いい Agent 作ろうぜ!ってことで Anthropic が Writing effective tools for agents — with agents という記事をだしたので和訳です。これ見ていい Agent を作りましょう。
Agents のための効果的な Tool を Agent で記述する
Agentは、私たちが与えるツールと同じくらい効果的です。高品質なツールと評価の書き方、そして Claude を使って自身の tool を最適化することでパフォーマンスを向上させる方法を共有します。
Model Context Protocol (MCP) は、LLM Agent に数百の tools を提供し、現実世界のタスクを解決する力を与えることができます。しかし、これらの tools を最大限効果的にするにはどうすればよいでしょうか?
この投稿では、さまざまな Agentic AI システムのパフォーマンスを向上させるための最も効果的な技術について説明します。
まず、以下の方法について説明します:
- Tool のプロトタイプを構築してテストする
- Agent を使った Tool の包括的な評価を作成して実行する
- Claude Code(訳者追記: Amazon Q Developer, Kiro でもいいと思うよ!) のような Agent と協力して Tool のパフォーマンスを自動的に向上させる
最後に、その過程で特定した高品質な Tool を書くための重要な原則で締めくくります:
- 実装すべき(および実装すべきでない)適切な Tool の選択
- 機能の明確な境界を定義するための Tool の名前空間化
- Tool から Agent への意味のあるコンテキストの返却
- トークン効率のための Tool レスポンスの最適化
- Tool の説明と仕様のプロンプトエンジニアリング

評価を構築することで、tools のパフォーマンスを体系的に測定できます。この評価に対して tools を自動的に最適化するために Claude Code (Amazon Q でも以下略)を使用できます。
Tool is 何?
コンピューティングにおいて、決定論的システムは同一の入力が与えられると毎回同じ出力を生成しますが、非決定論的システム(Agentなど)は同じ開始条件でも様々な応答を生成することができます。
従来のソフトウェア開発では、決定論的システム間の契約を確立しています。例えば、getWeather("NYC") のような関数呼び出しは、呼び出されるたびに常に全く同じ方法でニューヨーク市の天気を取得します。
Tools は、決定論的システムと非決定論的 Agent の間の契約を反映する新しい種類のソフトウェアです。ユーザーが「今日は傘を持参すべきですか?」と尋ねた場合、Agent は weather tool を呼び出したり、一般知識から答えたり、まず場所について明確化の質問をしたりする可能性があります。時折、Agent は hallucination を起こしたり、Tools の使用方法を理解できなかったりすることもあります。
これは、Agent 向けのソフトウェアを書く際のアプローチを根本的に再考することを意味します。他の開発者やシステム向けに関数やAPIを書く方法で Tools や MCP サーバーを書くのではなく、Agent 向けに設計する必要があります。
我々の目標は、Agent が Tools を使用して様々な成功戦略を追求することで、幅広いタスクを解決する際に効果的になれる表面積を増やすことです。幸い、我々の経験では、Agent にとって最も「人間工学的」な Tools は、人間にとっても驚くほど直感的に理解できるものになることが分かっています。
(訳者追記:人間が書くものというのは人間のコミュニケーション能力依存で、だいたいにおいてもはや AI(Agent) に負けるから黙って AI にツール等を書かせておけ、人間は意思を示すだけでええんや、という理解です)
Tools の書き方
このセクションでは、Agent と協力して、Agent に提供する Tools を書き、改善する方法について説明します。まず、Tools の簡単なプロトタイプを立ち上げ、ローカルでテストしてください。次に、包括的な評価を実行して、その後の変更を測定します。Agent と協力して、Agent が実世界のタスクで強力なパフォーマンスを達成するまで、Tools を評価し改善するプロセスを繰り返すことができます。
プロトタイプの構築
Agent がどの Tool を使いやすいと感じ、どの Tool を使いにくいと感じるかを、実際に手を動かさずに予測するのは困難です。まずは Tool の簡単なプロトタイプを立ち上げることから始めましょう。Claude Code を使って Tool を作成する場合(ワンショットでの作成も可能)、Tool が依存するソフトウェアライブラリ、API、SDK(MCP SDK を含む可能性もあります)のドキュメントを Claude (Amazon Q Dev 以下略) に提供すると効果的です。LLM に適したドキュメントは、公式ドキュメントサイトのフラットな llms.txt ファイルでよく見つけることができます(こちらが Anthropic API の例)。
Tool をローカルの MCP サーバーまたは Desktop extension(DXT)でラップすることで、Claude Code または Claude Desktop アプリ(または Amazon Q Dev 以下略)で Tool を接続してテストできるようになります。
ローカルの MCP サーバーを Claude Code に接続するには、claude mcp add <name> <command> [args...] (Amazon Q Dev の場合は qchat mcp add …詳細はこちら) を実行してください。
ローカルの MCP サーバーまたは DXT を Claude Desktop アプリに接続するには、それぞれ 設定 > Developer または 設定 > Extensions に移動してください。
Tool はプログラマティックなテストのために Anthropic API コールに直接渡すこともできます。
自分で Tool を実際に使ってみて、使いにくい部分がないかチェックしましょう。また、ユーザーの声を集めて、どんな場面でどんな使い方をされるのか、肌感覚で理解できるようになりましょう。
評価を実行
次に、Claude(任意の LLM と読み替えて良い) があなたの Tools をどの程度うまく使用するかを 評価を実行して測定する必要があります。まず、現実世界での使用に基づいた多くの Evaluation タスクを生成することから始めてください。結果を分析し、Tools を改善する方法を決定するために Agent とコラボすることをお勧めします。このプロセスの全体像については、私たちの tool evaluation cookbook をご覧ください。

我々の内部 Slack tools の Held-out テストセット性能(もはや人間が書くより AI に書かせたほうが性能がいい)
評価タスクの生成
初期のプロトタイプを使用して、Claude Code (Ama以下略)はあなたの Tools を素早く探索し、数十のプロンプトとレスポンスのペアを作成できます。プロンプトは実世界での使用例からインスピレーションを得て、現実的なデータソースやサービス(例:内部の Knowledge Bases や Microservices )に基づいている必要があります。十分な複雑さで Tools をストレステストしない、過度に単純化された表面的な「サンドボックス」環境は避けることをお勧めします。強力な評価タスクには複数の Tool 呼び出しが必要な場合があります(場合によっては数十回)。
以下は強力なタスクの例です:
- 来週 Jane との会議をスケジュールして、最新の Acme Corp プロジェクトについて話し合う。前回のプロジェクト計画会議のメモを添付し、会議室を予約する。
- 顧客 ID 9182 が、1 回の購入試行に対して 3 回請求されたと報告した。関連するすべてのログエントリを見つけ、同じ問題の影響を受けた他の顧客がいるかどうかを判断する。
- 顧客 Sarah Chen がキャンセル要求を提出した。リテンション オファーを準備する。以下を判断する:(1)なぜ離脱するのか、(2)どのようなリテンション オファーが最も魅力的か、(3)オファーを行う前に認識すべきリスク要因があるか。
そして以下は弱いタスクの例です:
- 来週 jane@acme.corp との会議をスケジュールする。
- payment logs で purchase_complete と customer_id=9182 を検索する。
- 顧客 ID 45892 によるキャンセル要求を見つける。
各評価プロンプトは、検証可能なレスポンスまたは結果とペアにする必要があります。あなたの verifier は、Ground Truth とサンプルレスポンス間の正確な文字列比較のようにシンプルなものでも、Claude にレスポンスを判定させるような高度なものでもかまいません。フォーマット、句読点、または有効な代替表現などの偽の違いにより正しいレスポンスを拒否する、過度に厳格な verifier は避けてください。
各プロンプト-レスポンスのペアについて、タスクを解決する際に Agent が呼び出すことを期待する Tools をオプションで指定することもでき、評価中に Agents が各 Tool の目的を正しく把握できているかどうかを測定できます。ただし、タスクを正しく解決するための有効なパスが複数存在する可能性があるため、戦略を過度に指定したり、過適合させたりしないよう注意してください。
評価の実行
評価は、直接的な LLM API 呼び出しを使用してプログラム的に実行することを推奨します。シンプルな agentic ループ( LLM API と tool 呼び出しを交互に行う while ループ)を使用してください:各評価タスクに対して 1 つのループです。各評価 Agent には、単一のタスク Prompt とあなたの Tools を与える必要があります。
評価 Agents の system prompts では、構造化された応答ブロック(検証用)だけでなく、推論とフィードバックブロックも出力するよう Agents に指示することを推奨します。 Tool 呼び出しと応答ブロックの前にこれらを出力するよう Agents に指示することで、chain-of-thought (CoT) 動作をトリガーし、 LLMs の効果的な知能を向上させる可能性があります。
Claude で評価を実行している場合は、類似の機能を「すぐに使える」形で提供するインターリーブ思考を有効にできます。これにより、Agents が特定の Tools を呼び出す理由や呼び出さない理由を調査し、 tool の説明と仕様の特定の改善領域を強調するのに役立ちます。
トップレベルの精度に加えて、個別の Tool 呼び出しとタスクの総実行時間、 Tool 呼び出しの総数、総トークン消費量、 Tool エラーなどの他のメトリクスを収集することを推奨します。 Tool 呼び出しを追跡することで、 Agents が追求する一般的なワークフローを明らかにし、 Tools を統合する機会を提供できます。

内部 Asana tools のホールドアウトテストセット性能
結果の分析
Agent は、矛盾する Tool の説明から非効率な Tool の実装、混乱を招く Tool スキーマまで、あらゆる問題を発見し、フィードバックを提供する頼もしいパートナーです。ただし、Agent がフィードバックや応答で省略することは、含めることよりもしばしば重要であることを覚えておいてください。LLM は必ずしも意図したことを言うとは限りません。
Agent が行き詰まったり混乱したりする場所を観察してください。評価 Agent の推論とフィードバック(または CoT)を読み通して、改善点を特定してください。生のトランスクリプト(Tool 呼び出しと Tool レスポンスを含む)を確認して、Agent の CoT で明示的に説明されていない動作を捉えてください。行間を読んでください。評価 Agent が必ずしも正しい答えや戦略を知っているわけではないことを覚えておいてください。
Tool 呼び出しメトリクスを分析してください。多くの冗長な Tool 呼び出しは、ページネーションやトークン制限パラメータの適正化が必要であることを示唆している可能性があります。無効なパラメータによる多くの Tool エラーは、Tool がより明確な説明やより良い例を使用できることを示唆している可能性があります。Claude の Web 検索 Tool をリリースした際、Claude が tool のクエリパラメータに不必要に2025を追加し、検索結果にバイアスをかけてパフォーマンスを低下させていることを特定しました(Tool の説明を改善することで Claude を正しい方向に導きました)。
複数 Agent の協調
Agent にあなたの結果を分析させ、あなたのために Tool を改善させることさえできます。評価 Agent からの記録を単純に連結して Claude Code(略)に貼り付けるだけです。Claude は記録を分析し、多くの Tool を一度にリファクタリングすることに長けています。例えば、新しい変更が行われた際に Tool の実装と説明の整合性を保つためなどです。
実際、この投稿のアドバイスの大部分は、Claude Code を使って内部の Tool 実装を繰り返し最適化することから得られました。私たちの評価は、実際のプロジェクト、文書、メッセージを含む内部ワークフローの複雑さを反映した内部ワークスペース上で作成されました。
「訓練」評価に過学習しないよう、ホールドアウトテストセットに依存しました。これらのテストセットにより、「専門家」による Tool 実装で達成したものを超えて、さらなる性能向上を抽出できることが明らかになりました。それらの Tool が研究者によって手動で書かれたものであろうと、Claude 自身によって生成されたものであろうと関係ありませんでした。
次のセクションでは、このプロセスから学んだことの一部を共有します。
効果的な Tools を書くための原則
このセクションでは、効果的な Tools を書くためのいくつかの指針となる原則に私たちの学びを蒸留します。
Agents に適した Tools を選ぶ
より多くの Tools が常により良い結果につながるとは限りません。私たちが観察した一般的な誤りは、既存のソフトウェア機能や API エンドポイントを単純にラップした Tools です(その Tools が Agents に適しているかどうかに関係なく。これは、Agents が従来のソフトウェアとは異なる「アフォーダンス」を持っているためです)。つまり、それらの Tools で取ることができる潜在的なアクションを知覚する方法が異なるのです。
LLM agents は限られた「コンテキスト」を持っています(つまり、一度に処理できる情報量に制限があります)が、コンピューターのメモリは安価で豊富です。アドレス帳で連絡先を検索するタスクを考えてみましょう。従来のソフトウェアプログラムは、連絡先のリストを効率的に保存し、一つずつ処理して、それぞれをチェックしてから次に進むことができます。
しかし、LLM agent がすべての連絡先を返す Tool を使用し、その後それぞれをトークンごとに読み通さなければならない場合、限られたコンテキストスペースを無関係な情報で無駄にしています(アドレス帳で連絡先を検索するのに、各ページを上から下まで読む、つまり総当たり検索で行うことを想像してください)。より良く、より自然なアプローチ(Agents と人間の両方にとって)は、まず関連するページにスキップすることです(おそらくアルファベット順で見つける)。
私たちは、評価タスクに合致し、そこからスケールアップできる特定の高インパクトワークフローをターゲットとした、少数の思慮深い Tools を構築することを推奨します。アドレス帳の場合、list_contacts Tool の代わりに search_contacts や message_contact Tool の実装を選択するかもしれません。
Tools は機能を統合し、内部的に複数の個別の操作(または API 呼び出し)を処理できます。例えば、Tools は関連するメタデータで Tool レスポンスを充実させたり、頻繁に連鎖する複数ステップのタスクを単一の Tool 呼び出しで処理したりできます。
以下にいくつかの例を示します:
-
list_users、list_events、create_eventtools を実装する代わりに、空き状況を見つけてイベントをスケジュールするschedule_eventtool の実装を検討してください。 -
read_logstool を実装する代わりに、関連するログ行といくつかの周辺コンテキストのみを返すsearch_logstool の実装を検討してください。 -
get_customer_by_id、list_transactions、list_notestools を実装する代わりに、顧客の最近の関連情報をすべて一度にコンパイルするget_customer_contexttool を実装してください。
構築する各 Tool が明確で異なる目的を持つことを確認してください。Tools は、Agents が同じ基盤リソースにアクセスできる人間と同じ方法でタスクを細分化し解決できるようにし、同時に中間出力によって消費されたであろうコンテキストを削減すべきです。
あまりにも多くの Tools や重複する Tools も、Agents が効率的な戦略を追求することから注意をそらす可能性があります。構築する(または構築しない)Tools の慎重で選択的な計画は、本当に報われることがあります。
Tools の名前空間
あなたの AI agents は、数十の MCP サーバーと数百の異なる Tools へのアクセスを潜在的に獲得します。これには他の開発者による Tools も含まれます。 Tools の機能が重複していたり、目的が曖昧だったりすると、 Agents はどの Tools を使用すべきか混乱する可能性があります。
名前空間(関連する Tools を共通のプレフィックスでグループ化すること)は、多くの Tools 間の境界を明確にするのに役立ちます。 MCP クライアントは時々これをデフォルトで行います。例えば、サービス別(例:asana_search 、jira_search)やリソース別(例:asana_projects_search、asana_users_search)で Tools に名前空間を付けることで、 Agents が適切なタイミングで適切な Tools を選択するのに役立ちます。
プレフィックスベースとサフィックスベースの名前空間のどちらを選択するかは、我々の Tool 使用評価に重要な影響を与えることがわかりました。効果は LLM によって異なるため、独自の評価に基づいて命名スキームを選択することをお勧めします。
Agents は間違った Tools を呼び出したり、正しい Tools を間違ったパラメータで呼び出したり、Tools を十分に呼び出さなかったり、Tool の応答を正しく処理しなかったりする可能性があります。タスクの自然な細分化を反映する名前の Tools を選択的に実装することで、 Agent のコンテキストにロードされる Tools とそれぞれの Tool の説明の数を同時に減らし、 Agentic な計算を Agent のコンテキストから Tool 呼び出し自体に移すことができます。これにより、Agent が間違いを犯す全体的なリスクが軽減されます。
Tools からの意味のあるコンテキストの返却
同様に、Tool の実装では Agent に対して高シグナルな情報のみを返すよう注意すべきです。柔軟性よりもコンテキストの関連性を優先し、低レベルの技術的識別子(例:uuid、256px_image_url、mime_type)は避けるべきです。name、image_url、file_type などのフィールドは、Agent の下流のアクションや応答に直接情報を提供する可能性がはるかに高いです。
Agent はまた、暗号的な識別子よりも自然言語の名前、用語、または識別子を扱う方が大幅に成功しやすい傾向があります。任意の英数字の UUID をより意味的に意味があり解釈可能な言語(または 0 インデックスの ID スキーム)に解決するだけで、hallucination を減らし検索タスクにおける Claude の精度が大幅に向上することがわかりました。
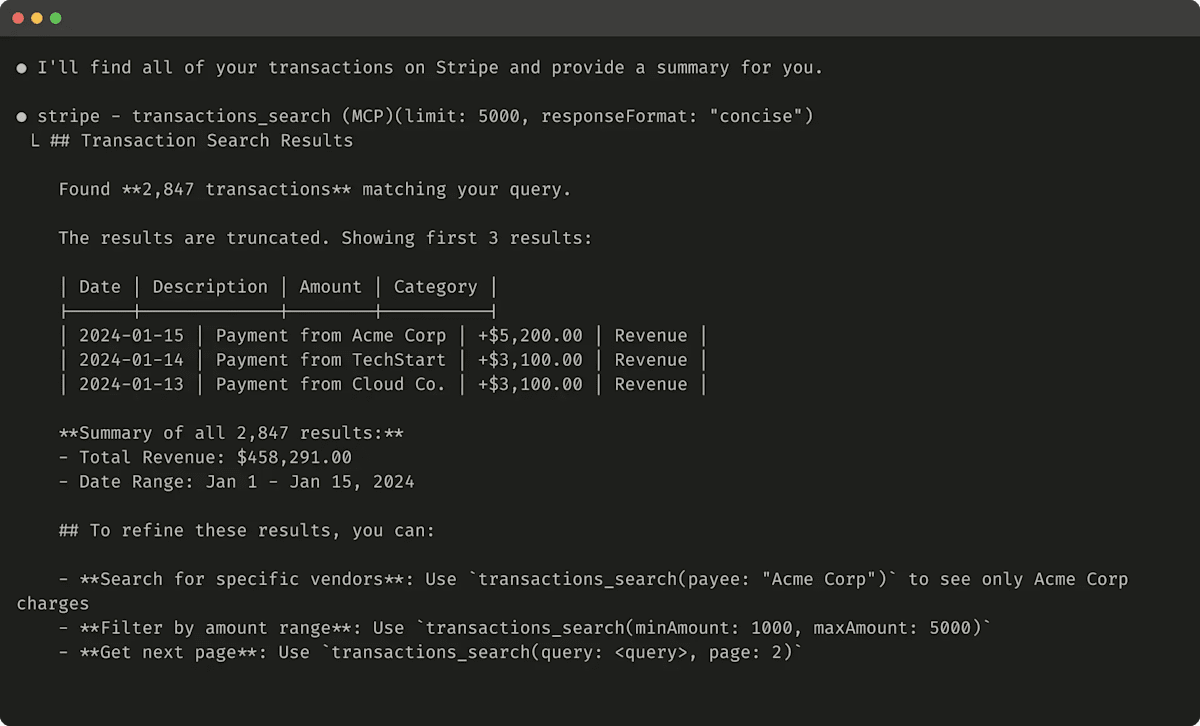
場合によっては、エージェントが自然言語と技術的な識別子の両方の出力を扱う柔軟性が必要になることがあります。これは、後続のツール呼び出しをトリガーするためだけであっても必要です(例:search_user(name='jane') → send_message(id=12345))。ツールにシンプルなresponse_format列挙型パラメータを公開することで、エージェントがツールから「簡潔な」応答か「詳細な」応答かを制御できるようになり、両方を有効にすることができます(下の画像参照)。
GraphQL と同様に、受信したい情報の部分を正確に選択できるように、さらなる柔軟性のためにより多くのフォーマットを追加できます。以下は、tool 応答の冗長性を制御する ResponseFormat enum の例です:
enum ResponseFormat {
DETAILED = "detailed",
CONCISE = "concise"
}
詳細な Tool レスポンスの例です(206 tokens):

以下は簡潔な Tool レスポンスの例です(72 tokens):

Slack スレッドとスレッド返信は、スレッド返信を取得するために必要な一意の thread_ts によって識別されます。thread_ts やその他の ID(channel_id、user_id)は、これらを必要とするさらなる Tool 呼び出しを可能にするために「詳細」Tool レスポンスから取得できます。「簡潔」Tool レスポンスはスレッドコンテンツのみを返し、ID は除外されます。この例では、「簡潔」Tool レスポンスでトークンの約1/3を使用しています。
Tool の応答構造でさえも(例えば XML、JSON、または Markdown)評価パフォーマンスに影響を与える可能性があります。万能な解決策は存在しません。これは LLM が次トークン予測で訓練されており、訓練データと一致する形式でより良いパフォーマンスを発揮する傾向があるためです。最適な応答構造は Task と Agent によって大きく異なります。独自の評価に基づいて最適な応答構造を選択することをお勧めします。
Token 効率のための Tool レスポンスの最適化
Context の品質を最適化することは重要です。しかし、Tool レスポンスで Agent に返される Context の量を最適化することも同様に重要です。
大量の Context を使用する可能性がある Tool レスポンスには、適切なデフォルトパラメータ値を持つページネーション、範囲選択、フィルタリング、および/または切り詰めの組み合わせを実装することを提案します。Claude Code では、Tool レスポンスをデフォルトで 25,000 Token に制限しています。Agent の有効な Context 長は時間とともに増加すると予想されますが、Context 効率的な Tool の必要性は残ると考えています。
レスポンスを切り詰めることを選択する場合は、有用な指示で Agent を導くようにしてください。知識検索タスクにおいて、単一の広範囲な検索ではなく、多くの小さく的を絞った検索を行うなど、より Token 効率的な戦略を追求するよう Agent を直接促すことができます。同様に、Tool 呼び出しがエラーを発生させた場合(例えば、入力検証中)、不透明なエラーコードやトレースバックではなく、具体的で実行可能な改善を明確に伝えるようにエラーレスポンスを Prompt エンジニアリングすることができます。
以下は切り詰められた Tool レスポンスの例です:
役に立たない Error レスポンスの例を以下に示します:

役に立つエラーレスポンスの例は以下の通りです:

Tool の切り詰めとエラー応答は、Agent をより Token 効率的な Tool 使用行動(フィルターやページネーションの使用)に導いたり、正しくフォーマットされた Tool 入力の例を提供したりできます。
Tool の説明をプロンプトエンジニアリングする
ここで、Tool を改善するための最も効果的な方法の一つである、Tool の説明と仕様をプロンプトエンジニアリングすることについて説明します。これらは Agent のコンテキストに読み込まれるため、Agent を効果的な Tool 呼び出し動作に向けて導くことができます。
Tool の説明と仕様を書く際は、チームの新入社員に Tool を説明する方法を考えてください。暗黙的に持ち込む可能性のあるコンテキスト(特殊なクエリ形式、ニッチな用語の定義、基盤となるリソース間の関係)を考慮し、それを明示的にしてください。期待される入力と出力を明確に記述し(厳密なデータモデルで強制し)、曖昧さを避けてください。特に、入力パラメータは曖昧でない名前を付ける必要があります。user という名前のパラメータの代わりに、user_id という名前のパラメータを試してください。
評価により、プロンプトエンジニアリングの影響をより確信を持って測定できます。Tool の説明への小さな改良でも、劇的な改善をもたらすことができます。Claude Sonnet 3.5 は、Tool の説明に正確な改良を加えた後、SWE-bench Verified 評価で最先端のパフォーマンスを達成し、エラー率を劇的に削減し、タスク完了を改善しました。
Tool 定義のその他のベストプラクティスは、開発者ガイドで見つけることができます。Claude 用の Tool を構築している場合は、Tool が Claude のシステムプロンプトに動的に読み込まれる方法についても読むことをお勧めします。最後に、MCP サーバー用の Tool を書いている場合、Tool アノテーションは、どの Tool がオープンワールドアクセスを必要とするか、または破壊的な変更を行うかを開示するのに役立ちます。
今後の展望
Agent 用の効果的な tool を構築するために、私たちはソフトウェア開発の実践を、予測可能で決定論的なパターンから非決定論的なパターンへと方向転換する必要があります。
この投稿で説明した反復的で評価主導のプロセスを通じて、私たちは tool を成功させる要因の一貫したパターンを特定しました:効果的な tool は意図的かつ明確に定義され、Agent のコンテキストを適切に使用し、多様なワークフローで組み合わせることができ、Agent が直感的に現実世界のタスクを解決できるようにします。
将来的には、Agent が世界と相互作用する具体的なメカニズムが進化することが予想されます—MCP プロトコルの更新から、基盤となる LLM 自体のアップグレードまで。Agent 用の tool を改善するための体系的で評価主導のアプローチにより、Agent がより有能になるにつれて、彼らが使用する tool も一緒に進化することを確実にできます。
謝辞
Ken Aizawa が執筆し、Research(Barry Zhang、Zachary Witten、Daniel Jiang、Sami Al-Sheikh、Matt Bell、Maggie Vo)、MCP(Theo Chu、John Welsh、David Soria Parra、Adam Jones)、Product Engineering(Santiago Seira)、Marketing(Molly Vorwerck)、Design(Drew Roper)、Applied AI(Christian Ryan、Alexander Bricken)の同僚からの貴重な貢献を得ました。
1基盤となる LLM 自体の訓練を除く。

この Publication に投稿している記事は、アマゾン ウェブ サービス ジャパン合同会社または Amazon Web Services, Inc. 所属社員による個人の見解であり、所属する組織の公式見解ではありません。参加したい従業員の方は、Sugiyama Suguru までお知らせください。
Discussion