背景
ソリューションアーキテクトとして、日々 AWS の最新情報や AI/ML 関連の新技術について調査していますが、様々な情報源が点在しているため、それぞれ見に行くのは面倒です。
また、記事の中には背景情報が不足しており、内容を十分に理解できなかったり、他分野の専門家がどう評価するか判断に迷う情報なども散見されます。
そこで、複数の情報源から一括で情報を取得し、自分専用にまとめて解説してくれる記事を AI エージェントを使って作ってみようと思います。
エージェントの概要
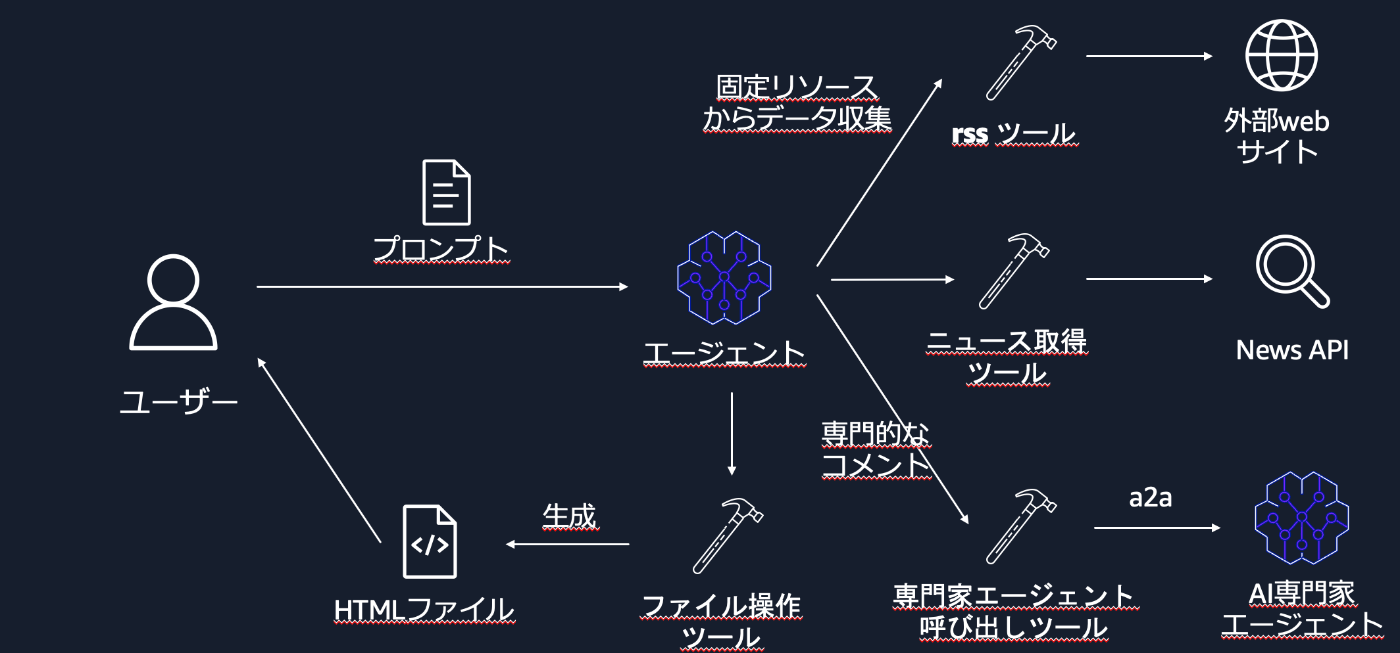
具体的には、上図のようなシステムを作ってみたいと思います。今回はエージェントの実装に注目しているため、ローカルで完結するシステムを作ります。
エージェントはツールを用いて RSS ツールや News API から最新情報を取得し、さらにコンピュータサイエンスの研究者という役割を与えたエージェントをツール経由で呼び出して専門的なコメントを取得します。すべての情報を整理できたら、ファイル書き込みツールを使って HTML ファイルを生成し、視覚的にわかりやすいレポートを作成させます。
実行環境
- Macbook PRO
- Apple M3 PRO
- メモリ:16GB
- OS:MacOS sequoia v15.6.1
- VScode
実装
事前準備
環境構築
python + venv で環境を構築します。
python3 -m venv venv
python3 -m pip install strands-agents strands-tools botocore boto3 requests urllib3 python-dotenv fastapi uvicorn
docker などを用いてコンテナで実行しても良いでしょう。
RSS
まず、情報源をいくつか事前にピックアップしてRSSのURLを取得しておきます。ツールを用いてここから最新データを取れるようにしておきます。
下記のように json 形式で resources.json としてローカルに配置します。
[
{
"リソース名": "arXiv RSS / ATOM フィード",
"分野": "分野横断・共通",
"rss_url": "https://rss.arxiv.org/rss/cs",
"内容記述": "学術論文プレプリント。コンピュータサイエンス(AI, ML含む)などのカテゴリ付き。毎日更新。"
},
{
"リソース名": "AWS News Blog",
"分野": "AWS/クラウド",
"rss_url": "https://aws.amazon.com/blogs/aws/feed/",
"内容記述": "AWS 新機能・アップデート情報。公式。"
},
{
"リソース名": "AWS What's New",
"分野": "AWS/クラウド",
"rss_url": "https://aws.amazon.com/new/feed/",
"内容記述": "サービス拡張・リージョン追加など公式発表。RSS も提供。"
},
{
"リソース名": "AWS Machine Learning Blog",
"分野": "AWS/クラウド",
"rss_url": "https://aws.amazon.com/blogs/machine-learning/feed/",
"内容記述": "AWS の Machine Learning サービス/カテゴリの技術動向をキャッチできる。"
},
{
"リソース名": "AWS Compute Blog",
"分野": "AWS/クラウド",
"rss_url": "https://aws.amazon.com/blogs/compute/feed/",
"内容記述": "AWS の Compute サービス/カテゴリの技術動向をキャッチできる。"
},
{
"リソース名": "AWS Security Blog",
"分野": "AWS/クラウド",
"rss_url": "https://aws.amazon.com/blogs/security/feed/",
"内容記述": "AWS の Security サービス/カテゴリの技術動向をキャッチできる。"
},
{
"リソース名": "arXiv cs.AI",
"分野": "AI",
"rss_url": "https://rss.arxiv.org/rss/cs.AI",
"内容記述": "最新論文。実用 AI 技術・理論の両方カバー。"
},
{
"リソース名": "Awesome ML/AI RSS Feed",
"分野": "AI",
"rss_url": "https://github.com/vishalshar/awesome_ML_AI_RSS_feed",
"内容記述": "複数の ML/AI ブログ・ソースが集約されており、使いたいものを選択可能。"
}
]
今回は AWS News Blog や AWS What's New、最新の論文のプレプリントを取得できるような RSS を選定しました。
News API
一般ニュースも取得したいので、News API のキーも発行してエージェントのプログラムと同じ階層に配置しておきます。キーはこちらから発行できます。
専門家エージェント
ニュースを専門的な観点から解説させるために、コンピュータサイエンスの研究者という役割を与えたエージェントをツール経由で呼び出せるようにし、専門的なコメントを取得させます。
まず使用モジュール
from botocore.config import Config
from strands import Agent
from strands.models import BedrockModel
from strands.multiagent.a2a import A2AServer
今回は Amazon Bedrock を生成 AI 基盤として利用するため、BedrockModel を import します。また、このエージェントは、メインのエージェントからツールとして呼び出します。FastAPI などを使って MCP サーバーを実装し、そこで生成 AI を呼び出すようなコードを書くこともできますが、今回は Strands Agents に組み込まれた Agent to Agent(A2A) 機能を使ってみたいので、A2AServer も import しておきましょう。これを使うことで、簡単にストリーミングレスポンスを実装したエージェント呼び出しサーバーを構築できます。
次に、エージェントが使う生成 AI モデルの設定をします。
def bedrock_model():
return BedrockModel(
streaming=True,
max_tokens=32000,
boto_client_config=Config(read_timeout=3600, connect_timeout=30),
)
今回、複数の記事を取得して取捨選択し、最終的にレポートを作成させるという重めのタスクを実行させるため、max_tokensやtimeoutにはある程度大きめな値をセットしました。
次に、エージェントの実体を作っていきます。プロンプトはこのようにしてみました。
PROFESSOR_PROMPT = """
あなたは大学のコンピューターサイエンス(AI専攻)の教授です。
最新研究・実装・安全性・評価指標・規制の観点から、技術ニュースに専門的コメントを与えます。
誤りがあれば根拠を挙げて指摘。読者は実務家。日本語で段落文、簡潔に。
"""
ごく簡潔なものとしてみました。この辺りは実際に実務家の方がどんな観点でニュースを眺めているのか、ヒアリングした上でプロンプトを考えてみても良いかと思います。
最後にエージェントの実体です。
professor_agent = Agent(
name="Professor",
description="CS/AI分野の専門家として技術ニュースにコメントする",
system_prompt=PROFESSOR_PROMPT,
model=bedrock_model(),
callback_handler=None,
)
# A2A サーバーとして公開(デフォルト: 127.0.0.1:9000, ストリーミング対応)
server = A2AServer(agent=professor_agent,serve_at_root=True)
if __name__ == "__main__":
server.serve() # FastAPI で起動
Strands Agents では、Agent クラスを呼び出し、中に設定を書き込むだけで簡単にエージェントを定義できます。
キュレーションエージェントの実装
次に、メインとなるエージェントを実装していきます。
まずモジュールのインポートです。
import asyncio
import os
import time
import random
from typing import Dict, List, Optional
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
from botocore.config import Config
from dotenv import load_dotenv
from strands import Agent, tool
from strands.models import BedrockModel
from strands_tools import (
current_time, file_read, file_write, http_request, rss, shell
)
from strands_tools.a2a_client import A2AClientToolProvider
from strands.types.exceptions import EventLoopException
load_dotenv()
strands agents ではエージェントの実装に際して頻繁に利用する主要なツールは組み込みで用意されています。今回は下記の6つの組み込みツールを利用しています。
- current_time
- 現在時刻を取得するツール
- file_read
- ローカルファイルの読み込みを実行するツール
- file_write
- ローカルファイルへの書き込みを実行するするツール
- http_request
- 指定した URL へ http リクエストを送信するツール
- rss
- RSSフィードの内容を取得したり、購読リストに追加したりするツール
- shell
- 許可したコマンドをローカルで実行するツール
次に各種設定情報です
# 設定定数
NEWSAPI_BASE_URL = "https://newsapi.org/v2"
BEDROCK_MODEL_ID = "us.anthropic.claude-3-7-sonnet-20250219-v1:0"
# レートの制限に抵触する場合は下記をお試しください。
# BEDROCK_MODEL_ID = "us.anthropic.claude-3-5-sonnet-20241022-v2:0"
次にニュース取得ツールを作っていきます
@tool
def fetch_news(
query: Optional[str] = None,
mode: str = "top",
country: str = "jp",
page_size: int = 20
) -> List[Dict]:
"""
NewsAPI からニュース記事を取得するツール。
概要:
- `mode` が "everything" かつ `query` が与えられている場合は `/everything` を利用。
- それ以外は `/top-headlines` を利用し、`country` を必須パラメータとして付与。
- レスポンスから必要最小限のフィールドだけを抽出し、UI/後段処理で扱いやすい形に正規化して返す。
Args:
query (Optional[str]):
検索語。`mode="everything"` のときのみ必須(※本関数は強制しないが、指定がないと
NewsAPI 側で広範検索となる)。"top" モードではキーワードフィルタとして利用。
mode (str):
取得モード。既定は "top"。
- "top" : /top-headlines エンドポイントを使用(地域別の主要記事)
- "everything" : /everything エンドポイントを使用(全文検索)
country (str):
"top" モード時の国コード(ISO 3166-1 alpha-2)。例: "jp"。NewsAPI 側仕様に依存。
page_size (int):
取得件数の上限(最大値は NewsAPI のプラン/仕様に依存)。既定 20。
Returns:
List[Dict]:
各記事について以下のキーを持つ辞書のリスト。
- "title": 記事タイトル (str | None)
- "url": 記事URL (str | None)
- "source": 媒体名 (str | None)
- "publishedAt": ISO8601 形式の公開日時 (str | None)
Raises:
RuntimeError:
環境変数 `NEWSAPI_API_KEY` が未設定の場合に送出。
requests.HTTPError:
HTTP ステータスが 4xx/5xx の場合に `response.raise_for_status()` により送出。
(429/5xx を含む。必要に応じて上位でリトライ戦略を実装してください)
例:
# 主要ヘッドラインから日本向け記事を20件(既定値)取得
fetch_news()
# キーワードで全文検索から50件取得
fetch_news(query="AWS OR AI", mode="everything", page_size=50)
"""
api_key = os.environ.get("NEWSAPI_API_KEY")
if not api_key:
raise RuntimeError("NEWSAPI_API_KEY環境変数が設定されていません")
if mode == "everything" and query:
url = f"{NEWSAPI_BASE_URL}/everything"
params = {"q": query, "pageSize": page_size}
else:
url = f"{NEWSAPI_BASE_URL}/top-headlines"
params = {"country": country, "pageSize": page_size}
if query:
params["q"] = query
response = requests.get(
url,
headers={"X-Api-Key": api_key},
params=params,
timeout=30
)
response.raise_for_status()
return [
{
"title": article.get("title"),
"url": article.get("url"),
"source": (article.get("source") or {}).get("name"),
"publishedAt": article.get("publishedAt"),
}
for article in response.json().get("articles", [])
]
また、大量のリクエストを送出しないようリミッターと指数バックオフ機構も実装します。
class SimpleRPSLimiter:
"""
1プロセス内での簡易RPS制御(同期関数用)
- N秒あたり max_calls 回に制限(デフォ: 1秒あたり 3回)
- 直前の呼び出しとの間隔を計測して必要分スリープ
"""
def __init__(self, max_calls_per_sec: float = 3.0):
self.interval = 1.0 / max_calls_per_sec
self._last = 0.0
def sleep_if_needed(self):
now = time.monotonic()
wait = self._last + self.interval - now
if wait > 0:
time.sleep(wait)
self._last = time.monotonic()
else:
self._last = now
def create_retrying_session(total=6, backoff_factor=0.6) -> requests.Session:
"""
429/5xx を指数バックオフで自動リトライ。
Retry-After ヘッダがあれば尊重。
"""
retry = Retry(
total=total,
read=total,
connect=total,
status=total,
backoff_factor=backoff_factor,
status_forcelist=(429, 500, 502, 503, 504),
allowed_methods=frozenset(["GET", "POST", "PUT", "DELETE", "HEAD", "OPTIONS", "PATCH"]),
respect_retry_after_header=True,
raise_on_status=False,
)
adapter = HTTPAdapter(max_retries=retry, pool_maxsize=20)
s = requests.Session()
s.mount("https://", adapter)
s.mount("http://", adapter)
return s
def exp_backoff_sleep(base=0.8, factor=2.0, attempt=0, jitter=True, cap=30.0):
"""
指数バックオフ待機。attempt=0,1,2... に応じて待つ。
"""
delay = min(base * (factor ** attempt), cap)
if jitter:
delay = delay * (0.5 + random.random()) # 0.5x~1.5x
time.sleep(delay)
# NewsAPI 用の共有セッション&RPSリミッタ
_HTTP = create_retrying_session(total=6, backoff_factor=0.6)
_NEWSAPI_LIMITER = SimpleRPSLimiter(max_calls_per_sec=float(os.getenv("NEWSAPI_RPS", "3")))
次にAIエージェント本体の実装をしていきます。まずはプロンプトです。
# システムプロンプト
SYSTEM_PROMPT = """
あなたは **日本語で要約・解説するニュース編集エージェント** です。以下の要件に従って記事を生成してください。
### 収集とリサーチ
- **RSSツール**を利用し、`./resources.json` に集約されたニュースソースから記事を取得すること。
- 最新の情報を収集し、**IT全般、AWS、AI、クラウド、経済、社会、クラウド/IT/AIの最新科学技術論文**の各分野から注目記事を選定すること。
- 各分野で **必ず3本以上** の重要ニュースを取り上げること。
- 内容が重複する記事は適切に統合すること。
### 記事作成の要件
- [文字数]各記事は **800〜2000字**で執筆すること。
- [コンテンツ]背景情報を補足し、**ナラティブにわかりやすく解説**すること。
- [禁止事項]**箇条書きは禁止**。必ず文章として展開すること。
- [リサーチ方法]分野ごとにリサーチ → 記事作成を行い、最後に統合すること。
- 途中のリサーチログは最後に全て削除すること
- [ログ]査過程はローカルファイルに書き出し、最終的な記事化で統合すること。統合後、ログは削除すること。
### 出典とメディア
- 使用した記事の **URLを必ず出典として明記**すること。URLはハイパーリンクとすること。
- 記事に写真が含まれる場合は、画像URLを本文に直接埋め込み、視覚的に効果的に配置すること。
- 複数の記事を統合する場合も、主要な出典URLは必ず示すこと。
### 出力形式と構造
- 最終成果物は **HTML形式**で出力すること。
- 記事は `<article>` をルートにし、分野ごとに `<section>` で区切ること。
- 見出しには `<h2>` / `<h3>` を用い、段落は `<p>` として整形すること。
- 出典は各記事末尾に `<footer>` を設け、参照URLを `[n]` 形式で番号付きで明記すること。
- 各センテンスの末尾に `[n]` のように引用番号を挿入し、対応する出典にリンクすること。記事全体で連番とするが、出典の記述はセクションごととする。
### キーワードの解説(ホバー表示)
- 主要な技術用語や重要キーワードには `<abbr title="解説文">用語</abbr>` を用いること。
- ユーザーがホバーしたときに簡潔な解説が表示されるようにすること。
- 必要に応じて a2a_client のツールを選択し、エージェント名に「CS/AI Professor」を含むA2Aエージェントを選び、記事の要約と論点(3点以内)を渡して、簡潔な専門コメントを取得
- 返答は本文に統合し、[n] で出典・講評参照を付与
### スタイル
- 全体は **フォーマルかつビジネス向き**の文体とすること。
- 視覚的にわかりやすく、見出し・段落・画像を適切に配置すること。
"""
次にストリームレスポンス用のハンドラを作っていきます。無くても大丈夫ですが、出力を綺麗に整形できるのと、エージェントの実行状態が分かりやすくなります。
class StreamingHandler:
def __init__(self, flush_interval: float = 0.25, max_buffer_chars: int = 600):
self.flush_interval = flush_interval
self.max_buffer_chars = max_buffer_chars
self._buffer: str = ""
self._last_flush: float = 0.0
self._current_tool: Optional[str] = None
self._last_was_nl: bool = True
self._sentence_terminators = ("。", "!", "?", ".", "!", "?", "\n")
def _emit(self, text: str) -> None:
if not text:
return
print(text, end="", flush=True)
self._last_was_nl = text.endswith(("\n", "\r"))
def _do_flush(self, force: bool = False) -> None:
now = time.time()
should = force
if not should and self._buffer:
if self._buffer.endswith(self._sentence_terminators):
should = True
elif len(self._buffer) >= self.max_buffer_chars:
should = True
elif (now - self._last_flush) >= self.flush_interval:
should = True
if should and self._buffer:
self._emit(self._buffer)
self._buffer = ""
self._last_flush = now
def __call__(self, **event) -> None:
# モデル本文
if "data" in event:
self._buffer += event["data"]
self._do_flush(force=False)
return
# ツール開始/終了
if "current_tool_use" in event:
info = event["current_tool_use"]
name = info.get("name", "tool")
started = info.get("started", True)
# ツール見出し前に本文を吐き切る
self._do_flush(force=True)
if started and self._current_tool != name:
if not self._last_was_nl:
print()
self._emit(f"🔧 {name} …\n")
self._current_tool = name
elif not started and self._current_tool == name:
if not self._last_was_nl:
print()
self._emit(f"✅ {name} done\n")
self._current_tool = None
return
# 完了イベント
if "message" in event or "result" in event:
self._do_flush(force=True)
return
# エラー
if "error" in event:
self._do_flush(force=True)
if not self._last_was_nl:
print()
self._emit(f"❌ {event['error']}\n")
return
最後にエージェントの定義です。
if __name__ == "__main__":
# ツール利用の同意確認をバイパスします(これを設定しない場合、同意を求められます)
os.environ["BYPASS_TOOL_CONSENT"] = "true"
model = BedrockModel(
model_id=BEDROCK_MODEL_ID,
streaming=True,
boto_client_config=Config(
read_timeout=3600,
connect_timeout=30,
retries={"mode": "adaptive", "max_attempts": 12},
max_pool_connections=10,
),
region_name="us-east-1",
max_tokens=32000
)
# A2A プロバイダ
provider = A2AClientToolProvider(
known_agent_urls=["http://127.0.0.1:9000"]
)
# 利用ツール群
tools = [
fetch_news, rss, file_write, http_request,
current_time, file_read, shell,
provider.tools
]
# Agent 構築
agent = Agent(
model=model,
tools=tools,
callback_handler=StreamingHandler()
)
# shell の実行許可コマンド(今回は全コマンドを許可(非推奨))
agent.tool.shell(command="*")
# スロットリング露出時の軽量リトライ
async def _run():
max_attempts = 3
for attempt in range(max_attempts):
try:
async for _ in agent.stream_async(SYSTEM_PROMPT):
pass
return
except EventLoopException as e:
msg = str(e).lower()
if ("throttling" in msg) or ("too many requests" in msg):
exp_backoff_sleep(base=0.8, factor=2.0, attempt=attempt, jitter=True, cap=6.0)
if attempt + 1 == max_attempts:
raise
else:
raise
asyncio.run(_run())
実行例
こちらを実行して出来上がった記事です。

続き

最近のニュースがきちんとキュレーションされており、専門家としての意見も挿入されています。期待する動きをしてくれているみたいです。
考察とまとめ
Strands Agents を使ってニュースをキュレーションするエージェントを実装してみました。複数のツールを使いこなす複雑なエージェントの実装となりましたが、フレームワークを利用することで簡潔に実装できましたね。
このエージェントはこのままローカルで実行して日に一回結果を新聞代わりに眺めてもいいですし、メールを送信するツールを持たせて、日に一回自分のアドレスに送信させるといったことをしてみても面白いかもしれません。
また、このようなある程度手順を人間が定義できるようなタスクの場合、エージェントではなくタスクの実行順を予め決め、ニュースの要約やHTMLファイルの作成など知的な作業の部分だけ API を呼び出す形とする「ワークフロー」も有効です。エージェントの形とすることで、コンテンツが不足している場合などに動的に判断して情報を足すといったこともできますが、逆に必要なタスクを十分にこなさないといった懸念もあります。
例えば、このエージェントを業界情報を収集してエンドユーザーにメールで一斉送信するようなシステムに組み込むことを考えます。この場合、品質の担保や人間による確認フロー、確実な動作などを保証するために、ワークフローで実装した方が良いでしょう。
Strands Agents にはワークフローを組む機能もついているようなので、またの記事で試してみたいと思います。
それでは!

この Publication に投稿している記事は、アマゾン ウェブ サービス ジャパン合同会社または Amazon Web Services, Inc. 所属社員による個人の見解であり、所属する組織の公式見解ではありません。参加したい従業員の方は、Sugiyama Suguru までお知らせください。
Discussion