こんにちは! AWS でソリューションアーキテクトをしているこば D( https://x.com/kobayasd ) です。本ブログは AWS AI Agent ブログ祭り(Zenn: #awsaiagentblogfes, X: #AWS_AI_AGENT_ブログ祭り)の第 2 日目です。私は「AgentCore Memory」をテーマに、入門記事を書かせていただきます✌
Amazon Bedrock AgentCore Memory とはなんぞや
AgentCore ファミリーの中で記憶を司っているのが AgentCore Memory。簡単に言うと、AI エージェントに「記憶」を持たせるためのマネージドサービスです。個人でパーソナルアシスタント的な AI エージェントを作ろうとすると、この記憶まわりの設計や実装がわりと面倒だったりするんですが、そのへんをよしなにマネージドしてくれるニクい奴です。
Memory機能の仕組み
AgentCore Memoryは 「短期記憶」と「長期記憶」の 2種類の記憶を持っています。
短期記憶(Short-term Memory)
短期記憶は「直近の会話履歴」だと考えるとわかりやすいです。AI エージェントとおこなった会話のやりとりを「イベント」としてそのまま保存します。生成 AI のモデル自体は記憶を保持しているわけではなく、ステートレスになっています。そのため、LLM と会話する際には都度過去の会話履歴を渡して推論を行いますが、その履歴を保持してくれるイメージですね。例えば以下のような感じで短期記憶は保存されていきます。
🧔User: 「今日の晩ご飯、何作ろうかな」
🤖Agent: 「冷蔵庫に何が入ってますか?」
🧔User: 「鶏肉と玉ねぎとトマト缶がある」
🤖Agent: 「それなら、チキンのトマト煮込みはどうでしょう?」
🧔User: 「いいね!作り方教えて」
🤖Agent: 「鶏肉、玉ねぎ、トマト缶を使ったレシピですね。まず鶏肉に塩コショウを...」
一見すると当たり前のような機能ですが、こちらをきちんと保持しようとすると DynamoDB などに会話履歴テーブルを用意し、保存したり、読み出したりする処理を書かないといけません。この面倒さを解消してくれるのが AgentCore Memory の短期記憶機能です。
ユーザー/セッションごとに会話履歴をマネージドに保持してくれるほか、会話履歴は 7 日〜最長 365 日保存可能です(デフォルトは 90 日)。
ユーザーのパーソナルアシスタントエージェントを作るなら、ユーザーの好みや性格をきちんと記憶しておく必要があります。ですが、短期記憶を毎回全部 LLM に突っ込むのはトークン量が肥大してしまい、お財布に優しくありません。
そこで登場するのが長期記憶です!
長期記憶(Long-term Memory)
長期記憶は短期記憶から 重要な情報を自動で抽出 して、長期保存してくれる機能です。どういうことかというと、例えば「私はポメラニアンを飼っています」という会話から、「ユーザーはポメラニアンを飼っている」 という事実を勝手に抽出し、端的に保存してくれます。
抽出された長期記憶は、自然言語でセマンティック検索できます。記憶は自動的にベクトル化され、「このユーザーの趣味は?」といった曖昧な質問でも関連する情報を relevance score(どれぐらいの関連性があるか、のスコア) 付きで返してくれます。ベクトルDBや埋め込みモデルといったインフラは全て AgentCore Memory が裏側で管理してくれるので、開発者はクエリを投げるだけで OK です。
また、この長期記憶化にあたっての短期記憶からの情報抽出は「戦略(Strategy)」で選ぶことができます。
1. Semantic Strategy(事実)
会話から大切な情報や、事実を見つけて抽出してくれます。
「私の名前は太郎です」→「ユーザー名は太郎」として記録
「エンジニアとして働いています」→「職業:エンジニア」として記録
「東京に住んでいます」→「東京在住」として記録
2. User Preference Strategy(ユーザーの好み)
ユーザーの好みや傾向を見つけて抽出します。
「暗い画面の方が目に優しくていいよね」→「ダークモードを好む」
「もっと中学生にもわかるように教えて」→「わかりやすさ優先の説明を求める傾向」
「今日は1日中技術書を読んでたんだよね」→「技術的な話題を好む」
3. Summary Strategy(要約)
会話セッション全体を要約して保存します。
ユーザー:「今度の週末、京都に行きたいんだけど」
AI:「いいですね!何泊の予定ですか?」
ユーザー:「1泊2日で。おすすめの観光スポットある?」
AI:「清水寺、金閣寺、伏見稲荷大社がおすすめです」
ユーザー:「宿は駅近がいいな」
AI:「京都駅周辺のホテルを探しましょうか」
といった会話があったとしたら、下のようにぎゅっと要約してくれます。
「週末の京都旅行(1泊2日)を計画。清水寺・金閣寺・伏見稲荷を候補に。宿泊は京都駅周辺を希望。」
これらの戦略はビルトインで用意されており、AgentCore Memory を作成した際に設定をしておけば、短期記憶から自動的に抽出・保存が行われます。
実際に動かしてみる
では早速、Memory 機能付きエージェントを作ってみましょう!
手順0:前提条件
以下の IAM 権限が必要になります。
-
bedrock-agentcore:*(Memory の作成・読み書き用) -
bedrock:InvokeModel(モデル実行用)
必要なパッケージもインストールしておきましょう。
# 仮想環境の作成
uv venv
# パッケージのインストール
uv pip install strands-agents bedrock-agentcore boto3 streamlit
手順1: Memory リソースの作成
まずは記憶を保存するための AgentCore Memoryリソースを作成します。
from bedrock_agentcore.memory import MemoryClient
# リージョンはお好みで!
client = MemoryClient(region_name="us-east-1")
try:
memory = client.create_memory(
name="PersonalAssistantMemory",
strategies=[
{
'semanticMemoryStrategy': { # これが事実記憶用
'name': 'facts_extractor',
'namespaces': ['/app/{actorId}/facts']
}
},
{
'userPreferenceMemoryStrategy': { # ユーザーの好み
'name': 'preferences_tracker',
'namespaces': ['/app/{actorId}/preferences']
}
},
{
'summaryMemoryStrategy': { # 要約
'name': 'session_summarizer',
'namespaces': ['/app/{actorId}/session/{sessionId}']
}
}
],
description="パーソナルアシスタント用メモリ"
)
memory_id = memory['id']
print(f"Memory ID: {memory_id}")
except Exception as e:
print(f"Failed to create memory: {e}")
print("IAM権限を確認してください")
実行結果
以下のような形で、Memory ID が出力されれば OK です。これで AgentCore Memory リソースが作成され、記憶が保持できるようになりました。
Memory ID: PersonalAssistantMemory-xxxxxxxxxxxx
ちなみに、ちょっと補足しておくと、Memory を作成する際に以下のように 3 つの Strategy を設定しました。そのなかでnamespace を指定しています。
strategies=[
{
'semanticMemoryStrategy': { # これが事実記憶用
'name': 'facts_extractor',
'namespaces': ['/app/{actorId}/facts']
}
},
{
'userPreferenceMemoryStrategy': { # ユーザーの好み
'name': 'preferences_tracker',
'namespaces': ['/app/{actorId}/preferences']
}
},
{
'summaryMemoryStrategy': { # 要約
'name': 'session_summarizer',
'namespaces': ['/app/{actorId}/session/{sessionId}']
}
}
],
namespace とは何か?
namespace は、Memory を階層的に整理するための仕組みです。ファイルシステムのディレクトリ構造のようなイメージです。(厳密には違うのですが、わかりやすいのであえて)
/app/ ← さっき作った Memory リソース
├─ user_taro/ ← Actor Id (ユーザーとしての階層)
│ ├─ facts/ ← Semantic 戦略(事実を記憶する)
│ │ └─ (「AWS の認定資格を持っている」「ポメラニアンを飼っている」など)
│ ├─ preferences/ ← Preference 戦略(好みを記憶)
│ │ └─ (「技術的な話題を好む」「ダークモードを好む」など)
│ └─ session/
│ ├─ session_001/ ← Summary 戦略(セッション要約)
│ │ └─ (「週末の旅行計画について相談」)
│ └─ session_002/
│ └─ (「AgentCore Memory について相談」)
│
└─ user_hanako/ ← 別ユーザー
└─ ...
この構造によって、簡単に「ユーザーごと」「セッションごと」「戦略ごと」に記憶を保持できるようになります。より具体的に、同じユーザー(user_taro)が 2 つのセッションで会話した場合を整理してみるとこんなかんじです。
| 記憶の種類 | namespace | 保存内容 |
|---|---|---|
| 事実(Semantic) | /app/user_taro/facts |
「ポメラニアンを飼っている」「最近風邪を引いた」 |
| 好み(Preference) | /app/user_taro/preferences |
「技術的な話題を好む」「ラーメンが好き」 |
| セッション1の要約 | /app/user_taro/session/session_001 |
「週末の旅行計画について相談」 |
| セッション2の要約 | /app/user_taro/session/session_002 |
「AgentCore Memory について相談」 |
少し話題が逸れましたが、実際にこの機能を Agent に組み込んでいきましょう!
手順2:StreamlitでUIを作成し、Strands Agentsで動かす
せっかくなので、Streamlit でチャット UI を作って実際に動かしてみます。AI エージェントを動かすフレームワークには Strands Agents を使います。
"""
手順2: StreamlitでUIを作成し、Strands Agentsで動かす
AgentCore Memory を使ったチャットアプリケーション
"""
import streamlit as st
import asyncio
from strands import Agent
from strands.models import BedrockModel
from bedrock_agentcore.memory.integrations.strands.config import (
AgentCoreMemoryConfig,
RetrievalConfig,
)
from bedrock_agentcore.memory.integrations.strands.session_manager import (
AgentCoreMemorySessionManager,
)
# 手順1で取得した Memory ID を設定
MEMORY_ID = "{作成した Memory ID}"
# タイトル
st.title("AgentCore Memory Chat")
st.caption(f"Memory ID: {MEMORY_ID}")
# 初期化(セッション状態で管理)
if 'agent' not in st.session_state:
# Bedrockモデルの設定
model = BedrockModel(
model_id="us.anthropic.claude-haiku-4-5-20251001-v1:0",
region_name="us-east-1",
temperature=0.7,
max_tokens=2048,
)
# Memory設定
memory_config = AgentCoreMemoryConfig(
memory_id=MEMORY_ID,
actor_id="user_taro",
session_id="session_001", # ここを変更するとセッションが変わります
retrieval_config={
"/app/user_taro/facts": RetrievalConfig(
top_k=100, # 事実は多く取得
relevance_score=0.0 # スコア制限なし
),
"/app/user_taro/preferences": RetrievalConfig(
top_k=10, # 好みは厳選
relevance_score=0.5 # 高スコアのみ
),
"/app/user_taro/session/session_001": RetrievalConfig(
top_k=5,
relevance_score=0.5
)
}
)
# セッションマネージャー
session_manager = AgentCoreMemorySessionManager(
agentcore_memory_config=memory_config,
region_name="us-east-1",
)
# システムプロンプト
system_prompt = """あなたは親しみやすいアシスタントです。
過去の会話内容を自然に活用してください。
重要:
- 記憶している情報を露骨に列挙しない
- 「覚えている」と強調しない
- 過去の情報は文脈の中で自然に織り込む
"""
# エージェント作成
st.session_state.agent = Agent(
name="MyMemoryAgent",
model=model,
system_prompt=system_prompt,
session_manager=session_manager,
)
st.session_state.messages = []
# チャット履歴の表示
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# チャットUI
if prompt := st.chat_input("メッセージを入力..."):
# ユーザーメッセージを履歴に追加して表示
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# アシスタント応答を取得して表示
with st.chat_message("assistant"):
with st.spinner("考え中..."):
response = asyncio.run(st.session_state.agent.invoke_async(prompt))
# レスポンスからテキストを抽出
if isinstance(response.message, dict):
content = response.message.get('content', [])
text = content[0].get('text', '') if content else ''
else:
text = str(response.message)
st.markdown(text)
# アシスタントメッセージを履歴に追加
st.session_state.messages.append({"role": "assistant", "content": text})
上記を app.py として保存し、以下のコマンドで実行することができます。
uv run streamlit run app.py
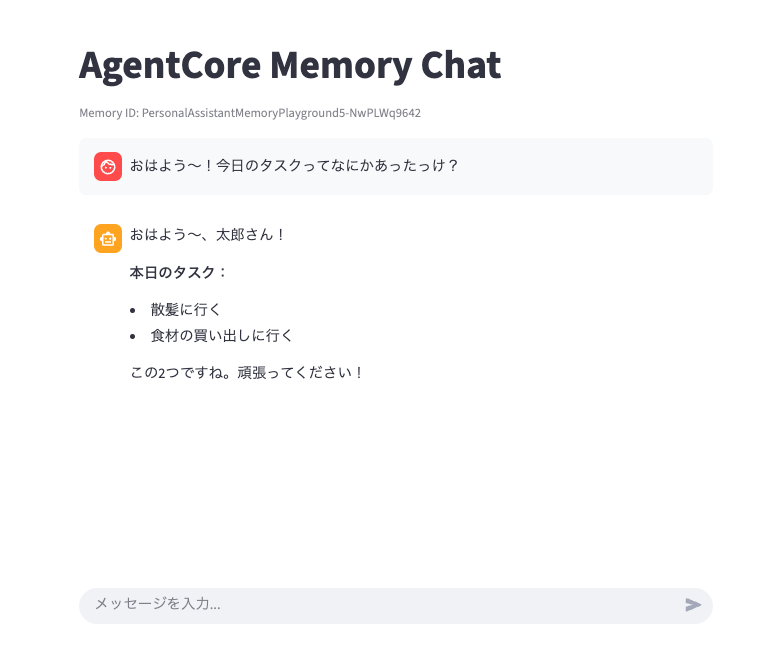
上の画像は「今日やるべきタスク」を記憶させた後、session id を変更し、新しいセッションで今日のタスクについて聞いてみた際のキャプチャです。ちゃんとタスクを覚えておいてくれていますね。
Streamlit のコードのうち、AgentCore の Memory に関連する部分を少し見ていきましょう。
session_manager がとても便利
Strands Agents で AgentCore Memory を使う際は memory_config で AgentCore Memory の設定を行い session_manager を Agent に渡すだけで記憶機能を動かすことができて便利です。
# AgentCore Memory の設定
memory_config = AgentCoreMemoryConfig(
memory_id=MEMORY_ID,
actor_id="user_taro",
session_id="session_001", # ここを変更するとセッションが変わります
retrieval_config={
"/app/user_taro/facts": RetrievalConfig(
top_k=100, # 事実は多く取得
relevance_score=0.0 # スコア制限なし
),
"/app/user_taro/preferences": RetrievalConfig(
top_k=10, # 好みは厳選
relevance_score=0.5 # 高スコアのみ
),
"/app/user_taro/session/session_001": RetrievalConfig(
top_k=5,
relevance_score=0.5
)
}
)
# Session Manager を作成
session_manager = AgentCoreMemorySessionManager(
agentcore_memory_config=memory_config,
region_name="us-east-1",
)
# Agent に渡すだけで Memory 機能が利用できる
agent = Agent(
name="MyMemoryAgent",
model=model,
system_prompt=system_prompt,
session_manager=session_manager,
)
retrieval_config
retrieval_config では、記憶を検索する際のパラメータを namespace ごとに設定できます。以下のように、記憶戦略ごとに値を変えたりすることも可能です。
-
top_k: 取得する記憶の最大数 -
relevance_score: 関連性スコアの閾値(0〜1の範囲)
retrieval_config={
"/app/user_taro/facts": RetrievalConfig(
top_k=100, # 事実は多く取得(最大100件)
relevance_score=0.0 # スコア制限なし = 疑似的に全件取得
),
"/app/user_taro/preferences": RetrievalConfig(
top_k=10, # 好みは厳選(最大10件)
relevance_score=0.5 # 関連性スコア 0.5 以上の高スコアのみ
),
"/app/user_taro/session/session_001": RetrievalConfig(
top_k=5, # セッション要約は少なめ
relevance_score=0.5 # 関連性スコア 0.5 以上
)
}
手順4:AWS CLIで記憶を確認してみる
エージェントが実際に何を記憶しているのかは AWS CLI でも確認できます。(コンソールから確認できるともっと便利なのですが・・・)
Memory情報の取得
まず、Memoryリソースの状態を確認します。
aws bedrock-agentcore-control get-memory \
--memory-id {作成した Memory ID} \
--region us-east-1
レスポンスはこんな感じです。
{
"id": "mem-xxxxxxxxxxxx",
"arn": "arn:aws:bedrock-agentcore:us-east-1:123456789012:memory/mem-xxxxxxxxxxxx",
"name": "my-assistant-memory",
"description": "パーソナルアシスタント用メモリ",
"status": "ACTIVE",
"memoryStrategies": [
{
"memoryStrategyId": "strategy-facts-extractor",
"type": "SEMANTIC",
"namespaces": ["/app/{actorId}"]
},
{
"memoryStrategyId": "strategy-preferences-tracker",
"type": "USER_PREFERENCE",
"namespaces": ["/app/{actorId}"]
}
],
"createdAt": "2025-10-26T10:00:00Z",
"updatedAt": "2025-10-26T10:00:00Z"
}
Short-term Memory(会話履歴)の確認
セッション内の会話イベントを確認できます。
aws bedrock-agentcore list-events \
--memory-id {作成した Memory ID} \
--actor-id user_taro \ # ここでユーザー ID を指定
--session-id session_20250126 \ # ここでセッション ID を指定
--include-payloads \
--region us-east-1
レスポンス例:
{
"events": [
{
"eventId": "evt-1",
"timestamp": "2025-10-26T10:05:00Z",
"payload": {
"conversationalMessage": {
"role": "USER",
"message": "こんにちは!私は太郎といいますです"
}
}
},
{
"eventId": "evt-2",
"timestamp": "2025-10-26T10:05:05Z",
"payload": {
"conversationalMessage": {
"role": "ASSISTANT",
"message": "こんにちは!太郎さん、よろしくおねがいします。"
}
}
}
]
}
よくある生成 AI チャットの会話履歴のような形でデータが保存されていますね。
Long-term Memory の確認
短期記憶から自動的に抽出された、長期記憶情報も確認できます。試しに適当な会話を 10 ターンほど行った後、長期記憶がどうなっているのか確認してみました。
1. Semantic Strategy(事実)の確認
aws bedrock-agentcore list-memory-records \
--memory-id {作成した Memory ID} \
--namespace /app/user_taro/facts \
--region us-east-1
結果、以下のような形で、短期記憶の内容から端的に「事実」が抽出されて保存されていました。元の会話よりだいぶ圧縮されており、トークン効率よくチャットアプリに利用できそうです。
{
"memoryRecordSummaries": [
{"content": {"text": "ユーザーはAWS認定資格を保持しています"}},
{"content": {"text": "ユーザーは最近、自然言語処理に興味を持っています。"}},
{"content": {"text": "ユーザーの名前は太郎です。"}},
{"content": {"text": "ユーザーはダークモードが好きで、画面が暗い方が目に優しいと考えています。"}},
{"content": {"text": "太郎の出身は東京です。"}},
{"content": {"text": "太郎は在宅ワークが多いです。"}},
{"content": {"text": "太郎はたまにカフェで作業するのが好きです。"}}
]
}
2. User Preference Strategy(好み)の確認
aws bedrock-agentcore list-memory-records \
--memory-id {作成した Memory ID} \
--namespace /app/user_taro/preferences \
--region us-east-1
こちらも Semantic(事実)のほうと同様に、好みが抽出されています。
{
"memoryRecordSummaries": [
{
"content": {
"text": "{\"context\":\"ユーザーは自己紹介で明示的に自分がAWSエンジニアであると述べています。\",\"preference\":\"AWSを使用している\",\"categories\":[\"プログラミング\",\"キャリア\",\"技術\"]}"
}
},
{
"content": {
"text": "{\"context\":\"ユーザーは明示的に自然言語処理に興味があると述べています。\",\"preference\":\"自然言語処理に興味がある\",\"categories\":[\"技術\",\"AI\",\"自然言語処理\"]}"
}
},
{
"content": {
"text": "{\"context\":\"ユーザーが明示的に自分はダークモードが好きで画面が暗い方が目に優しいと言及しています。\",\"preference\":\"ダークモードが好き\",\"categories\":[\"表示設定\",\"UI環境設定\"]}"
}
},
{
"content": {
"text": "{\"context\":\"ユーザーは在宅ワークが多いが、カフェでも作業することがあると明示的に述べている。\",\"preference\":\"在宅ワークが多いがカフェでの作業も好き\",\"categories\":[\"ワークスタイル\",\"作業環境\"]}"
}
}
]
}
こちらは Semantic Strategy よりも詳細な形で、文脈(context)とカテゴリ(categories)が付与されていますね。
3. Summary Strategy(要約)の確認
最後は Summary (要約)の確認です。
aws bedrock-agentcore list-memory-records \
--memory-id {作成した Memory ID} \
--namespace /app/user_taro/session/session_001 \
--region us-east-1
こちらは会話セッションごとの要約になっているので、session_001 の内容が要約されています。
{
"memoryRecordSummaries": [
{
"content": {
"text": "<topic name=\"初期の会話\">\nユーザーはAWSエンジニアとして自己紹介し、アシスタントはそれに対して挨拶し、何か手伝えることがあるか尋ねました。\n</topic>\n\n<topic name=\"ユーザーの趣味\">\nユーザーは機械学習の勉強を趣味にしていると伝えました。\n</topic>\n\n<topic name=\"テキスト分類の実装希望\">\nユーザーはHuggingFaceのライブラリを使ってテキスト分類を試してみたいという希望を伝えました。\n</topic>\n\n<topic name=\"ユーザー名の共有\">\nユーザーは自分の名前が太郎であることを伝えました。\n</topic>\n\n<topic name=\"ダークモードの好み\">\nユーザーはダークモードが好きで、画面が暗い方が目に優しいと伝えました。\n</topic>"
}
}
]
}
topic という単位で構造化されて要約されていますね。これらのように、会話内容が自動的に「長期記憶」として保持されていることが確認しました!
セマンティック検索で記憶を探す
また、自然言語で記憶を検索することもできます。実際に「事実」から「このユーザーの職業は何?」と探してみます。
aws bedrock-agentcore retrieve-memory-records \
--memory-id {作成した Memory ID} \
--namespace /app/user_taro/facts \
--search-criteria '{
"searchQuery": "このユーザーの職業は何?",
"topK": 3
}' \
--region us-east-1
すると、以下のように関連する記憶が検索結果として表示されます。便利ですね。
{
"memoryRecordSummaries": [
{
"content": {
"text": "ユーザーはAWSエンジニアです。ユーザーの趣味は機械学習の勉強です。"
},
"score": 0.44947118
},
{
"content": {
"text": "ユーザーは自然言語処理について勉強しています。"
},
"score": 0.42335585
},
{
"content": {
"text": "ユーザーはAWSについて勉強しています。"
},
"score": 0.4153134
}
]
}
おわりに
AgentCore Memory について、主要な機能をざっと触ってみました。実際にはこの記事で紹介した 3 つの Memory Strategy 以外にも、ユーザーが自分で長期記憶戦略を設定できるカスタム機能などもあります。ぜひ AgentCore Memory を触ってみて、面白いユースケースがあれば教えて下さい!

この Publication に投稿している記事は、アマゾン ウェブ サービス ジャパン合同会社または Amazon Web Services, Inc. 所属社員による個人の見解であり、所属する組織の公式見解ではありません。参加したい従業員の方は、Sugiyama Suguru までお知らせください。
Discussion