明します。特に、Commentエンドポイント実装では、ORMのリレーションシップ機能を活用して、関連するユーザー情報を効率的に取得します。この機能により、直接SQLクエリを書くことなく、関連データを簡単に取り扱うことができます。
例えば、以下のコードスニペットでは、Commentモデルから関連するUserモデルのデータを取得しています。これは、Commentモデルに設定されたリレーションシップを通じて行われます。
# 投稿に紐づくコメントの一覧を取得し、それぞれのコメントに対してユーザー名を含めたレスポンスを生成する例
comments_with_user = [
schemas.CommentWithUserResponse(
id=comment.id,
user_id=comment.user_id,
post_id=comment.post_id,
content=comment.content,
user_name=comment.user.name, # ここでリレーションシップを使用してUserモデルからユーザー名を取得
)
for comment in comments
]
ORMのリレーションシップ機能により、開発者はデータ間の関連性を簡潔に表現し、データアクセスの複雑さを軽減できます。これにより、開発プロセスが効率化され、より直感的にデータモデリングが行えるようになります。
endpoints/posts.py
@router.post(
"/{post_id}/comments/", response_model=schemas.CommentResponse, status_code=201
)
async def create_comment_for_post(
post_id: str, comment: schemas.CommentCreate, db: Session = Depends(deps.get_db)
) -> schemas.CommentResponse:
"""投稿にコメントを作成するエンドポイント
Args:
post_id (str): コメントを作成する投稿のID
comment (schemas.CommentCreate): 作成するコメントの情報
db (Session, optional): DBセッション. Defaults to Depends(deps.get_db).
Raises:
HTTPException: 投稿が存在しない場合に発生
Returns:
CommentResponse: 作成されたコメントの情報
"""
# 投稿が存在するか確認
existing_post = crud.get_post_by_id(db, post_id)
if not existing_post:
raise HTTPException(status_code=404, detail="Post not found")
created_comment = crud.create_comment_for_post(db, comment, post_id)
return created_comment
@router.get(
"/{post_id}/comments/", response_model=List[schemas.CommentWithUserResponse]
)
async def read_comments_for_post(
post_id: str, db: Session = Depends(deps.get_db)
) -> List[schemas.CommentWithUserResponse]:
"""投稿に紐づくコメントの一覧を取得するエンドポイント
Args:
post_id (str): 取得するコメントの投稿のID
db (Session, optional): DBセッション. Defaults to Depends(deps.get_db).
Raises:
HTTPException: 投稿が存在しない場合に発生
Returns:
List[schemas.CommentWithUserResponse]: 取得されたコメントの一覧
"""
# 投稿が存在するか確認
existing_post = crud.get_post_by_id(db, post_id)
if not existing_post:
raise HTTPException(status_code=404, detail="Post not found")
comments = crud.get_comments_for_post(db, post_id)
comments_with_user = [
schemas.CommentWithUserResponse(
id=comment.id,
user_id=comment.user_id,
post_id=comment.post_id,
content=comment.content,
user_name=comment.user.name, # ここでリレーションシップ関係であるUserの情報を取得
)
for comment in comments
]
return comments_with_user
7. まとめ
この記事シリーズを通じて、FastAPIを用いたWebアプリケーション開発の基礎から応用まで幅広く学んできました。主な学習ポイントを振り返ります。
- 基本設定とセットアップ: FastAPIのプロジェクト構造の理解と初期設定方法。
- データベース接続の設定: SQLAlchemyを用いたデータベース接続と操作方法。
- CRUD操作の実装: モデルに基づいたCRUD操作の実装とそのエンドポイントへの組み込み。
- データベースマイグレーション: Alembicを使ったデータベーススキーマのマイグレーション管理。
- リレーションシップの管理: 複数モデル間のリレーションシップを活用したデータ管理。
次のステップへ
ここまでの学習を踏まえ、次のステップではさらに深いトピックに挑戦します。具体的には以下の内容を予定しています。
- 認証と認可: セキュリティの重要性を踏まえ、ユーザー認証と認可処理の実装方法。
- 高度なデータバリデーション: Pydanticを用いた複雑なデータ構造のバリデーション。
- APIのテスト: テスト駆動開発(TDD)に基づくAPIのテスト方法。
継続的な学習の重要性
このシリーズを通じて得た知識をもとに、実際にアプリケーションを開発することで学びを深めてください。問題に直面した時は、公式ドキュメントやコミュニティの力を借りながら解決策を見つけ出しましょう。また、新しい機能や技術トレンドにも積極的に目を向け、継続的な学習を心がけることが重要です。
FastAPIを始めとする現代のWeb開発技術は迅速な開発と高いパフォーマンスを可能にします。この記事シリーズが、皆さんのWebアプリケーション開発の旅の有益な一歩となり、技術的な洞察と実践的なスキルの向上に役立つことを願っています。
プロジェクトリポジトリ
今回作成したリポジトリ:
- 本記事で構築したプロジェクトの全てのコードが含まれています。是非、クローンまたはフォークして、自由に使用や改変を行ってください。
8. 参照リンク
参考にしたリポジトリ:
- 本記事を書くにあたり、参考にしたリポジトリです。詳細な例や、更に進んだ内容を学ぶには、このリポジトリが非常に有用です。
最後に
記事を読んでいただきありがとうございました。何か質問やフィードバックがあれば、お気軽にコメントしてください。
Discussion