はじめに
こんにちは! AWS でソリューションアーキテクトをしている安藤です。
本ブログは AWS AI Agent ブログ祭り(Zenn: #awsaiagentblogfes, X: #AWS_AI_AGENT_ブログ祭り)の第 17 日目です。
皆さんは普段、スマホや PC などのデバイスを指・マウス・テキスト (キーボード) 以外で操作することはあるでしょうか?最近のテックブログ系の記事や、検索エンジンの結果を見る限り、特に生成 AI の登場以降、直感的、速い、といった理由で音声入力の注目度が上がっているようです。日頃からコーディングを行うエンジニアの中には、PC の音声認識機能で文字起こしを行い、Claude Code や Cline、Kiro などのコーディング AI エージェントに音声で指示を出すという使い方をしている人もいるようです。
そこで今回は 音声 と 生成 AI というキーワードに注目して、AWS の生成 AI サービス Amazon Bedrock で選択できる音声対話モデル Amazon Nova Sonic を使った マルチエージェント構成 を実際に試して解説してみることにしました。
この記事の主な対象読者
- 音声対話エージェントが気になる方
- 音声対話によるマルチエージェント構成に興味がある方
- Amazon Nova Sonic や、Amazon Nova Sonic と Amazon Bedrock AgentCore Runtime の連携が気になる方
ざっくり概要
- Amazon Nova Sonic と Amazon Bedrock AgentCore Runtime を組み合わせたマルチエージェント構成のサンプルを動かしてみました。
- 音声対話エージェントのマルチエージェント構成は、テキストベースのマルチエージェント構成とそれほど変わらず、比較的容易に実装できます。
- マルチエージェント構成は向き不向きもあります。今後の機能拡張や技術の発展にも期待です。
Amazon Nova Sonic 概説
Amazon Nova Sonic とは?
音声入力に対して、音声出力で返答させるシステムを作りたい場合、皆さんはどのように実装するでしょうか?従来であれば、これを実現するためには、[入力音声] → 音声認識 → 言語解釈, 返答テキスト生成 (最近では LLM を利用) → 音声合成 → [出力音声]といった一連の処理が必要でした。
この方式にも、各工程の技術が成熟しており、細かくチューニングできるという利点があります。しかしこれらの工程を全て経由する分、処理時間が長くなりレイテンシが発生します。音声対話形式が求められる多くの場合は即時性が求められるので、これは好ましいとは言えません。また、構成要素が増えるということは実装も煩雑化します。
このような課題を解決するのが Amazon Nova Sonic のような、リアルタイムに直接音声形式で入出力が可能な基盤モデルです。Amazon Nova Sonic は、AWS の生成 AI サービス Amazon Bedrock からサーバーレスで利用できる音声対話モデル (Speech-to-Speech model) です。音声の直接的な入出力が可能で、低レイテンシ、割り込み対応、Tool Use (Function Calling) 対応、といった特徴を備えています。
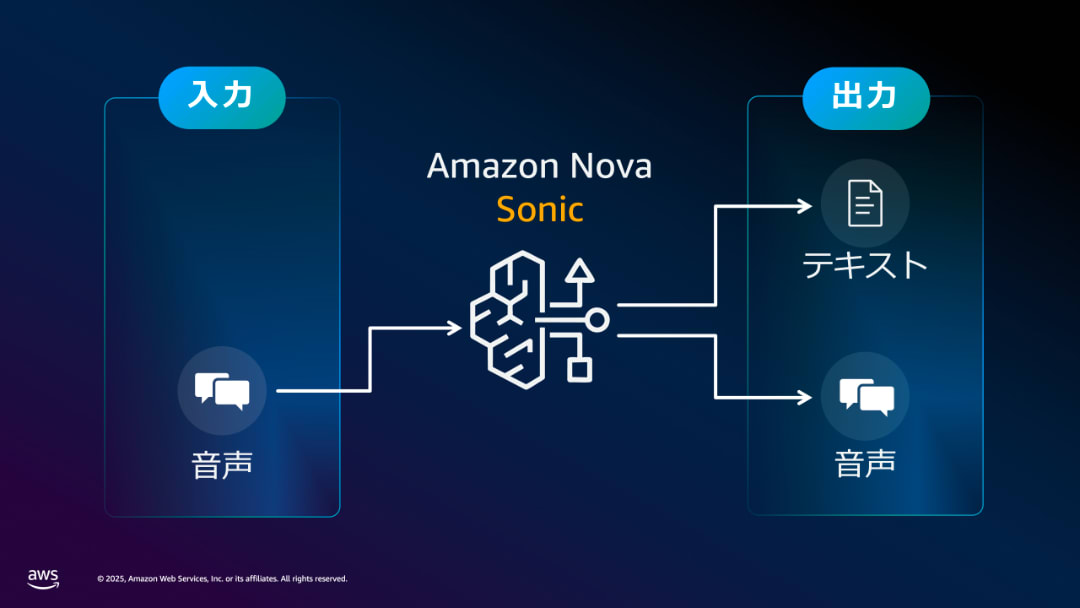
Amazon Nova Sonic が対応する入出力データ形式

Amazon Nova Sonic の主な特徴
活用場面の例としてはカスタマーサポート窓口での音声ボットや、英会話ボットなど、音声でのやり取りが役に立つ様々な場面が挙げられます。Amazon Nova Sonic が実際に動作する様子については、AWS の 公式プロダクトページ の動画をご覧ください 🎥
なお、Amazon Nova Sonic は東京リージョン(ap-northeast-1)の Amazon Bedrock でもご利用可能です。自社のサービスポリシーや規約の都合でエンドユーザーのデータを海外に持ち出せない日本のお客様も安心して使えますね!
Amazon Nova Sonic の仕組みと挙動
Amazon Nova Sonic は、Amazon Nova のマルチモーダルモデルや Anthropic Claude モデルなどと同様、Amazon Bedrock Runtime の API を用いて利用することができます。特に双方向ストリーミング API である InvokeModelWithBidirectionalStream API が用意されており、低レイテンシ・割り込み対応可といった特徴はこの仕組みに支えられています。
Amazon Nova Sonic の挙動を理解する上で重要なのは、この双方向ストリーミングでやり取りされる event です。双方向の音声チャンクやプロンプトの定義などは、全てこの event としてやり取りされます。例えば、以下のような要素が含まれます。
- システムプロンプト(Amazon Nova Sonic の挙動を定義)
- ToolUse 定義(今回のマルチエージェント構成の鍵)
- 過去の対話履歴
- ユーザー音声の書き起こし
- Amazon Nova Sonic の返答の書き起こし
- 外部ツール利用 (ToolUse) が判断された場合のレスポンス
- 双方向の音声チャンク
- 送受信するデータの開始や終了の目印
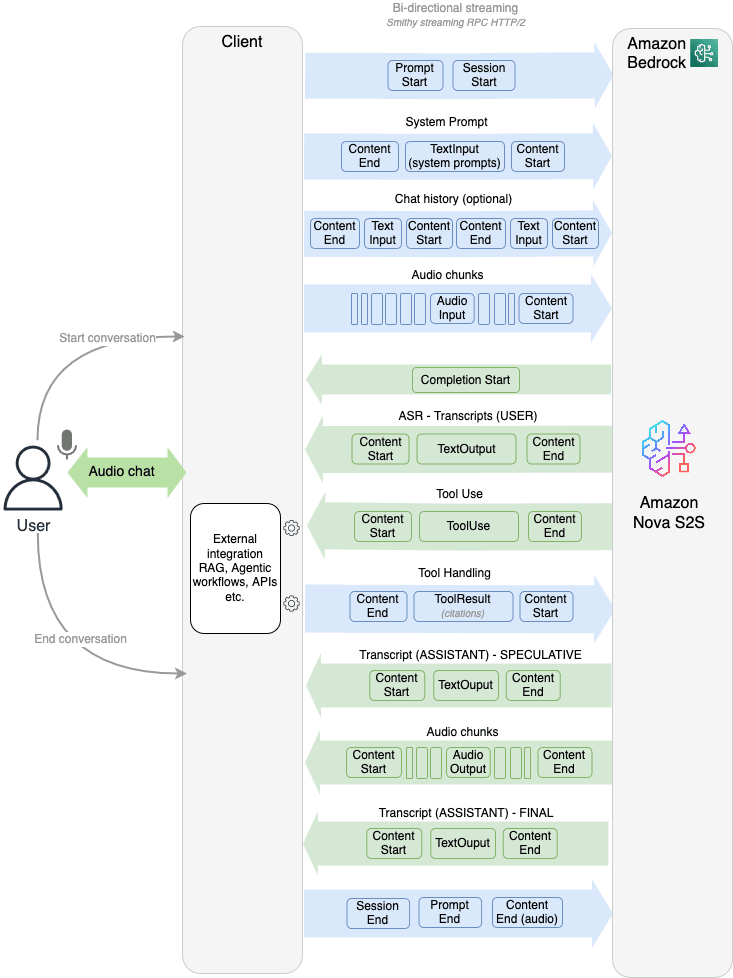
Amazon Nova Sonic の双方向ストリーミングのフロー
詳細な event の仕様については 公式ドキュメント をご確認ください。
今回の題材
今回の題材は Amazon Nova Sonic (speech-to-speech) Workshop の "Multi-Agent Architecture with AgentCore" セクションです。名前の通り、Amazon Nova Sonic に関する AWS の公式ワークショップです。特に今回は、本ワークショップのうち、Amazon Bedrock AgentCore Runtime も活用してマルチエージェント構成で 銀行の音声アシスタント として利用するサンプルを解説します。今回取り上げる部分を含めてコードは全て GitHub で公開されているので、ご興味がある方はぜひ自分の AWS アカウントで試してみてください。
Amazon Bedrock AgentCore Runtime については今回詳しく取り上げませんが、様々な公式ブログや執筆記事があります。本記事も参加している AWS AI Agent ブログ祭り の第 1 日目「Amazon Bedrock AgentCore が GA したので人間の実働 3 分で Runtime を動かす」もおすすめです 💪
今回のサンプルは何ができる?
今回のサンプルは、ユーザーからの銀行や抵当/ローンに関連する質問に答えることができる音声ボットです。まずはユーザーの氏名と ID を尋ねてから、ユーザーの要望に応えることが想定されています。今回は、ユーザー窓口となる Amazon Nova Sonic から呼び出せる 2 つのエージェントが用意されています。
- Banking サブエージェント: 口座残高の確認、明細書、その他の銀行関連の問い合わせを処理します。
- Mortgage (抵当/ローン) サブエージェント: 借り換え、金利、返済オプションなどの抵当/ローン関連の問い合わせを処理します。
これによって、例えば「私の残高を確認できますか?」という質問には Banking サブエージェントが、「住宅ローンの借り換えについて教えてください」という質問には Mortgage サブエージェントが対応します。このように、質問に応じて柔軟にサブエージェントを呼び出し、ユーザーに音声で応答する AI エージェントを構築できます。
どうやって実現している?
これを実現するための仕組みとして、まずはフロントエンドで Amazon Nova Sonic を呼び出し、必要に応じて Amazon Bedrock AgentCore Runtime で動く 2 つのサブエージェント Banking Agent と Mortgage Agent を呼び出せるようになっています。今回のエージェントは、いずれも中身はダミーです。
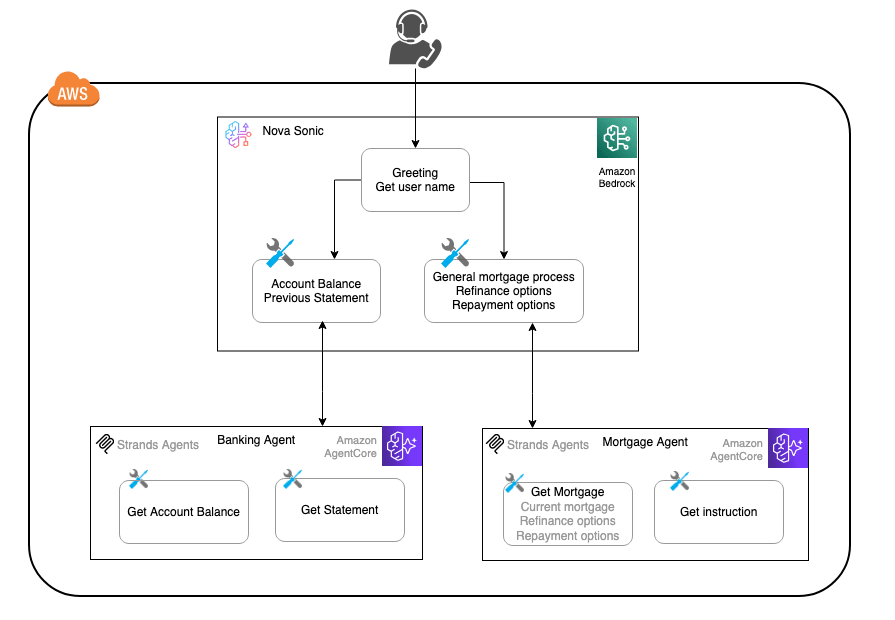
Amazon Nova Sonic と Amazon Bedrock AgentCore Runtime を組み合わせたマルチエージェント構成図
このワークショップでは、ローカル環境で動作する Python WebSocket サーバーと、Web ブラウザで音声対話ができる React UI が実装されています。
ワークショップの流れに沿って試してみた
まずはメインの部分を準備
早速、Workshop の GitHub リポジトリの Installation instruction に従ってリポジトリをクローンして、コードを動かしていきましょう。全て GitHub 記載の流れの通りだったので、トグル式にしておきます。
サンプル画面を動かすまでの実行コマンド
Python Websocket サーバー起動まで:
# リポジトリをクローン
git clone https://github.com/aws-samples/amazon-nova-samples
mv amazon-nova-samples/speech-to-speech/workshops nova-s2s-workshop
rm -rf amazon-nova-samples
cd nova-s2s-workshop
# Python websocket 環境準備
cd python-server
python3 -m venv .venv
# venv 環境の activate (Mac の場合)
source .venv/bin/activate
# Python dependencies のインストール
pip install -r requirements.txt
# AWS アクセスキーの設定
export AWS_ACCESS_KEY_ID="YOUR_AWS_ACCESS_KEY_ID"
export AWS_SECRET_ACCESS_KEY="YOUR_AWS_SECRET"
export AWS_DEFAULT_REGION="us-east-1"
# Python Websocket サーバー起動
python server.py
フロントエンド:
cd react-client
npm install
export REACT_APP_WEBSOCKET_URL='YOUR_WEB_SOCKET_URL'
npm start
ここまでの準備がうまくいくと、以下のような画面で Nova Sonic との会話を試すことができます!ローカル環境かつデフォルト設定では http://localhost:3000/proxy/3000 が WebUI のアクセス先になりました。
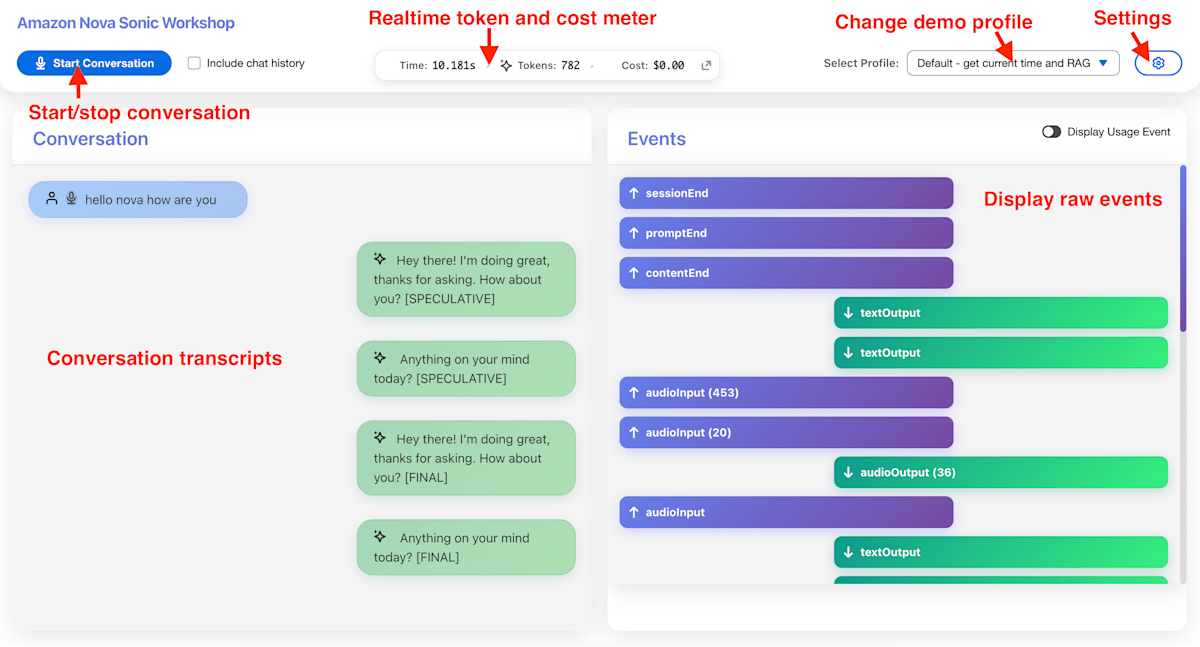
Workshop の Web UI
デモ用なので、ユーザーの発話と Nova Sonic の返答に加えて、内部的な event についても視覚的に確認できるようになっています。さらに、右上の ⚙ アイコンからシステムプロンプトの編集も可能です。
マルチエージェントを準備
これもリポジトリに記載の通りに実行します。
# nova-s2s-workshop ディレクトリで
cd agent-core
source ./deploy-agentcore-runtime.sh
このままではコマンドを実行するだけで記事が終わってしまうので、少し解説します。
deploy-agentcore-runtime.sh では、それぞれのサブエージェント用のディレクトリ内の deploy.py が呼び出されています。その deploy.py で利用されているのが bedrock_agentcore_starter_toolkit ライブラリです。例えば banking_agent/ では以下のような形です。
from bedrock_agentcore_starter_toolkit import Runtime
import boto3
# 省略
agent_name = "ac_bank_agent"
entrypoint = "./banking_agent.py"
# Prepare docker file
agentcore_runtime = Runtime()
response = agentcore_runtime.configure(
entrypoint=entrypoint,
auto_create_execution_role=True,
auto_create_ecr=True,
requirements_file="requirements.txt",
region=region,
agent_name=agent_name
)
source ./deploy-agentcore-runtime.sh が完了した段階で、AWS マネジメントコンソールの Amazon Bedrock AgentCore の Runtime 画面でも、2 つの Runtime が確認できます。
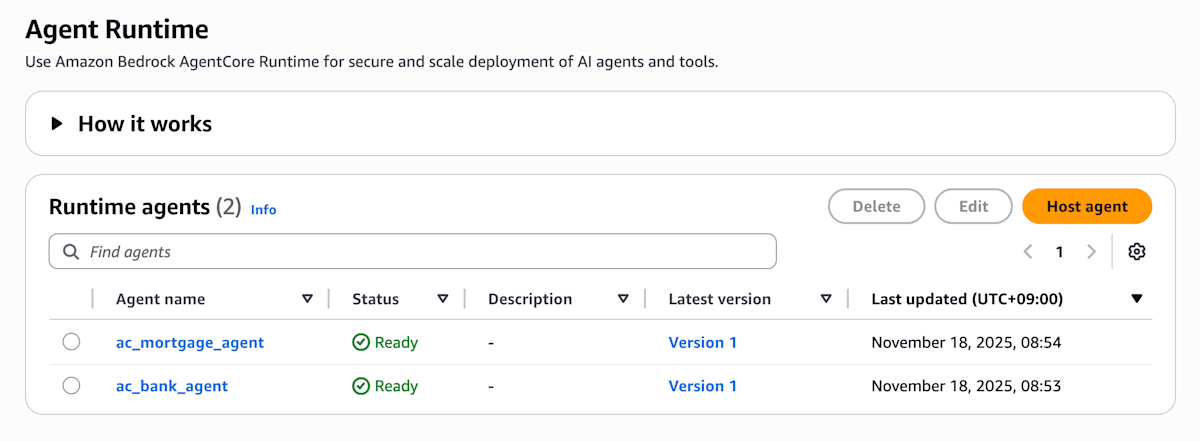
Amazon Bedrock AgentCore の Runtime 一覧画面
Nova Sonic + AgentCore Runtime のマルチエージェントを試してみた
実際にサブエージェントを含めた構成が正しく動作するか、試してみましょう。実装の都合上、一度 python-server/server.py を止めて再実行する必要があります。gif 動画なので雰囲気だけではありますが、実際に試してみた際の様子は以下の通りです。
実際に Amazon Nova Sonic とマルチエージェント構成を試す様子
エージェントの返答は完全にダミーデータですが、確かに自然な音声対話の流れで、必要に応じてサブエージェントから情報を取得させることができました 🎉
追加の補足・解説
仕組みをもう少しだけ詳しく解説
大まかな仕組みは構成図の通りなのですが、Amazon Nova Sonic と AgentCore Runtime の連携に焦点を当てて解説すると、以下の通りです。
- Amazon Nova Sonic のセッション開始時、ToolUse 設定を与える
- 今回は、ここで AgentCore Runtime で動くサブエージェントを呼び出せるツールを定義
- 対話内で
ToolUseevent が返答される (そしてその後contentEndevent で返答が完結する) - アプリケーション側でツール呼び出しを行う
- 今回は、ここで実際に AgentCore Runtime の InvokeAgentRuntime API を実行
- ToolResult としてリクエストストリームで
ToolUseの結果を返す。
双方向ストリーミングを利用しているなど細かい違いはありますが、基本的な構造はシンプルです。テキストベースのマルチエージェントシステムのエントリーポイント(スーパーバイザーエージェント、ルーティングエージェント)を、音声対話モデルに置き換えただけと考えることができます。ツールの呼び出し (ToolUse) が判断された後のサブエージェントでの処理はテキスト情報のやり取りになるので、それほど難しいことはしていません。そう考えると、音声対話モデルの導入のハードルが少し下がったような気がしますね!
なお今回のコードの仕組みについても簡単に解説しますが「実現方法は様々ある中で今回の実装ではこうやっている」というだけなので、トグルにしておきます。この分野が発展するにつれてベストプラクティスも増えていくかもしれません。より簡素な Amazon Nova Sonic のサンプルコードを見てみたい方は amazon-nova-samples/speech-to-speech/sample-codes がおすすめです。
今回のコードの概要
エンジン部分にあたるコード
今回の Nova Sonic 周りの中核となっているのは python-server/s2s_session_manager.py です。コード自体は細かく書いてありますが、実施内容は単純で、特に S2sSessionManager クラスの _process_responses メソッドで Nova Sonic のレスポンスのチャンクの event に応じて処理を行っています。
ツールを呼び出す際は、ac_ から始まるツール名だった場合には、AgentCore Runtime を呼び出す必要があるツールだと判断され、python-server/integration/agent_core.py に記述されている invoke_agent_core 関数が呼び出されます。
# ...
class S2sSessionManager:
# ...
async def processToolUse(self, toolName, toolUseContent):
"""Return the tool result"""
toolName = toolName.lower()
# AgentCore integration
if toolName.startswith("ac_"):
result = agent_core.invoke_agent_core(toolName, content)
# ...
invoke_agent_core 関数の中で呼び出されるのが Amazon Bedrock AgentCore Runtime の InvokeAgentRuntime API です。この API のリクエストパラメーターには agentRuntimeArn が必要です。今回は以下の流れで実装されています。
- 一度現在のリージョンの全ての AgentCore Runtime の名前と ARN を一覧化し、対応表 (辞書) を作成しておく
- 1 の対応辞書と、呼び出されたツール名から、ARN を得る
- その ARN をパラメーターとして InvokeAgentRuntime API を実行
# ...
boto3_response = agentcore_client.invoke_agent_runtime(
agentRuntimeArn=arn,
qualifier="DEFAULT",
payload=json.dumps(payload)
)
つまり、ここでは、AgentCore Runtime で作成した Runtime の名前と、Amazon Nova Sonic から呼び出されるツールの名前が一致している前提です。
どうやってサブエージェント定義を Nova Sonic に教えているか?
そうなると、あとはどうやって Nova Sonic のセッションを開始する際に 2 つのサブエージェントに関する定義を (ac_ 接頭辞付きで) 与えているか、が気になるところです。これに関しては react-client/src/helper/config.js に、全てのデモプロファイルのシステムプロンプトやツール定義が記述されています。
const DemoProfiles = [
// 省略
{
"name": "Customer Service - Finance",
"description": "A sample voice assistant for customer service, built with a multi-agent architecture.",
"voiceId": "tiffany",
"systemPrompt": "...",
"toolConfig": {
// ツール定義
}
}
]
音声対話モデル活用の考慮点
ここまで、Amazon Nova Sonic と AgentCore Runtime を組み合わせたマルチエージェント構成の実装を見てきました。音声対話モデルを使えば比較的簡単に、音声を活用した AI エージェントを実装できます。
一方で、今回のようなマルチエージェント構成が常に最適とは限りません。例えば今回のような問い合わせ窓口であれば、人間のオペレータが対応している時も情報収集などにタイムラグは発生するので、利用者は大きな違和感は生じにくそうです。一方で、英会話用アプリケーションを作りたいという場合は、返答の即時性がより重視されるので、サブエージェントで数秒レイテンシを伸ばすよりも、必要なツールだけを Nova Sonic に与えた単純な構成としたり、別途入出力の書き起こしを同時並行で別の LLM などで処理した方が最適かもしれません。
以下は、ワークショップ解説ページに記載されているベストプラクティスの和訳です:
- 柔軟性とレイテンシのバランス: (Nova Sonic の ToolUse event を介して、) サブエージェントを呼び出す処理は、音声応答にレイテンシが追加される可能性があります。
- サブエージェントには小さな LLM を使用: Nova Lite のようなモデルから始めることで、レイテンシを削減できます。
- 応答の長さを最適化: 音声アシスタントは、フォローアップを伴う短い応答の方が向いています。これによって、レイテンシとユーザー体験の両方が向上します。
- ステートレス vs ステートフルなサブエージェント設計:
- ステートレスサブエージェント: 以前のやり取りの記憶なしに、各リクエストを独立して処理します。シンプルで拡張が容易ですが、コンテキストを考慮した応答を提供できません。
- ステートフルサブエージェント: やり取り間で記憶を維持し、コンテキストを考慮した応答を可能にします。パーソナライズされた体験をサポートしますが、より複雑でリソース集約的です。
- 使い分けの指針:
- シンプルなタスクにはステートレスサブエージェントを、複数ターンやコンテキスト依存のワークフローにはステートフルなものを使用してください。
- 用途に特化したタスクをサブエージェントに委任しながら、Nova Sonic オーケストレーターにセッションレベルの状態を管理させてください。
まとめ
今回は、AWS 公式ワークショップを題材として、音声対話モデル Amazon Nova Sonic をマルチエージェント構成で動かしてみました。ユーザー接点となる AI エージェントを音声対話モデルに置き換えたマルチエージェント構成でしたが、実際の連携方法はテキストベースのマルチエージェント構成とほぼ同じであることをご理解いただけたかと思います。今回の記事が、皆様の AI 活用における新しいアイデアの一助となれば幸いです!

この Publication に投稿している記事は、アマゾン ウェブ サービス ジャパン合同会社または Amazon Web Services, Inc. 所属社員による個人の見解であり、所属する組織の公式見解ではありません。参加したい従業員の方は、Sugiyama Suguru までお知らせください。
Discussion