AWS CDK
Github ActionsでビルドしたイメージをECRにプッシュしたい。必要なポリシーを確認。
デフォルトポリシーにはちょうど良いのがない。
EC2InstanceProfileForImageBuilderECRContainerBuilds
は含まれるアクションとしては近いけどポリシー名からして明らかに用途が違うっぽいから自分で作ったほうがよさそう。
const ecrPushPolicy = new iam.Policy(this, "AWSEcrPushPolicy", {
statements: [
new iam.PolicyStatement({
actions: ["ecr:GetAuthorizationToken"],
resources: ["*"],
}),
new iam.PolicyStatement({
actions: [
"ecr:CompleteLayerUpload",
"ecr:UploadLayerPart",
"ecr:InitiateLayerUpload",
"ecr:BatchCheckLayerAvailability",
"ecr:PutImage",
],
resources: ["*"],
}),
],
});
ManagedPolicyとPolicyの違いは?
AWSが用意していてたまに更新されるポリシーをManagedPolicyとよぶっぽい。
既存ポリシーとかデフォルトポリシーって呼んでたけど呼び方間違ってた
ユーザーも普通に作れそう。
コンソールならユーザーに直接ポリシーを付与できた。今回はgithub actions用のIAMユーザーを作るのでわざわざグループ作らないで直接付与したい。CDKで直接ユーザーにポリシーを付与するには?
GithubActionsで自動プッシュ設定する
Githubの当該リポジトリのSettings->Security->Secrets and variables->Actions -> Repository secretsに追加済み。
AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY
まずここまでやってエラーが出ないのを確認
name: production deploy
on:
push:
branches: [main]
jobs:
foo:
runs-on: ubuntu-latest
steps:
- uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ap-northeast-1
- name: Login to Amazon ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v2
- name: Build, tag, and push docker image to Amazon ECR
env:
REGISTRY: ${{ steps.login-ecr.outputs.registry }}
REPOSITORY: my-ecr-repo
IMAGE_TAG: ${{ github.sha }}
run: |
docker build -t $REGISTRY/$REPOSITORY:$IMAGE_TAG .
docker push $REGISTRY/$REPOSITORY:$IMAGE_TAG
上記urlのこれを参考にする
name: production deploy
on:
push:
branches: [main]
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ap-northeast-1
- name: Login to Amazon ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v2
- name: Build, tag, and push image to Amazon ECR
env:
REGISTRY: ${{ steps.login-ecr.outputs.registry }}
REPOSITORY: clockwork
IMAGE_TAG: ${{ github.sha }}
run: |
docker build -t $REGISTRY/$REPOSITORY:$IMAGE_TAG .
docker push $REGISTRY/$REPOSITORY:$IMAGE_TAG
これでECRには上がった。CDKでECS立てるか…。
デプロイするイメージ指定の話
ECS(Fargate)使うときALBかNLBを使う話ばかり出てくるんだけど、テスト環境なんかはECS単体でいいんじゃねえのと思いつつ調べてる。ECS単体にドメイン設定する方法なさそう。設定項目が存在しねえ。
NATゲートウェイ使えばできるっぽいけど、アレ高いし目的とズレてるから使いたくない。マネージドサービス使うときに変なことはしたくなくて、ベストプラクティスに乗せたい。
あいまいに調べてると、ALBかNLBを使うとそこにElastic IPを紐づけられる雰囲気がある。
そしてALBとNLBの違いは動作レイヤの違いらしくて、TCP/UDPのときはNLB、HTTPのときはALBっぽい。結構HTTPのときNLB使ってる記事いっぱい出てきたけどな。公式が一番正しいので。
Q: Application Load Balancer で静的 IP や PrivateLink を使用するにはどうすればよいですか?
A: PrivateLink とアベイラビリティーゾーンごとの静的 IP アドレスをサポートしている Network Load Balancer から Application Load Balancer にトラフィックを転送することができます。Application Load Balancer タイプのターゲットグループを作成し、そこに Application Load Balancer を登録し、Application Load Balancer タイプのターゲットグループにトラフィックを転送するように Network Load Balancer を設定します。
うんち!!!!ALB単体だとだめっぽい。NLBかGlobal Acceleratorの設定がいるらしい。どっちが安いんだこれは。
Global Acceleratorは0.025USD/時間。1か月は720時間として18USD!?!?!?!?IPアドレス固定だけに使うには高すぎませんか????
NLBも0.0243USD/時間に加えてNLCU時間とかいうわけわからん概念に依存する追加料金。
大体0.025USD/時間としたらGlobal Accelerator変わらんやんけ
この辺そもそもエンジニアの稼働費用が高いから許されてるだけで普通に高くてワロ
いやまてRoute53を使うなら、ALBで行けるのか?IPアドレス固定とドメイン紐づけをセットで考えてたけど、Route53だと別か?

でもALBもよく見たら料金一緒~~~
NATゲートウェイの金額も一応厳密に確認しておく。
0.062 USD / 時
gg bro
Webサービスなら、Route53+ALB+ECS on Fargateだなあこれは。順当にやるならこれ。
でもミニマムでやるには高すぎる。ECRにコンテナイメージを保存していくのは既定路線として、そのコンテナイメージをもっと安く運用するプランはないか?例えば極論EC2にdockerをインストールしてデーモン化するなどの方法が考えられる。そのままだと全くスケールしないが検証段階では十分。大事なのはECRにコンテナイメージを自動保存してそれを動かすという経路さえ最初に確保しとけば、本リリースでスケールさせたくなったときALB+ECS on Fargateに移せばいいだけなので超安全というところ。
Amazon Lightsailとかいうのがあることを思い出してドキュメント眺めてたらなんかあった。
クォレハ…
Amazon Lightsailのコンテナはこの辺? 微妙~~~スペックのわりに高い

App Runner、アクセス量に対して金額がかかるから、さては小規模のとき安い?
1vCPU + 2GBメモリ
App Runner は 0.064(USD/h) + 0.007(USD/h)*2 = 0.0780(USD/h)
Fargate は 0.04045(USD/h) + 0.00443(USD/h)*2= 0.0493(USD/h)
Fargate Spotは 0.015168(USD/h) + 0.001659(USD/h)*2 = 0.0185(USD/h)
FargateとFargate Spotにはドメイン紐づけたいからALB入れなきゃいけなくて、+0.25USD/h
最低ラインということでタスク数1とする。
テスト環境などはFargate Spot単体動作させるパターンもあるはずなので、Spotはそれで考えると、こう。

あれぇ~??App Runner安いけど???
東京リージョンだと高いらしい。
0.007 USD/GB 時と 0.064 USD/vCPU 時の料金をご利用になれるのは、米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (オレゴン)、欧州 (アイルランド) の AWS リージョンのみです。アジアパシフィック (東京) リージョンの場合、料金は 0.009 USD/GB 時および 0.081 USD/vCPU 時となります。
おいィ?
おま国補正をかけるとこう。

これ、App RunnerをprivateのRDSに繋ぎながら外部ネットワークにも繋がなきゃいけない場合に生じるコストが含まれてない。
NATゲートウェイが必要になり、固定費いくらだよ?まあなんかナンセンスな気配がしてくる
あやしくなってきた。これマジで難しいな。
一つ言えるのは、スケーリングする必要が生じた後はおとなしくALB+Fargateってこと。
アクセス数が少ない初動の判断が難しい。でもイベント系のアプリじゃないなら、とりあえずAppRunnerで始めといて、上記グラフでいう17時間アクティブ/日を超えるか、ピーク時に2インスタンス立ち上がるようになったあたりでALB+Fargateに切り替えるのが無難そうではある。
後でちゃんと比較をまとめたいので、指針をメモ。
-
既定路線:デプロイはコンテナを自動ビルドしてECRにPUSH。可搬性を重視することで再構築リスクや同構成別プロジェクトにおける再構築コストの低減を狙う。
-
択: コンテナをどこで動かすか?
- EC2 に docker。一番安いけど結局手で管理する部分が生じる
- ECS on EC2 + ALB。Fargateより安くなるけど、どうせALBも必要だしあんまり変わらん。筋悪そう。公式もまずFargateを選択肢に入れろって言ってるし。検証は後回し。
- ECS on Fargate + ALB。スケーリングに優れる安定行動。ただし高い。
- App Runner。アクティブ時間が少なく、スケーリングしなくていいなら強い。ただし負荷が上がってくるようならECS on Fargate + ALBに比べてコスパが悪くなる。
- Amazon Lightsail Container。1vCPUの時点でコスパがFargateより悪い。それより下のスペックでよくてスケーリングを無視していいなら、もしかしたらAppRunnerより強いかも?最低スペックでどこまで何を動かせるのか、検証の価値はある。
↑この「要はECRからイメージ引いて動けば良くて、その選択肢を全部比較する」って考え方はかなり筋がよく思えるんだけど、それぞれを試した記事とか2種類比較ぐらいで、全部を金額込みで比較してる人がおらん。やっぱエンジニアって高いよな。
結論としては、まずAppRunnerを使ってみる。検証系のプロジェクト多いしな。
注意点として、AppRunnerを使うときマネージドなイメージを使っちゃうと可搬性に劣るので、絶対別の場所でビルドしてイメージを用意するべき。可搬性にこだわらないなら普通にEC2で十分なので。
あとアクセスあった分だけ支払いというのもよい。ためそう。
曖昧にTwitterとかでApp Runnerの問題点を読むと、イメージのタグが一つしか設定できないっぽい?指定したタグを監視して、イメージに更新があるとAppRunnerにも適用されるっぽい?
確かにちょっと気になるけど、普通にlatestを更新しちゃえばいいんじゃね。気になるなら毎回それとは別に直近何件かハッシュつけて残しとけばロールバックもできそう。
なんかprivateサブネットにアクセスできないとか言う噂を読んだけど。いまはprivate linkでいけるだろたぶん。で、料金は?
App RunnerからprivateのRDSにつなぐ方法とは。
これはVPCからAppRunnerにつなぐやつだから違う
これとか。
VPCコネクタを使うらしい。
でもその代わりAppRunnerから外のネットワークにつなげるためにはNATゲートウェイが必要になるらしい。だからNATゲートウェイが高いっつってんだろうが!!!
話ズレるけどメモ。CloudFrontをAppRunnerの前段に置くときの話。
AppRunnerからインターネットの何か叩くことあるか??
あるわ。普通にOpenAIのAPI使いたかった。
でもこのためにNATゲートウェイの0.062 USD / 時を支払うなら普通にFargateでいいんだよなぁ。
ECS on Fargateは適当にpublicサブネットにおいて大丈夫な話。
結局Fargate奴~~~~~~~~~~~~~~~
NATゲートウェイはVPCが同じなら一つでいい。
つまり個人で遊ぶときは同VPCにNATゲートウェイ+AppRunner複数か?
業務ではさすがにプロジェクトごとにVPC分けなきゃいけないだろう。セキュリティ的に。
バックエンドとフロントエンドが別でコンテナを別に作ってるとき、Fargate構築だとそれぞれにALB料金かかることになるのヤバだね。そうなると両方AppRunnerに突っ込んでNATゲートウェイ設定かな。オーバーだねぇ!!!!
何もかもオーバーすぎて、検証段階ではEC2にdockerインストールしてぶち込めばよくねという気持ちになってきたァ。超ウケる。さすがにDBはRDSだけど。
ナニコレ。
ひとまずCDKの学びの続きということで、明日はEC2をCDKで立てるところからやる。
TODO 今度導入の説得用に簡易料金表作ろ。想定工数削減量とそれぞれの想定用途まとめみたいなやつ。
あとは一応訓練としてALB+FargateのCDKも書いておく
ALB使いまわせるのマジ?
ALB使いまわせるならFargateかなりいいじゃん。問題かなり解決した気がする
aws ecr get-login-password --region ap-northeast-1 --profile ayataka0nk | docker login --username AWS --password-stdin 710587538762.dkr.ecr.ap-northeast-1.amazonaws.com/clockwork
ECS on Fargateのサービス登録したら一生タスクデプロイがループして終わらなくなったんだが??
1回消して、コンソールから手動で設定してみる
[-] AWS::ECS::Cluster ClockworkCluster ClockworkClusterB221FF6F destroy
[-] AWS::IAM::Role ClockworkTaskDefinition/TaskRole ClockworkTaskDefinitionTaskRoleA304BF0D destroy
[-] AWS::ECS::TaskDefinition ClockworkTaskDefinition ClockworkTaskDefinition1ED8F4FF destroy
[-] AWS::IAM::Role ClockworkTaskDefinition/ExecutionRole ClockworkTaskDefinitionExecutionRole73E56845 destroy
[-] AWS::IAM::Policy ClockworkTaskDefinition/ExecutionRole/DefaultPolicy ClockworkTaskDefinitionExecutionRoleDefaultPolicyCDADD057 destroy
[-] AWS::ECS::Service ClockworkService/Service ClockworkServiceDC6EF4CD destroy
[-] AWS::EC2::SecurityGroup ClockworkService/SecurityGroup ClockworkServiceSecurityGroupE70405BF destroy
↑解決した。Next.jsでサービス作成時のポートを3000で指定してたのに、割り当てたセキュリティグループのIngressRuleで3000を開放してなかったのが悪い。
いや開放しないとアクセスできないのは知ってたけど、タスクの正常立ち上げ時にポートチェックしてるとは思ってなかったので、事故!
というわけでECS設定まずはここまで。ALBはまだやってない。自動で割り当てられたIPアドレス:3000にアクセスして見れることを確認した。
///////////////
// ECS
///////////////
const cluster = new ecs.Cluster(this, "ClockworkCluster", {
clusterName: `ClockworkCluster`,
vpc: vpc,
});
const taskDefinition = new ecs.FargateTaskDefinition(
this,
"ClockworkTaskDefinition",
{
cpu: 1024,
memoryLimitMiB: 2048,
}
);
const container = taskDefinition.addContainer("ClockworkContainer", {
image: ecs.ContainerImage.fromEcrRepository(
ecrRepository,
"0c272af55c7700fae62b3d9cfdc8e7efeca14980"
),
//TODO タグをパラメータストアから取得する
});
container.addPortMappings({
containerPort: 3000,
protocol: ecs.Protocol.TCP,
});
const ecsSericeSecurityGroup = new ec2.SecurityGroup(
this,
"EcsServiceSecurityGroup",
{
vpc: vpc,
description: "Security Group for ECS Service",
allowAllOutbound: true,
}
);
ecsSericeSecurityGroup.addIngressRule(
ec2.Peer.anyIpv4(),
ec2.Port.tcp(3000)
);
const service = new ecs.FargateService(this, "ClockworkService", {
cluster: cluster,
taskDefinition: taskDefinition,
securityGroups: [ecsSericeSecurityGroup],
capacityProviderStrategies: [
{
capacityProvider: "FARGATE_SPOT",
base: 1,
weight: 1,
},
],
assignPublicIp: true,
});
命名センスは現状カス。それぞれの命名がどこまでのスコープを考慮して書けばいいのか一部わかってない。クラスタとかサービスはこれでよさげだけど、セキュリティグループがどこのECSサービスのためのものなのかわかるようにすべき
まあリファクタはあと。何事もまず一通り動くようにして全体を理解してから、作り直しを2回やるのが板。ALB立てる。
まあ名前からしてこれだよな。
↑を見つつ適当に書いてみた。
///////////////
// ALB
///////////////
const albSecurityGroup = new ec2.SecurityGroup(this, "AlbSecurityGroup", {
vpc: vpc,
description: "Security Group for ALB",
});
albSecurityGroup.addIngressRule(
ec2.Peer.anyIpv4(),
ec2.Port.tcp(80),
"Allow HTTP traffic"
);
albSecurityGroup.addEgressRule(
ecsSericeSecurityGroup,
ec2.Port.tcp(3000),
"Allow HTTP traffic"
);
ecsSericeSecurityGroup.addIngressRule(
albSecurityGroup,
ec2.Port.tcp(3000),
"Allow HTTP traffic"
);
const alb = new ApplicationLoadBalancer(this, "ClorkworkLoadBalancer", {
vpc,
internetFacing: true,
securityGroup: albSecurityGroup,
});
const listener = alb.addListener("Listener", {
port: 80,
open: true,
});
listener.addTargets("EcsService", {
port: 80,
targets: [service],
});
デプロイ。成功。
ALB名称をコピーし、EC2コンソールのサイドナビゲーション>ネットワークインターフェース画面で検索。出てきたネットワークインターフェースの公開IPアドレスでアクセスしたら当該ECSのページが開いたのでクリア。
セキュリティグループの設定を最小限に狭めようとすると、ECSサービスのセキュリティグループのIngressRuleはAnyIPではなくALBのセキュリティグループを直接指定するべきだとは思う。でもそうするとまたECSサービスのHealthCheckで落ちてタスクの再起動を繰り返したりしないかな…。試してみる。
// ecsSericeSecurityGroup.addIngressRule(
// ec2.Peer.anyIpv4(),
// ec2.Port.tcp(3000)
// );
前書いたこれをコメントアウトしてデプロイしてみる。俺の予想ではヘルスチェックに失敗する。前そうだったので。
動いちゃった~~~よくわからねぇ。以前は失敗と解釈して再起動ループになった。
ECSのサービスは何をもってタスク実行成功を判定しているんだ?超謎。いったんおいとく。
↑のセキュリティグループ変更によって、ここに表示されてるパブリックIPを使ってのアクセスができないことを確認した。

これでいらなくなったのでECSserviceのpublicIPアサインをオフ
const service = new ecs.FargateService(this, "ClockworkService", {
cluster: cluster,
taskDefinition: taskDefinition,
securityGroups: [ecsSericeSecurityGroup],
capacityProviderStrategies: [
{
capacityProvider: "FARGATE_SPOT",
base: 1,
weight: 1,
},
],
// assignPublicIp: true,
});
↑の変更がトリガーになってECSサービス再起動が走った結果、やっぱり再起動ループに入った。
assignPublicIpをtrueの状態でタスクの再実行を行ったところ、成功した。
assignPublicIpをfalseにすると再起動ループに入った。ただエラーの内容としては、ECRからpullできなかったみたいなエラーが出た。ループする理由、前と違うのか?イベントやログには何も出ていない。
ECRからpullするにはネットワークにつながっている必要がある。いま使っているVPCにはNATゲートウェイがない。じゃあ公開IPアドレス振ってないならそりゃネットにでれねえわ。IPアドレスの自動割り当てを有効にした上で、セキュリティグループで縛ろう。
次、Route53とALBの紐づけ。
テスト環境と本番環境でAWSアカウント自体を分けるみたいな話あるけど、もしかしてそれやってる企業ってドメインも別にしてるのか…?サブドメインをテスト環境に向けるのがよくある方法だと思うんだが。あとドメインはさすがに手動でとるだろ。だとすればどうやってCDKと組み合わせる?
まずコンソールでやりたい設定を触ってみるとこんな感じ。Aレコードの一種なんだな。
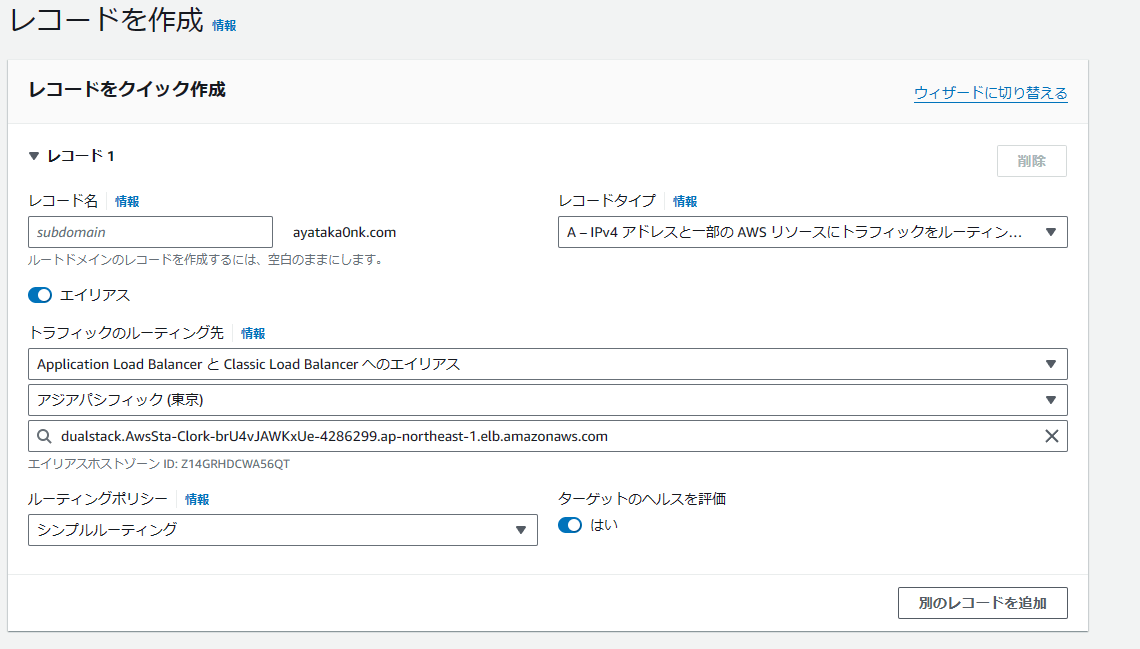
名前的にそれっぽいやつら
Route53系のリファレンス眺めてるとよく出てくる「new targets.~」が謎すぎたので適当にぐぐると。
import {
aws_route53_targets as targets,
} from 'aws-cdk-lib';
なるほど
これのことね。
以上を踏まえて、ayataka0nk.comドメインに対してサブドメインclockworkを切って向き先をALBにするならこんな感じですかね。勘。
///////////////
// Route53
///////////////
const hostedZone = route53.HostedZone.fromLookup(this, "HostedZone", {
domainName: "ayataka0nk.com",
});
const aRecord = new route53.ARecord(this, "ARecord", {
zone: hostedZone,
recordName: "clockwork",
target: route53.RecordTarget.fromAlias(
new cdk.aws_route53_targets.LoadBalancerTarget(alb)
),
});
なんだァ?てめェ…
Error: Cannot retrieve value from context provider hosted-zone since account/region are not specified at the stack level. Configure "env" with an account and region when you define your stack.See https://docs.aws.amazon.com/cdk/latest/guide/environments.html for more details.
profileで指定してれば別にいらないんじゃないのかァい?????
エラーメッセージでこれを読めって書いてあるからとりあえず読む
Stackのコンストラクタにあるcdk.StackPropsから型定義に飛んでそれも一通り読んでみる。
Stack呼び出しのところにアカウントIDとリージョンを入れてみる。lookupする箇所があると必要になるのか~~~
環境によって切り替えたければ環境変数使えってドキュメントに書いてあったけど、まあひとまずハードコーディング
const envJP: cdk.Environment = {
account: "710587538762",
region: "ap-northeast-1",
};
const app = new cdk.App();
new AwsStack(app, "AwsStack", {
env: envJP,
しばらく使ってなかったせいか何か知らんけど前使ってたドメイン死んでてワロ。
client hold
Route53の既存ドメインを見つけて登録。ドメインの管理をCDKにやらせるのは感覚的にかなり怪しいけど、ベストプラクティスはどうなんだろう?
///////////////
// Route53
///////////////
const hostedZone = route53.HostedZone.fromLookup(this, "HostedZone", {
domainName: "ayataka0nk.com",
});
const aRecord = new route53.ARecord(this, "ARecord", {
zone: hostedZone,
recordName: "clockwork",
target: route53.RecordTarget.fromAlias(
new cdk.aws_route53_targets.LoadBalancerTarget(alb)
),
ttl: cdk.Duration.minutes(5),
});
アクセスできるようになった。
とはいえ今回はNext.jsを実験台にしてるので、普通に考えたら前段にcloudfrontだろう。
1回この辺の流れを整理したい。Next.jsでS3にユーザがアップロードした静的ファイルを配置しつつ、アップロードしたユーザーだけが見れるようになんかやる方法についてよさそうな打ち筋を探す。
SSLの有効化はcloudfront挟むならそこに設定するだろうし、挟まないならALBに設定するんじゃないかなという予想。これもセオリーを調べる必要あり。
内部アプリでは必要ないけど公開アプリではCloudfront+S3になるはずなので、まずそれで作ってみる。
バージニア北部リージョンでのACM取得とCloudfrontの紐づけは自動でできるのか?
↑をまるぱくして
const acmForCloudfront = new AcmForCloudfrontStack(
app,
"AcmForCloudfrontStack",
{
env: envUS,
crossRegionReferences: true,
hostName: "clockwork",
domainName: "ayataka0nk.com",
}
);
実行しようとしたら、 npx cdk deploy
Since this app includes more than a single stack, specify which stacks to use (wildcards are supported) or specify `--all`
Stacks: AcmForCloudfrontStack · AwsStack
ん~~~~?スタックの指定がいるのか?今回ACMを作ってないと動かせないスタックがあるんだけど。スタック間の依存関係ってどうなるんだ?大丈夫なんか
忘れてた。
cdk bootstrap aws://710587538762/us-east-1 --profile ayataka0nk
複数スタックに対して、--allみたいなのもあるらしいけど、まず試しに1個ずつ実行してみる。
npx cdk deploy AcmForCloudfrontStack --profile ayataka0nk
3分ぐらいかかったけど完了した。
手動ポイントメモ: cdk bootstrap
cloudfrontはoriginConfigsの設定が多すぎてキツい。適当にALB連携のサンプル見つけて項目を絞って確認。
///////////////
// Cloudfront
///////////////
const distribution = new cloudfront.CloudFrontWebDistribution(
this,
"WebsiteDistribution",
{
viewerCertificate: cloudfront.ViewerCertificate.fromAcmCertificate(
props.certificate,
{
aliases: ["clockwork.ayataka0nk.com"],
}
),
priceClass: cloudfront.PriceClass.PRICE_CLASS_200,
originConfigs: [
{
customOriginSource: {
domainName: alb.loadBalancerDnsName,
originProtocolPolicy: cloudfront.OriginProtocolPolicy.HTTP_ONLY,
},
behaviors: [
{
isDefaultBehavior: true,
},
],
},
],
}
);
npx cdk deploy AwsStack --profile ayataka0nk
無事cloudfrontは設定されるのか?
4分ぐらいかかって作成は成功したが、HTTPS系のセキュリティグループ整備もしてないしなにやらかにやらで当然動かず。
とりあえずRoute53の向き先をALBからCloudfrontに変えた。
const aRecord = new route53.ARecord(this, "ARecord", {
zone: hostedZone,
recordName: "clockwork",
target: route53.RecordTarget.fromAlias(
new cdk.aws_route53_targets.CloudFrontTarget(distribution)
),
ttl: cdk.Duration.minutes(5),
});
でアクセスできるようになったし、httpで飛ぼうとするとhttpsに飛ばしてくれるようになった。
まあ、ええんちゃう。
でもルートパスだと404になるのはなんか意図してない挙動な気がする。cloudfrontの設定で何かあった気がするけどまあそれは細かい話だからあとでいいや。
ALBやS3ではcloudfront以外からのアクセスを弾く設定がしたい。
この辺か。要はECSのサービスのセキュリティグループでINGRESSをCloudFrontだけにすればいいってことかな。
上記記事を参考にVPCからcloudfrontのマネージドprefixlistを調べると、名前が「pl-58a04531」。ingressを anyIPv4からcloudfrontに指定。
albSecurityGroup.addIngressRule(
ec2.Peer.prefixList("pl-58a04531"),
ec2.Port.tcp(80),
"Allow HTTP traffic"
);
こいつなんで消えてねえの?

CDKに対応する記述はない。不具合とみなし、手動で削除したうえでcdkのdiffをとったが、差分なし。やはり不具合だろう。
コンソールから、既存のセキュリティルールを変更する形でprefixlistをソースにした更新をしようとすると、prefixlistは新規セキュリティルールで設定しろと言われたことがあるので、これと無関係ではなかろう。
ロードバランサのDNS名でアクセスできないことを確認した。
S3はそもそもまだ作ってない。
ちょっといろいろあって触れなかったのでいったん全部削除しようと思ったら、これ。
22:27:17 | DELETE_FAILED | AWS::ECR::Repository | EcrRepository4D7B3EE1
Resource handler returned message: "The repository with name 'clockwork' in registry with id '710587538762' cannot be de
leted because it still contains images (Service: Ecr, Status Code: 400, Request ID: b7f2f683-7317-4e22-b109-345d75036284
)" (RequestToken: 2548260a-27c0-c0c2-e373-7d1894b93f81, HandlerErrorCode: GeneralServiceException)
❌ AwsStack: destroy failed Error: The stack named AwsStack is in a failed state. You may need to delete it from the AWS console : DELETE_FAILED (The following resource(s) failed to delete: [EcrRepository4D7B3EE1]. ): Resource handler returned message: "The repository with name 'clockwork' in registry with id '710587538762' cannot be deleted because it still contains images (Service: Ecr, Status Code: 400, Request ID: b7f2f683-7317-4e22-b109-345d75036284)" (RequestToken: 2548260a-27c0-c0c2-e373-7d1894b93f81, HandlerErrorCode: GeneralServiceException)
at destroyStack (/home/ayataka/workspace/aws/node_modules/aws-cdk/lib/index.js:440:2157)
at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
at async CdkToolkit.destroy (/home/ayataka/workspace/aws/node_modules/aws-cdk/lib/index.js:443:207402)
at async exec4 (/home/ayataka/workspace/aws/node_modules/aws-cdk/lib/index.js:498:54331)
手動でECR消してからもう一回
npx cdk destroy --profile ayataka0nk --all
解決。全部消えた。