皆さんセキュリティには詳しいでしょうか? "AI エージェント元年" などと言われていますが、その中で認証・認可の重要性はより高まっています。なぜなら、AI エージェントは単なるチャットボットを超え「目的を与えれば自律的にタスクを完遂する」存在へと移行しているためです。AI エージェントがあなたの身近な存在となった時、あなたの代わりに社内のプロジェクト管理ツールを操作したり機微な顧客情報を参照したり、時にデータベースにアクセスしたりすることになります。悪意ある第三者に利用されたときの被害を想像すれば、重要性が高まる理由は明らかです。
エージェントがユーザーの「代理」として動作する以上、認証と認可の仕組みは必須です。「誰が」「何を」「どれだけ」実行したかが追跡できなければ、不正アクセスや情報漏洩、また利用コストの肥大に関する兆候を検知・対策することはできないからです。
本稿では、AI エージェントがはらむリスクを整理し、特に認証・認可にフォーカスして基礎知識から解説します。さらに、認証・認可という面倒だが決して手を抜けない実装を Amazon Bedrock AgentCore がどのように解決できるのか例をもとに示します。
👉本ブログは AWS AI Agent ブログ祭り(Zenn: #awsaiagentblogfes, X: #AWS_AI_AGENT_ブログ祭り)の第 3 日目です。
このブログで学べること:押さえておきたい3つのポイント
本ブログを通じて、以下の3点を明確に理解できるようになります。
- AIエージェント独自のリスク : 従来のセキュリティフレームワークではとらえられないリスクを認識する
- 認証認可の基本的な仕組み : 認証認可はどのように行われ来て、AI エージェントの世界ではどのように使用されているのか
- Amazon Bedrock AgentCore による認証・認可の実装 : 利用するための Inbound、利用「させる」ための Outbound の整理と実装
AI エージェントの社会実装は、技術面はもちろん社会での受容をふくめておそらく普及に 10 年単位の時間がかかります。2025 年に生きている私達が開発するエージェントは多かれ少なかれその到達点に向けた積み重ねであり、脆弱な AI エージェントによる被害は数年単位での発展の遅れにつながる可能性があります。

なので、私も含めみんなでセキュリティやっていこうぜ!ということで本編開始です。
AIエージェント独自のリスクとは
ツールを呼び出す際に意図しない権限で動作する可能性があるのは AI エージェント特有のリスクです。これは、モデルから直接返答を返すか、あらかじめ与えられた権限で検索等を行う RAG にないリスクです。

AI エージェントを構築する際に考慮すべき点の全体像を、Generative AI Lens に沿い示します。Generative AI Lens は、AWS が公開している生成 AI アプリケーションを構築する際のベストプラクティスです。Well-Architected Framework に基づいており、各柱ごとに考慮点が整理されています。下から順にインフラやモデル、監視基盤、アプリケーション、エージェントと詰みあがっておりセキュリティの柱において AI エージェント独自の考慮事項は "Excessive agency" となります。

本記事では触れませんが、AI エージェントで「業務を代行」する場合、Observability も重要な考慮点となります。特に上場企業では内部統制報告書の作成と監査法人による監査を受けているはずで、その際に業務プロセスの定義とリスクの特定、対策を行っているはずです。業務フローの一部を AI エージェントが担う場合は Excessive agency のリスクが明らかで、対応としてこれから述べる認証・認可の制御はもちろんですが行動記録 (Observability) による逸脱の監視が必要不可欠です。AWS では Amazon Bedrock AgentCore Observability で AI エージェントごと、セッションごとの記録をとり保存することが出来ます。
リスク対策を検討するメリット
リスク対策を検討するのは手間ですが、その手間に見合うメリットがあります。過剰な権限を防ぐための認証・認可を整備することで「誰が」「何を」「どれだけ」実行したかが追跡できるようになり、次の恩恵が受けられます。
- ユーザーや部署別の AI エージェント / ツールの利用状況に基づくデータドリブンな改善計画
- コスト管理の解像度の向上 (誰がどのツールをどれだけ使ったか等)
- 監査対応やコンプライアンス要件の充足による社内外展開の高速化 (PoC 止まりの防止)
- 新規ツール導入時の安全性確保
マネージドサービスである AgentCore を活用し、これらのメリットを手間なく享受していくことが出来ます。ここから先は、Excessive agency のリスクをコントロールするための特に認証・認可について深堀していきます。
認証と認可の基本
AI エージェントに適切な権限を与えるにはどのような方式が適切でしょうか? AI エージェントは「ユーザーの代理人」として外部システムを操作します。この時パスワードや API キーといった「認証」情報を渡すリスクは回避したいものです。家事をやってもらうために家の鍵を渡してしまうリスクをイメージ頂くとよいと思います。
作業に必要なツールの利用のみ「許可」し、「認証」を共有しない方法が必要です。鍵はこちらで開けて中に入ってもらい、家事に必要な範囲で入室と道具の利用を許可するイメージです。この希望を実現するのが OAuth です。OAuthは「認証情報の共有なしに、必要な範囲だけアクセスを許可する」仕組みであり、まさにエージェントの性質にマッチしています。そのため、AI エージェントが利用するツールの標準仕様である MCP(Model Context Protocol)で認可方式として OAuth が採用されたのは自然な流れでした。では、その OAuth の仕組みを見ていきましょう。
OAuth の流れとその仕組み
OAuth は次の流れで認可を行います。
- 認可の要求: アプリケーション(AIエージェント)が認可サーバーへユーザーをリダイレクト
- ユーザーによる認可: ユーザーが求められる権限スコープを確認し「認可」を行う
- アクセストークン取得: 認可コードを使ってアクセストークンを取得
- リソースアクセス: アクセストークンを用いてリソースサーバーからデータを取得
この流れの中で重要なのは、ユーザーのパスワードなどの認証情報はアプリケーション / AI エージェントに渡らない点です。代わりに、認可コードを用い時間制限付きの「アクセストークン」を取得し、必要なスコープ(権限範囲)だけにアクセスします。
認証 (Authentication) と認可 (Authorization) の違いと統合
「認可」はユーザーの代理として作業する仕組みで、本人の情報は維持する必要がありません。こうした背景から、OAuth は認証情報を提供・維持する仕様を定めていません。
OpenID は「認証」を扱ってきたフレームワークで、2014 年に OpenID Connect として OAuth をベースにした認証へ移行しました。認証の代表的な役割はシングルサインオンで、一度本人確認が済んでしまえば他のサービスへアクセスする際に逐一認証する手間を省きます。
認証で可能になるシングルサインオン体験は、残念ながら認可には適用されません。これは認証と認可が別であるためで、Google での認可、GitHub での認可・・・などサービス個別に利用可能な範囲を逐次認可していく必要があります。そのため、OpenID Connect 等で認証し得られる token を使用し同一の Identity Provider から認可コードと等価な Assertion Authorization Grant JWT (ID-JAG) を発行し、Authorization Server からaccess token を得る “Identity Assertion Authorization Grant” が議論されています。

この方式が実現すると、AI エージェントが複数サービスをまたがった処理を行う時の認可手続きが非常に容易になることが期待されます。
認証と認可の基本のまとめ
ここまでの内容を、3 点にまとめて振り返ります。
- AI エージェントはユーザーの代理で動作する。代理に必要な許可を与える認可のフレームワークとして普及している OAuth が採用されたのは自然な流れ
- OAuth では①ユーザー、②アプリケーション (Agent)、③認可サーバーが要求を送りあうことで安全に認可を行う (3-Legged)
- 認証と認可は別の枠組み。OAuth を拡張する形で定義された OpenID Connect は認証を担う。リソースごとに認可が発生しユーザーが疲弊する問題に対し、認証に基づき認可の代行を任せることでシングルサインオンのような体験を実現する Identity Assertion Authorization Grant の検討が進んでいる
認証と認可の実装 : Amazon Bedrock AgentCore Identity
では、AI エージェントの認証と認可をどのように Amazon Bedrock AgentCore で実装できるのか確認していきます。Amazon Bedrock AgentCore は、AI エージェントの実装に際し負担となるセキュリティや運用、ホスティングといった重要だが差別化されない実装をマネージドで提供する機能群です。その中でも AgentCore Identity は AI エージェントの認証・認可プロセスを効率的かつ安全に行う機能を提供します。

AgentCore Identity は、ユーザーが AI エージェントを利用する際の認証認可 (Inbound)、AI エージェントがツールを利用する際の認証認可 (Outbound) の双方で利用できます。
- Inbound Auth:ユーザーの認証認可を担い、AI エージェントを利用するのに必要なアクセストークンや API キーを払い出す (例 : 社員管理システムと連携して判定するなど)
- Outbound Auth:AI エージェントが外部ツール(Google Calendar、Slack、自社 API など)を呼び出す際の認可を主に担う
AgentCore Identity 自体は認証認可を行う Credential Provider の機能は持っておらず、Amazon Cognito や Auth0、Microsoft (Entra ID) といった Provider とやり取りして Credential を得るプロセスを代行します。サポートされている Provider はこちらに掲載されており、多様な Provider に対し統一的なインタフェースで処理に必要な Credential を取得し以後の本質的機能に集中することが出来ます。
取得した Credential は Token Vault の機能で安全に保管・再利用できるため、ユーザーの再承認を減らしつつ、セキュアな運用が可能になります。

AgentCore Identity による認証認可プロセスの実行
bedrock-agentcore-sdk-python で実装されている @requires_access_token の機能を使用することで認証認可プロセスを簡単に実装できます。次は公式ドキュメントにある Google Drive にアクセスする例です。
import asyncio
# Injects Google Access Token
@requires_access_token(
# Uses the same credential provider name created above
provider_name="google-provider",
# Requires Google OAuth2 scope to access Google Drive
scopes=["https://www.googleapis.com/auth/drive.metadata.readonly"],
# Sets to OAuth 2.0 Authorization Code flow
auth_flow="USER_FEDERATION",
# Prints authorization URL to console
on_auth_url=lambda x: print("\nPlease copy and paste this URL in your browser:\n" + x),
# If false, caches obtained access token
force_authentication=False,
)
async def write_to_google_drive(*, access_token: str):
# Prints the access token obtained from Google
print(access_token)
asyncio.run(write_to_google_drive(access_token=""))
先ほど述べた通り AgentCore Identity 自体に Provider の機能はないため、 @requires_access_token で指定している "google-provider" は事前に作成しておく必要があります。
aws bedrock-agentcore-control create-oauth2-credential-provider \
--region us-east-1 \
--name "google-provider" \
--credential-provider-vendor "GoogleOauth2" \
--oauth2-provider-config-input '{
"googleOauth2ProviderConfig": {
"clientId": "<your-google-client-id>",
"clientSecret": "<your-google-client-secret>"
}
}'
credential-provider-vendor に指定可能な Provider はドキュメントで確認できます。
AgentCore Identity を使用することで、Runtime や Gateway を利用するために指定された Provider への Credential 取得が容易になります。
AgentCore Observability による行動記録
AI エージェントでは行動記録も重要になるとお話ししました。AgentCore 上の各サービスで行われたインタラクションは、AgentCore Observability により収集されモニタリングが出来ます。もちろん、AgentCore Identity のログも記録されるため誰がエージェントを使用したかなどを監視できます。

具体的に見ていきましょう。AWS の AgentCore ハンズオンの実装を使います。 以下は、Lab 3 の AgentCore Identity まで進めたところです。Lab 3 で作成した AgentCore Identity で Trace をオンにしておきます (画像はすでに Trace を ON にしています)。

テストコードを実行した後、Observability で挙動を確認します。AgentCore Identity でアクセストークンを取得し、認証を行った AgentCore Runtime を選択します (選択するとエンドポイントが表示されるので DEFAULT のリンクから遷移します)。

図の箇所で、AgentCore Runtime に設定された認証 (Runtime から見たときは Inbound 認証) が呼ばれた回数、うまく取得出来た/エラーになった回数を参照できます。認証エラーなどにスパイクが出てないか観測することが出来ます。

AgentCore Runtime の認証を通過するためのアクセストークンは AgentCore Identity によって取得しているのでした。そちらも確認してみましょう。

表示されるのに少し時間がかかりますが、AgentCore Identity が表示されます。AgentCore Identity から見ると Outbound である点に注意してください (User -> AgentCore Identity -(Outbound)-> 認証 -(Inbound)->AgentCore Runtime) という流れになってます。
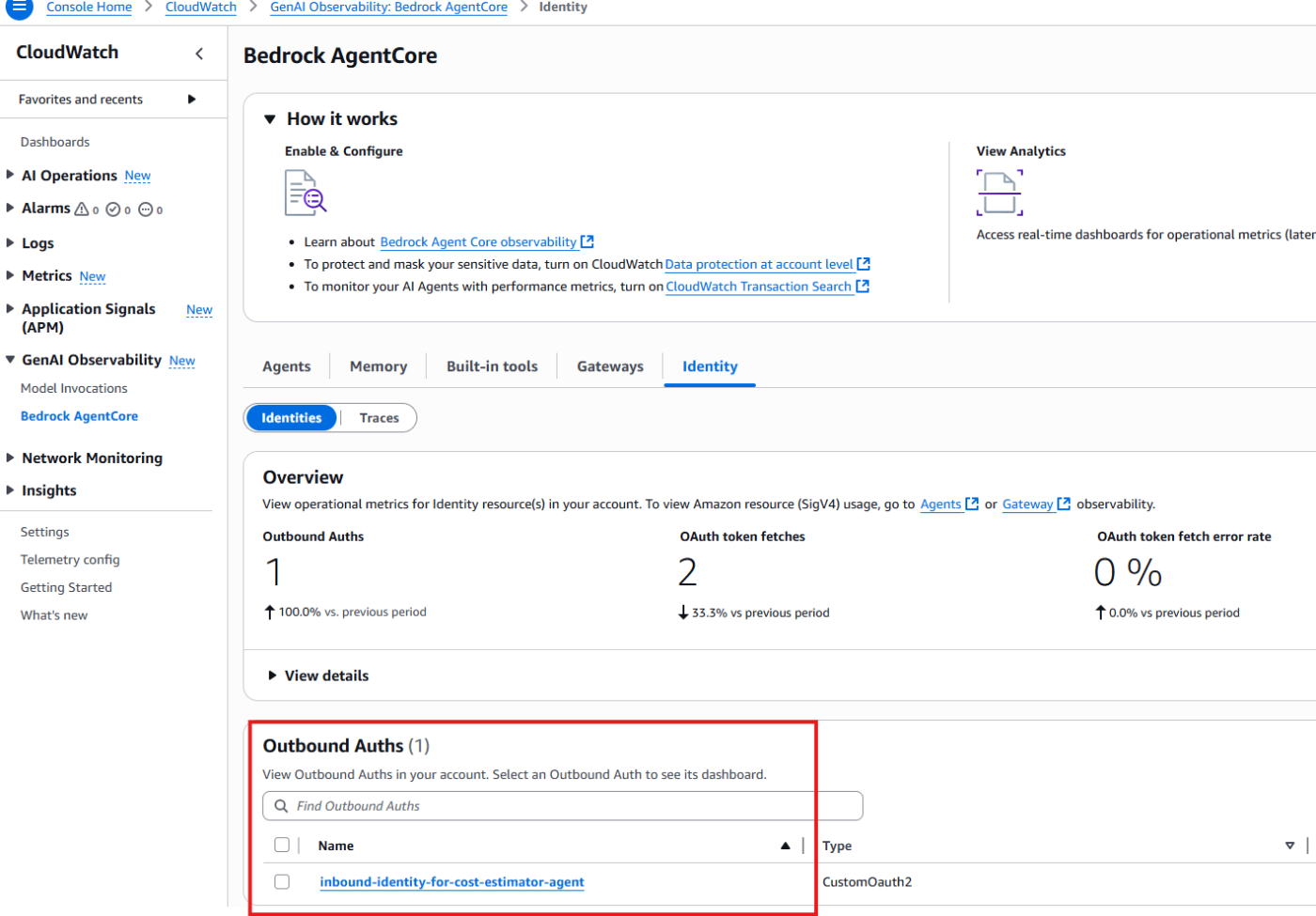
こちらでもトークンが取得できたかわかります。

Trace からは Credential Provider へのリクエストを確認できます。

これらの行動記録は、1) エージェントにアクセスする際、正統な認証確認が行われたか 2) 認証するための手続きは正当に行われたか、の 2 点を追跡可能にします。
OpenTelemetryベースでログの収集が行われるため、Langfuse などに転送すればそちらでモニタリングを行うこともできます。
まとめ:AI エージェント時代のセキュリティリスク対策
本記事では、AI エージェント独自のリスクの特定と、対応策として認証認可の基本的な仕組み、AgentCore による実装と行動追跡について解説しました。冒頭お話しした通り、リスク対策は AI エージェントの活用を持続的に行っていく長期的な取り組みに欠かせないだけでなく、短期的にコストモニタリングの解像度向上や内部統制監査等のガバナンス対応の省力化という点でもメリットがあります。
AgentCore Identity を使えば様々な Provider に対応した認証・認可の実装を手軽に行うことが出来、AgentCore Observability により細かな追跡が行えることを示しました。ぜひ、面倒と思わずリスク対策にチャレンジいただければ幸いです!
参考リンク

この Publication に投稿している記事は、アマゾン ウェブ サービス ジャパン合同会社または Amazon Web Services, Inc. 所属社員による個人の見解であり、所属する組織の公式見解ではありません。参加したい従業員の方は、Sugiyama Suguru までお知らせください。
Discussion