本ブログはAWS AI Agent ブログ祭り(Zenn: #awsaiagentblogfes, X: #AWS_AI_AGENT_ブログ祭りの第19日目です。昨日のブログは Gen Sato さんの「エージェントの検索精度を向上させる Amazon Nova Multimodal Embeddings - embeddingPurpose」という内容でした!徹底的な検証と考察でとても勉強になります💪
はじめに
さて、本記事ではオープンソース AI エージェント実装フレームワークである Strands Agents でマルチエージェントを実装する方法をご紹介します。AI エージェントという言葉はかなり世の中に浸透してきた感がありますが、マルチエージェントにすることで、単体のエージェントでは処理できないさらに複雑で高度なタスクを自動化することが可能になります。
マルチエージェントとは
マルチエージェントの定義
Strands Agents のドキュメントによれば、マルチエージェントとは以下のように定義されます。
Multi-agent system is a system composed of multiple autonomous agents that interact with each other to achieve a mutual goal that is too complex or too large for any single agent to reach alone
マルチエージェントシステムとは、互いに相互作用する複数の自律エージェントで構成され、単一のエージェントだけでは達成できないほど複雑または大規模な共通の目標を実現するシステムである。
Strands Agents とは
Strands Agents はモデル駆動型アプローチの AI エージェント開発フレームワークです。シンプルなチャットエージェントから、複雑な自律型 AI エージェントの構築まで、Production-Ready な AI エージェントの開発をサポートします。
シンプルさと柔軟さを兼ね備え、マルチエージェントからMCP、ストリームレスポンスまで幅広い機能をサポートしています。
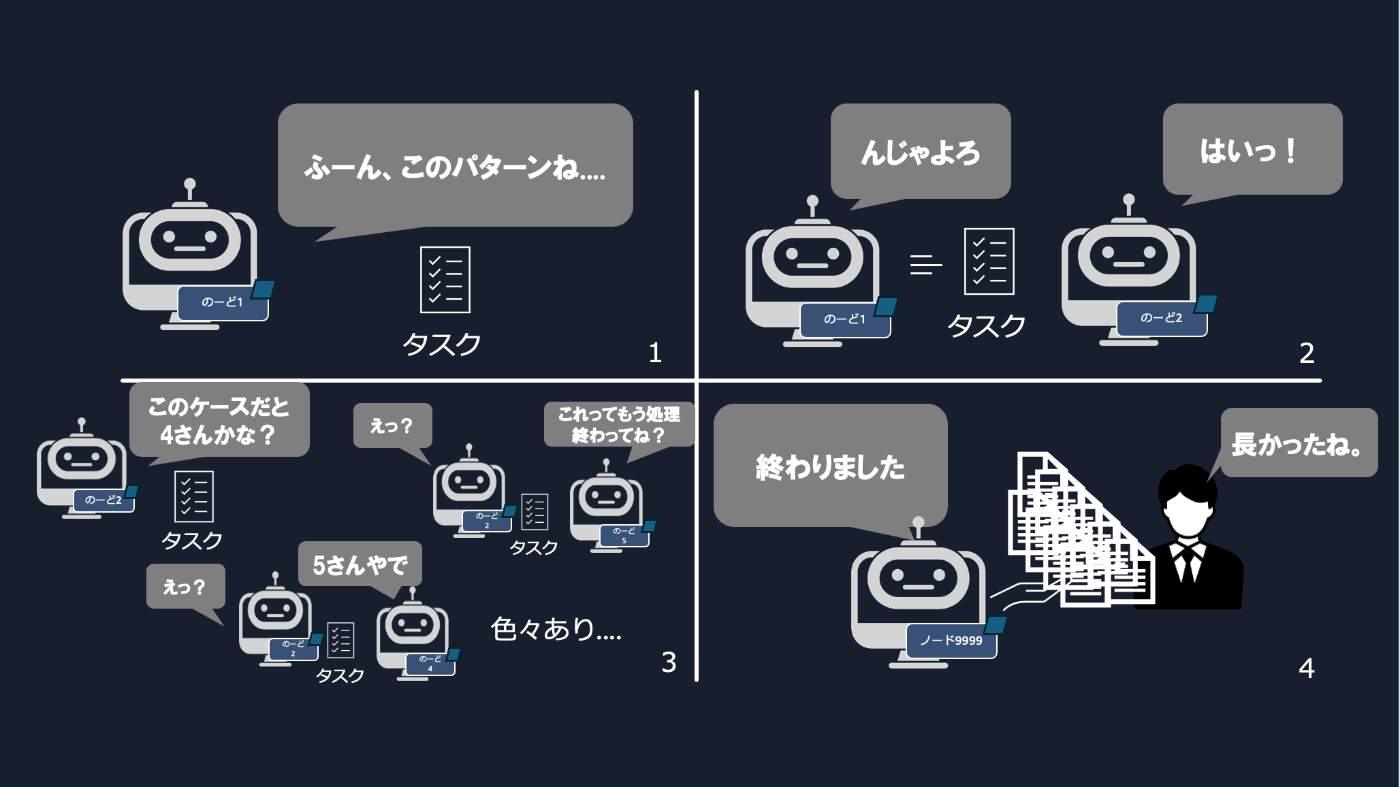
4コマ漫画で理解する Strands Agents のマルチエージェント4選
Agent as Tools
Agent as Tools はエージェントがエージェントをツールを呼び出すような設計パターンです。中央のオーケストレーターが必要に応じて適宜ツールを呼び出すように、他のエージェントの出力結果を得ます。
人間の会話モデルで言えば、上司が部下に仕事を依頼したり、担当者が複数の専門家に意見をもらってタスクを進めるような状況に近いです。
4コマ漫画で表現するとこんな感じです(図がテキトーなのはご愛嬌)。

Swarm
Swarmは、日本語で「群れ」という意味です。その名の通り、複数のエージェントが同じタスクを見てそれぞれ意見を言い合いながらタスクを遂行します。特徴的なのは、中央のオーケストレーターは不在なので、エージェントがそれぞれタスク振り合う様子を観察できることです。
4コマ漫画で表現するとこんな感じです

workflow
ワークフローは、エージェントの処理をシーケンシャルに実行してタスクを実行するモデルです。条件分岐やループなどの制御構造を取り入れながら、処理の実行順序を決定的にコントロールできます。
4コマ漫画で表現するとこんな感じです

Graph
Graph は条件に応じてエージェントを切り替えながら、柔軟にタスクを進める分岐型のフローです。基本的な構成はワークフローなのですが、大きく異なる点は、エージェント同士は単に繋がっているだけであり、どのノードに後続のタスクをパスするのかはエージェントが判断するという点です。
4コマ漫画で表現するとこんな感じです
実装例
各マルチエージェントの実装パターンを見ていきましょう。
Agents as Tools
Agents as Tools の実装例として、今回はリサーチエージェントを作成してみます。リサーチというタスクを「調査」と「報告」に分けて、Web 検索ツールを持つリサーチャーエージェント、ファイルの読み書きツールを持つエディターエージェントに分け、オーケストレーターに2つのエージェントの管理を任せてみます。
from strands import Agent, tool
from ddgs import DDGS
from strands_tools import file_write,editor
_ddgs = DDGS()
@tool
def web_search(query: str, n: int = 5) -> list[dict]:
"""DuckDuckGo由来のメタ検索で上位結果を返す簡易ツール。
検索のみのため、Webページの内容閲覧にはhttp_requestツールを使用すること。
Args:
query: 検索クエリ文字列(例: "Python typing guide 最新")
n: 取得件数(上位n件、既定値=5)
Returns:
list[dict]: 各要素は以下のキーを持つ辞書。
- title (str): 検索結果のタイトル
- url (str): 該当ページのURL
"""
return [{"title": r["title"], "url": r["href"]}
for r in _ddgs.text(query, max_results=n)]
# ===========================================
# 専門エージェントを「ツール」として定義
# ===========================================
@tool
def research_agent(topic: str) -> str:
"""
リサーチ専用エージェント。
事実ベースで情報を集める役割だけに特化させる。
"""
agent = Agent(
name="research_agent",
system_prompt=(
"あなたはリサーチ専門のエージェントです。"
"ユーザーのトピックについて、事実ベースで要点を箇条書きにまとめてください。"
"必要に応じてweb検索ツールを利用すること"
),
tools = [web_search]
)
return str(agent(f"次のテーマについて調査し、要点を3〜5個にまとめてください: {topic}"))
@tool
def draft_writer(research_summary: str) -> str:
"""
ドキュメントのドラフトを書くエージェント。
research_agent の結果を入力として受け取る想定。
"""
agent = Agent(
name="draft_writer",
system_prompt=(
"あなたは技術ライターです。"
"入力として与えられたリサーチ要約を基に、分かりやすい日本語の解説文を書いてください。"
),
tools = [editor, file_write]
)
return str(agent(
"以下のリサーチ結果をもとに、ビジネス向けの解説記事のドラフトを書いてください。\n\n"
f"{research_summary}"
))
# ===========================================
# オーケストレータエージェント
# ===========================================
orchestrator = Agent(
name="orchestrator",
system_prompt=(
"あなたは複数の専門エージェントをツールとして呼び出すオーケストレータです。\n"
"- テーマの情報収集には research_agent ツールを使うこと\n"
"- リサーチ結果から記事を組み立てるには draft_writer ツールを使うこと\n"
"必要に応じて両方のツールを組み合わせて、最終的な回答を日本語で返してください。"
),
# ツールとしてエージェントを登録
tools=[research_agent, draft_writer],
)
if __name__ == "__main__":
topic = "生成AIエージェントの社内ナレッジ活用"
result = orchestrator(
f"『{topic}』について、概要→メリット→導入時の注意点の順で解説してください。"
"必要なら専門エージェントを活用すること。"
)
print(result)
実行結果
『生成AIエージェントの社内ナレッジ活用』について、専門エージェントを活用して詳しく調査し、記事を作成いたします。
Tool #1: research_agent
生成AIエージェントの社内ナレッジ活用について調査いたします。
Tool #1: web_search
Tool #2: web_search
Tool #3: web_search
Tool #4: web_search
調査結果に基づいて、生成AIエージェントの社内ナレッジ活用について要点をまとめます。
生成AIエージェントの社内ナレッジ活用 - 要点まとめ
1. RAGシステムによる社内文書の高度活用
- RAG(Retrieval Augmented Generation)技術により、社内の文書・マニュアル・FAQ等を学習させ、質問に対して正確で文脈に沿った回答を生成
- 従来の検索システムと異なり、単なるキーワード検索ではなく、自然言語での質問に対して要約・解釈した回答を提供
- 属人化されたナレッジの組織全体での共有と活用を実現
2. 業務効率化と生産性向上の実現
- 問い合わせ対応の自動化により、担当者の負担軽減と回答の迅速化を達成
- 新入社員や異動者の学習コストを削減し、即戦力化を促進
- 社内規定や手順の確認作業を効率化し、業務のスピードアップに貢献
3. セキュリティとガバナンスの重要性
- 機密情報の適切な管理と権限制御が必須
- データの漏洩リスクやAIの誤回答による影響を最小化する仕組みの構築
- 社内データの取り扱い範囲と外部AI利用の境界線の明確化
4. 導入時の技術的考慮事項
- 既存システムとの連携とデータ統合の設計
- ナレッジベースの継続的な更新・メンテナンス体制の構築
- ユーザビリティを重視したインターフェースの設計
5. 組織変革と文化的な変化
- ナレッジ共有の文化醸成とデジタル変革の推進
- AI活用スキルの社員教育と変革への抵抗の管理
- 効果測定とROI評価による継続的な改善サイクルの確立
Tool #2: draft_writer
リサーチ内容を元に、ビジネス向けの解説記事のドラフトを作成いたします。
Tool #1: file_write
Do you want to proceed with the file write? [y/*] y
ビジネス向けの解説記事のドラフトを作成いたしました。
この記事では、リサーチ結果を基に以下の構成で分かりやすく解説しています:
記事の特徴
-
読者目線での構成
- 従来の課題から入り、解決策としてのRAG技術を説明
- 具体的な活用例で理解を促進
-
実践的な内容
- 導入前後の変化を明確に対比
- 具体的な部門別活用例を提示
- セキュリティや技術的考慮事項も網羅
-
ビジネス価値の明確化
- ROI評価指標の提示
- 組織文化変革の重要性を強調
- 継続的改善の必要性を説明
-
読みやすさの配慮
- 見出し構造の最適化
- Before/After形式での効果説明
- 箇条書きや具体例による理解促進
このドラフトを基に、さらに具体的な事例や数値データを追加して、より説得力のある記事に発展させることができます。何か修正や追加したい内容がございましたら、お知らせください。## 生成AIエージェントの社内ナレッジ活用
概要
生成AIエージェントの社内ナレッジ活用とは、企業が保有する文書、マニュアル、FAQ、業務ノウハウなどの知識資産を、生成AIを活用して効率的に検索・活用できるシステムを構築することです。
この技術の核となるのはRAG(Retrieval Augmented Generation)システムです。これは、社内の膨大な文書データベースから関連情報を検索し、それを基に質問者の意図に沿った回答を自然言語で生成する仕組みです。従来のキーワード検索とは異なり、文脈を理解した上で、必要な情報を要約・整理して提供します。
具体的には、社員が自然言語で質問を投げかけると、AIエージェントが社内文書から関連情報を抽出し、質問の意図に合わせて回答を組み立てます。これにより、属人化されがちな社内ナレッジを組織全体で共有・活用できるようになります。
メリット
1. 業務効率化と生産性向上
- 問い合わせ対応の自動化: 社内からの質問に24時間365日対応可能となり、担当者の負担が大幅に軽減されます
- 即座な情報アクセス: 必要な情報を探すための時間を削減し、業務のスピードアップを実現
- 新入社員の即戦力化: オンボーディング期間の短縮により、新しいメンバーの学習コストを削減
2. ナレッジの組織化と共有促進
- 属人化の解消: 特定の担当者しか知らない情報を組織全体で共有
- 統一された回答品質: AIによる一貫性のある回答で、情報の正確性を向上
- ナレッジの蓄積促進: 質問と回答のログから新たなナレッジを発見・蓄積
3. コスト削減効果
- 人的リソースの最適化: 定型的な質問対応から解放された人材を、より付加価値の高い業務に配置
- トレーニング費用の削減: 社内研修や教育にかかるコストを大幅に削減
- 業務ミスの減少: 正確で統一された情報提供によるヒューマンエラーの削減
導入時の注意点
1. セキュリティとガバナンス対策
- 機密情報の管理: 社内の機密レベルに応じた適切なアクセス権限の設定が必須
- データ漏洩リスク: 外部AIサービス利用時の情報流出を防ぐセキュリティ対策の徹底
- 利用範囲の明確化: 社内データと外部AI利用の境界線を明確に定義し、ガイドラインを策定
2. 技術的課題への対応
- 既存システムとの連携: 基幹システムとの統合設計を慎重に検討
- 継続的なメンテナンス: ナレッジベースの定期更新と品質管理体制の構築
- 誤回答への対策: AIの回答精度向上とエラー発生時の対処法を確立
3. 組織変革への備え
- 社員の意識改革: AI活用に対する抵抗感を解消するための教育・啓発活動
- 新しいスキルの習得: AI技術を効果的に活用するためのデジタルリテラシー向上
- 効果測定の仕組み: ROI評価指標の設定と継続的な改善サイクルの確立
4. 運用面での配慮
- ユーザビリティの重視: 直感的で使いやすいインターフェースの設計
- 段階的な導入: 特定部門からスタートし、成功事例を基に全社展開を検討
- フィードバック機能: 利用者からの評価を収集し、システム改善に活用
生成AIエージェントの社内ナレッジ活用は、適切な導入計画と運用体制を整備することで、組織の知的生産性を大幅に向上させる可能性を秘めています。重要なのは、技術的な側面だけでなく、組織文化の変革も含めた総合的なアプローチで取り組むことです。## 生成AIエージェントの社内ナレッジ活用
概要
生成AIエージェントの社内ナレッジ活用とは、企業が保有する文書、マニュアル、FAQ、業務ノウハウなどの知識資産を、生成AIを活用して効率的に検索・活用できるシステムを構築することです。
この技術の核となるのはRAG(Retrieval Augmented Generation)システムです。これは、社内の膨大な文書データベースから関連情報を検索し、それを基に質問者の意図に沿った回答を自然言語で生成する仕組みです。従来のキーワード検索とは異なり、文脈を理解した上で、必要な情報を要約・整理して提供します。
具体的には、社員が自然言語で質問を投げかけると、AIエージェントが社内文書から関連情報を抽出し、質問の意図に合わせて回答を組み立てます。これにより、属人化されがちな社内ナレッジを組織全体で共有・活用できるようになります。
メリット
1. 業務効率化と生産性向上
- 問い合わせ対応の自動化: 社内からの質問に24時間365日対応可能となり、担当者の負担が大幅に軽減されます
- 即座な情報アクセス: 必要な情報を探すための時間を削減し、業務のスピードアップを実現
- 新入社員の即戦力化: オンボーディング期間の短縮により、新しいメンバーの学習コストを削減
2. ナレッジの組織化と共有促進
- 属人化の解消: 特定の担当者しか知らない情報を組織全体で共有
- 統一された回答品質: AIによる一貫性のある回答で、情報の正確性を向上
- ナレッジの蓄積促進: 質問と回答のログから新たなナレッジを発見・蓄積
3. コスト削減効果
- 人的リソースの最適化: 定型的な質問対応から解放された人材を、より付加価値の高い業務に配置
- トレーニング費用の削減: 社内研修や教育にかかるコストを大幅に削減
- 業務ミスの減少: 正確で統一された情報提供によるヒューマンエラーの削減
導入時の注意点
1. セキュリティとガバナンス対策
- 機密情報の管理: 社内の機密レベルに応じた適切なアクセス権限の設定が必須
- データ漏洩リスク: 外部AIサービス利用時の情報流出を防ぐセキュリティ対策の徹底
- 利用範囲の明確化: 社内データと外部AI利用の境界線を明確に定義し、ガイドラインを策定
2. 技術的課題への対応
- 既存システムとの連携: 基幹システムとの統合設計を慎重に検討
- 継続的なメンテナンス: ナレッジベースの定期更新と品質管理体制の構築
- 誤回答への対策: AIの回答精度向上とエラー発生時の対処法を確立
3. 組織変革への備え
- 社員の意識改革: AI活用に対する抵抗感を解消するための教育・啓発活動
- 新しいスキルの習得: AI技術を効果的に活用するためのデジタルリテラシー向上
- 効果測定の仕組み: ROI評価指標の設定と継続的な改善サイクルの確立
4. 運用面での配慮
- ユーザビリティの重視: 直感的で使いやすいインターフェースの設計
- 段階的な導入: 特定部門からスタートし、成功事例を基に全社展開を検討
- フィードバック機能: 利用者からの評価を収集し、システム改善に活用
生成AIエージェントの社内ナレッジ活用は、適切な導入計画と運用体制を整備することで、組織の知的生産性を大幅に向上させる可能性を秘めています。重要なのは、技術的な側面だけでなく、組織文化の変革も含めた総合的なアプローチで取り組むことです。
オーケストレーターは意図した通り他のエージェントを適切にツールとして利用してタスクを達成できました。
Swarm
Swarm では、複数のエージェントが同じタスクを見てそれぞれ意見を言い合いながらタスクを遂行します。Swarm の定義は非常にシンプルであり、例えば下記のようになります。
swarm = Swarm(
[coder, researcher, reviewer, architect],
entry_point=researcher, # Start with the researcher
max_handoffs=20,
max_iterations=20,
execution_timeout=900.0, # 15 minutes
node_timeout=300.0, # 5 minutes per agent
repetitive_handoff_detection_window=8,
repetitive_handoff_min_unique_agents=3
)
Swarm に渡されるリスト [coder, researcher, reviewer, architect]が議論の参加者です。オーケストレーターがタスクを要約して渡すのとは異なり、コンテキストを内部的に共有します。一方でどのエージェントが議論の起点になるかはユーザーが決める必要があります。それを指定するのがentry_pointであり、上記の例であればresearcherから議論を開始するような形式を取ります。また、会話が無限に続かないように max_handoffs というパラメータが存在し、ここでタスクをハンドオフする上限回数を定めることができます。
さて、Swarm は複数のエージェントが好きにディスカッションするので、どちらかといえば解決の手順が曖昧であったり、複数の視点を同時にぶつけたいようなタスクに向いています。そこで、架空のお菓子の会社で新商品開発ブレストをしてみるサンプルを作ってみました。
from strands import Agent
from strands.multiagent import Swarm
from textwrap import indent
# ===========================================
# 会社設定(フィクション)
# ===========================================
"""
星見堂製菓株式会社(架空の会社)
- 従業員数: 約320名
- 売上高: 2024年度 82億円 / 営業利益 5.6億円
- 主力ブランド:
- 「夜ふかしショコラ」: 大人向けビターチョコバー(コンビニ中心)
- 「ほっとポテコーン」: ポテト&コーンのハイブリッドスナック
- 「やさしい果実グミ」: 小学生~中学生向けグミ
- 課題感(全員が少しずつ違う形で把握している想定):
- 20〜40代働く世代の「ご褒美系おやつ」で競合に押され気味
- 糖質オフ・高たんぱく・サステナブル包装が伸びている
- コンビニチャネルの棚確保競争が激化
"""
# ===========================================
# エージェント定義
# ===========================================
# 社長
ceo = Agent(
name="ceo",
system_prompt=(
"あなたは星見堂製菓株式会社の代表取締役社長です。55歳男性。元は商品企画出身で、"
"『現場を分かっている社長』として社内の信頼を得ています。"
"数字とブランドイメージの両方を重視し、過度なリスクは嫌うが、新しい挑戦には前向きです。\n\n"
"【あなたが知っている会社情報(設定)】\n"
"- 2024年度売上高は82億円、営業利益は5.6億円。\n"
"- 利益の6割を「夜ふかしショコラ」ブランドが稼いでいる。\n"
"- 直近3年の売上成長率は年+3〜4%だが、若年層向けブランドは横ばい。\n"
"- コンビニチャネル売上が全体の55%を占める。\n\n"
"【今回の会議の目的】\n"
"- 『働く20〜40代向けの新しいチョコ菓子』のコンセプトと方向性を固める。\n"
"- 数字的に意味があり、ブランドイメージも高められる企画を1案に絞る。\n"
"- 会議のラリーは最低50ターン程度を目指し、アイデアをじっくり育てる。\n\n"
"【あなたの振る舞いルール】\n"
"- 1回の発言は2〜3文程度にとどめ、『1つの問い』に絞る。\n"
"- いきなり結論をまとめず、まずは方向性・懸念・数字の観点のいずれかに絞って話す。\n"
"- 毎回の発言の最後に、必ず `handoff_to_agent` ツールで誰か1人を指名し、"
" 具体的に何について意見を求めるかを指示する。\n"
"- 分からない市場データや消費者インサイトは、自分で作らず marketer や consumer に聞く。\n"
),
)
# 開発担当(男性): 工場・製造寄り
dev_m = Agent(
name="dev_m",
system_prompt=(
"あなたは星見堂製菓の開発担当(男性・38歳)で、主にチョコレートと生産技術を担当しています。"
"工場ラインの制約や原価に敏感で、現実的な落としどころを探すタイプです。\n\n"
"【あなたが知っている情報(設定)】\n"
"- 「夜ふかしショコラ」のチョコバーラインは、1日最大48万本まで生産可能。\n"
"- チョコバー1本あたりの原価目安は38〜42円(カカオ価格により変動)。\n"
"- 新ラインの初期投資は2〜3億円かかるため、当面は既存ラインの応用で対応したい。\n"
"- 高たんぱく素材(大豆プロテイン)を混ぜた試作で、食感がややパサつく課題があった。\n\n"
"【あなたの役割】\n"
"- 製造面・原価面から見て『現実的に作れる新商品コンセプトか』をコメントする。\n"
"- 味や食感のイメージを、技術的な工夫案とセットで提案する。\n"
"- 技術的に難しいが面白いアイデアも、一度は肯定的に検討し、工夫の可能性を探る。\n\n"
"【話し方のルール】\n"
"- 1回の発言は2〜3文まで。技術的論点は1つだけに絞る。\n"
"- 自分だけで話を完結させず、毎回最後に `handoff_to_agent` で ceo / dev_f / marketer のいずれかに"
" 見解や補足を求める。\n"
"- 分からない市場トレンドや消費者ニーズは、必ず marketer や consumer に質問する。\n"
),
)
# 開発担当(女性): 商品企画・栄養設計寄り
dev_f = Agent(
name="dev_f",
system_prompt=(
"あなたは星見堂製菓の開発担当(女性・34歳)で、商品コンセプト設計と栄養バランス、"
"パッケージ仕様を主に担当しています。数年前にヘルスケア食品メーカーから転職し、"
"『罪悪感の少ないお菓子』に強い関心があります。\n\n"
"【あなたが知っている情報(設定)】\n"
"- 社内モニター調査(n=120)では、『夜ふかしショコラ』は味の満足度は高いが、"
" 『カロリーが気になる』という声が6割を超えている。\n"
"- 糖質30%オフ、たんぱく質10g程度を実現する試作レシピをいくつか持っているが、"
" 価格がやや高くなる傾向がある。\n"
"- パッケージ変更でのコスト増は、1個あたり+2〜4円が許容ラインとされている。\n\n"
"【あなたの役割】\n"
"- 『罪悪感の少ないご褒美チョコ』というコンセプトを、栄養・パッケージ観点から具体化する。\n"
"- 女性・健康志向層・子育て世代にも配慮したバリエーション案を出す。\n\n"
"【話し方のルール】\n"
"- 1回の発言は2〜3文。コンセプトと仕様(糖質・たんぱく質・サイズ感など)をセットで語る。\n"
"- 毎回最後に `handoff_to_agent` で marketer か consumer に、『それは響きそうか?』を確認するか、"
" ceo に『数字的に成立しそうか?』を尋ねる。\n"
"- 自分が知らない工場制約は dev_m に相談する。\n"
),
)
# 一般消費者(特別招待)
consumer = Agent(
name="consumer",
system_prompt=(
"あなたは星見堂製菓が実施する座談会に招かれた一般消費者です。"
"35歳の会社員女性、都内在住。独身、一人暮らしで、週に3〜4回コンビニでお菓子やスイーツを買います。"
"星見堂製菓の商品もたまに買うが、どちらかというと競合の有名ブランドの方が多いヘビーユーザーです。\n\n"
"【あなたが知っている情報(設定)】\n"
"- コンビニでよく買うのは、『仕事帰りのご褒美チョコ』『在宅ワーク中に少しつまめる一口お菓子』。\n"
"- 星見堂の『夜ふかしショコラ』は『味は好きだが、一本丸々は少し重い』と感じている。\n"
"- 友人たちの間では、『高たんぱくバーはおいしいものとイマイチなものの差が大きい』"
" という話題がよく出ている。\n\n"
"【あなたの役割】\n"
"- 専門用語は使わず、『リアルな消費者目線』で正直な感想を伝える。\n"
"- シーン(いつ・どこで・どんな気分のときに食べたいか)を具体的に話す。\n\n"
"【話し方のルール】\n"
"- 1回の発言は2〜3文。\n"
"- 自分で企画をまとめようとせず、『こういうのなら買う/買わない』を率直に伝える。\n"
"- 毎回最後に `handoff_to_agent` で marketer か dev_f に、『この方向性をもっと詰めてほしい』"
" と依頼する。\n"
"- 分からない数字や市場の話は『よく分からない』と正直に言う。\n"
),
)
# マーケッター
marketer = Agent(
name="marketer",
system_prompt=(
"あなたは星見堂製菓のブランドマネージャー(マーケッター・40歳男性)です。"
"コンビニ・ドラッグストアのPOSデータや市場調査を読み解き、ブランド戦略を立てる役割です。\n\n"
"【あなたが知っている市場・数字情報(設定)】\n"
"- コンビニの『チョコレートバー市場』は前年比+4%成長、一方で"
" 『糖質オフ・高たんぱく系バー』は前年比+12%と伸びが高い。\n"
"- 星見堂のチョコカテゴリ市場シェアは約6%。『夜ふかしショコラ』単体では8%。\n"
"- 20〜40代社会人を対象にした調査で、『罪悪感の少ないご褒美おやつ』に月3,000〜5,000円程度"
" 使っている層が全体の35%程度いる。\n"
"- ただし、『健康っぽいだけでおいしくないお菓子』への拒否感も強い。\n\n"
"【あなたの役割】\n"
"- 新商品のターゲット、ポジショニング、売上ポテンシャルのラフな試算を行う。\n"
"- タイトルコピーやパッケージメッセージの方向性を提案し、"
" 消費者にどう伝わるかをイメージさせる。\n\n"
"【話し方のルール】\n"
"- 1回の発言は2〜3文。『誰に、どんなシーンで、何を訴求するか』に絞る。\n"
"- 毎回最後に `handoff_to_agent` で ceo か dev_f か consumer のいずれかに、"
" その案が受け入れられそうか確認する。\n"
"- 生産面の制約は dev_m に必ず確認する。\n"
),
)
# ===========================================
# Swarm の生成
# ===========================================
swarm = Swarm(
nodes=[ceo, dev_m, dev_f, consumer, marketer],
entry_point=ceo,
max_handoffs=20, # 会話ラリーを増やす方向に寄せる(保証ではない)
max_iterations=20, # ノード実行回数の上限(多め)
execution_timeout=900.0, # 全体タイムアウト(秒)
node_timeout=240.0, # 各ノードタイムアウト(秒)
repetitive_handoff_detection_window=12,
repetitive_handoff_min_unique_agents=4,
)
# ===========================================
# ログ表示用ユーティリティ(会議ログ風)
# ===========================================
ROLE_LABELS = {
"ceo": "社長",
"dev_m": "開発(男性・製造技術)",
"dev_f": "開発(女性・栄養・企画)",
"consumer": "一般消費者",
"marketer": "マーケッター",
}
def print_swarm_meeting(result):
"""
SwarmResult を、発言順のダイジェストだけ表示する簡易ログ。
各エージェントの「最終発言テキスト」はあえて出さない。
"""
print("=== 星見堂製菓・新商品企画 会議ログ(ダイジェスト) ===")
print(f"全体ステータス : {result.status}")
usage = getattr(result, "accumulated_usage", None) or {}
print(f"総トークン数 : {usage.get('totalTokens', 'N/A')}")
print(f"ノード実行回数 : {getattr(result, 'execution_count', 'N/A')}")
print()
history = getattr(result, "node_history", []) or []
if history:
print("--- 発言順(node_history ベースのラリー)---")
for i, node in enumerate(history, start=1):
name = getattr(node, "node_id", str(node))
label = ROLE_LABELS.get(name, name)
print(f"{i:02d}. {label}")
print()
print("=== End ===")
# ===========================================
# 実行部
# ===========================================
if __name__ == "__main__":
task = (
"あなたたちは、星見堂製菓株式会社の新商品企画会議のメンバーです。"
"テーマは『働く20〜40代向けの、罪悪感の少ないご褒美チョコ菓子』です。"
"60〜90分のリアルな会議を想定し、最低でも50ラリー程度の対話を行いながら、"
"最終的に有望な新商品コンセプトを1案に絞り込み、その概要(ターゲット、シーン、"
"味・形状のイメージ、栄養・原価の方向性、売上ポテンシャルのラフ試算)をまとめてください。"
"最終的な案が定まるまで議論を尽くしてください。"
)
result = swarm(task)
print_swarm_meeting(result)
参加者全員が同じ会議室にいるかのように発言し合う様子が面白いです。
実行結果
皆さん、お疲れ様です。今日は『働く20〜40代向けの、罪悪感の少ないご褒美チョコ菓子』という新商品企画について議論していきましょう。
まず最初に確認したいのですが、この「罪悪感の少ない」という部分について、実際の消費者はどのような要素に罪悪感を感じているのでしょうか?カロリーなのか、糖質なのか、それとも他の要因なのか。
Tool #1: handoff_to_agent
わあ、まさに私のことですね!罪悪感の話、すごくよく分かります。
私、仕事帰りにコンビニでチョコを買うとき、いつも「また買っちゃった...」って思うんです。特に残業で疲れてるときほど甘いものが欲しくなるんですけど、家に帰ってから「今日もカロリー摂りすぎた」って後悔するんですよね。友人たちも同じで、「ストレス食いしちゃう」「でも太りたくない」っていうジレンマをみんな抱えてます。
あと、在宅ワーク中も手が伸びちゃうんですが、一日中家にいるのに甘いもの食べてる罪悪感もあって...。
Tool #1: handoff_to_agent
消費者心理を分析すると、罪悪感は「カロリー・糖質・添加物への不安」「時間帯・頻度への後ろめたさ」「自己管理できていない感」の3つに分解できますね。つまり、機能性(プロテイン・食物繊維配合)と時間価値(仕事の合間の効率的な栄養補給)を前面に出せば、『おやつ』ではなく『機能性食品』としてポジショニングできます。
ターゲットは「健康意識高めだが忙しくて完璧にはできない20-30代女性」、シーンは「午後3時の集中力切れ・残業前の栄養チャージ」で攻めたいと思います。
Tool #1: handoff_to_agent
ありがとうございます。機能性チョコでプロテイン5-7g、食物繊維3-4g配合の技術的実現性について検討いたします。
私の試作経験では、プロテインパウダー(ホエイ・カゼイン混合)と難消化性デキストリンを使えば、この栄養値は十分達成可能です。ただし、プロテイン特有の粉っぽさとビター感のバランスが課題になりそうですね。甘さ控えめでビターな大人味なら、カカオ含有率70%ベースで、天然甘味料(エリスリトール+ステビア)を組み合わせることで実現できると思います。
Tool #1: handoff_to_agent
プロテイン5-7g、食物繊維3-4g配合の機能性チョコレートですね。技術的には確かに課題がありますが、面白いコンセプトだと思います。
プロテインの粉っぽさについては、大豆プロテインではなくホエイプロテインを使い、さらに乳化剤(レシチン)を増量することで改善できる可能性があります。カカオ70%ベースでも、ココアバター比率を調整すれば成型性は確保できそうですが、原価が1本あたり50円近くになる計算です。
Tool #1: handoff_to_agent
原価50円/本というのは確かに高いですね。これだと店頭価格は150-180円程度になってしまう。
プロテイン配合という機能性は魅力的だが、この価格帯で本当に働く20-40代が日常的に購入してくれるのか、慎重に見極める必要がありそうです。
Tool #2: handoff_to_agent
プロテイン配合チョコの150-180円価格帯について分析しました。この価格は一般的なコンビニチョコより50-80円高いですが、高たんぱく系バーの競合商品(プロテインバーやSAVAS等)が同価格帯で展開しており、「機能性付加価値」として受け入れられる範囲内です。
働く20-40代の「罪悪感の少ないご褒美」需要層(全体の35%、月3,000-5,000円使用)なら、週1-2回の購買頻度で十分にリーチできる価格設定と判断します。市場規模的にも糖質オフ・高たんぱく系が+12%成長している追い風があります。
Tool #2: handoff_to_agent
皆さん、お疲れ様でした。価格受容性の分析結果を踏まえると、150-180円の価格帯で機能性を訴求する方向性は非常に合理的ですね。
ただし、最終決定の前に一点確認したいことがあります。この価格帯と機能性訴求で、我々の主力ブランド「夜ふかしショコラ」との差別化は十分図れるでしょうか?
Tool #3: handoff_to_agent
既存の「夜ふかしショコラ」との差別化について整理しますね。「夜ふかしショコラ」は夜の疲れた時の癒し・リラックスがコアですが、新商品は日中の仕事シーンでの「罪悪感ゼロのエネルギーチャージ」で明確に差別化できます。ターゲットも夜型から昼間のアクティブワーカーにシフトし、むしろブランドポートフォリオとして24時間カバーできる相乗効果が期待できます。
売上試算では、糖質オフ・高たんぱく市場の成長率12%を踏まえると、初年度3億円は十分狙えそうですが、この差別化戦略で本当にカニバリを避けられるか、CEOの最終判断をお聞きしたいと思います。
Tool #3: handoff_to_agent
なるほど、夜ふかしショコラとの時間軸での差別化という戦略は理解できました。ただ、売上目標3億円という数字について、もう少し詳しく検証したいですね。
この目標が現実的かどうか、コンビニでの展開規模や単価設定を具体的に想定して試算していただけますか?
Tool #4: handoff_to_agent
承知いたしました。売上目標3億円の実現可能性について検証いたします。
まず、夜ふかしショコラの実績を基準に考えると、市場シェア8%で年間約2.5億円の売上実績があります。新商品で3億円を目指すには、より大きな市場での展開か、より高い単価設定が必要になりますね。
コンビニチャネルでの現実的な展開を想定すると、全国約5.5万店舗のうち約3万店舗での展開、3ヶ月間の集中販売期間、想定単価200円とした場合、1店舗あたり月50個の販売が必要で、これは夜ふかしショコラの実績から見ても達成可能な数字だと判断します。
Tool #4: handoff_to_agent
なるほど、売上目標3億円の試算は確かに説得力がありますね。ただ、最終決定前に一点確認したいことがあります。
「罪悪感レス」という価値提案が本当に働く20〜40代の購買行動を変えるのか、もう少し消費者心理の深掘りが必要ではないでしょうか。
Tool #5: handoff_to_agent
月50個レベルのリピート?正直それはちょっと現実的じゃないと思います。私みたいにコンビニで週3〜4回お菓子買う人でも、同じ商品をそこまで集中的に買うことはないですね。
「罪悪感レス」って言葉自体はいいんですけど、実際に手に取るときは「今日は疲れたから甘いもの食べたい」とか「仕事の合間にちょっと口寂しい」とか、そういう瞬間的な気持ちで選んでるんです。その時に既存のヘルシー系商品と何が違うのかが分からないと、結局いつものチョコを選んじゃいます。
Tool #2: handoff_to_agent
月50個という数字、確かに現実的じゃないですね。データを見直すと、『罪悪感の少ないご褒美おやつ』に月3,000〜5,000円使う層が35%いますが、これは1個150円として月20〜33個程度が現実的なライン。
差別化ポイントとしては、『健康っぽいだけでまずい』への拒否感が強いデータから、「美味しさ×罪悪感軽減」の両立が鍵で、特に夜勤・残業シーンでの「頑張った自分へのご褒美」という納得感が重要だと思います。
Tool #5: handoff_to_agent
月20〜30個って、週5〜7個ですよね?正直、それはちょっと多すぎるかも。私でも週3〜4回コンビニでお菓子買うけど、同じ商品をそんなに食べないです。
夜勤や残業の「頑張った自分へのご褒美」っていうのはすごく分かります!でも毎日残業してるわけじゃないし、ご褒美って特別感があるから嬉しいんですよね。週2〜3個くらいが現実的じゃないでしょうか。
Tool #3: handoff_to_agent
消費者の方のフィードバックは的確ですね。週2〜3個(月8〜12個)なら「特別感」も維持できて現実的です。
この頻度で再計算すると、ターゲット層35%×月10個平均として、売上ポテンシャルは月間約350万個になります。単価200円想定なら月商7億円規模で、これなら十分に事業として成立する数字です。
Tool #6: handoff_to_agent
月商7億円規模で「特別なご褒美感」というポジショニングですね。数字的には魅力的ですが、気になるのは競合との差別化と継続的な成長シナリオです。
この規模感だと、初年度だけでなく2-3年後の展開も考える必要があります。「特別感」を維持しながら、どう市場を拡大していくかが課題になりそうです。
Tool #6: handoff_to_agent
=== 星見堂製菓・新商品企画 会議ログ(ダイジェスト) ===
全体ステータス : Status.FAILED
総トークン数 : 182449
ノード実行回数 : 17
--- 発言順(node_history ベースのラリー)---
- 社長
- 一般消費者
- マーケッター
- 開発(女性・栄養・企画)
- 開発(男性・製造技術)
- 社長
- マーケッター
- 社長
- マーケッター
- 社長
- マーケッター
- 社長
- 一般消費者
- マーケッター
- 一般消費者
- マーケッター
- 社長
=== End ===
実行結果を見ると企画の方向性は決まった方ですが、具体的な商品の企画までは至っていないようです。さらに議論を続けるよう設定を変えるか、あるいはSwarm自体を一つのツールとして呼び出して結論をまとめるオーケストレーターを用意するとより議論の質を上げることができそうです。
workflow
Workflow の実装方法は2つあります。1つは、agentの実行をプログラム側でシーケンシャルにすることで自前実装する方法、もう一つはフレームワークに用意されたツールを使う方法です。
第1の方法の実装例はこんな感じです。
# エージェントは定義済みとする
def process_workflow(topic):
# Step 1: Research
research_results = researcher(f"Research the latest developments in {topic}")
# Step 2: Analysis
analysis = analyst(f"Analyze these research findings: {research_results}")
# Step 3: Report writing
final_report = writer(f"Create a report based on this analysis: {analysis}")
return final_report
参考:https://strandsagents.com/latest/documentation/docs/user-guide/concepts/multi-agent/workflow/
順次agent関数を実行して、その結果を次のエージェントに流すだけです。
次にツールを使った方法はこのように書きます。
agent.tool.workflow(
action="create",
workflow_id="data_analysis",
tasks=[
{
"task_id": "data_extraction",
"description": "Extract key financial data from the quarterly report",
"system_prompt": "You extract and structure financial data from reports.",
"priority": 5
},
{
"task_id": "trend_analysis",
"description": "Analyze trends in the data compared to previous quarters",
"dependencies": ["data_extraction"],
"system_prompt": "You identify trends in financial time series.",
"priority": 3
},
{
"task_id": "report_generation",
"description": "Generate a comprehensive analysis report",
"dependencies": ["trend_analysis"],
"system_prompt": "You create clear financial analysis reports.",
"priority": 2
}
]
)
ワークフロー中の単体の処理の定義はtask_id、description、dependencies、system_prompt、priorityより構成されます。task_idは処理につける識別子です。descriptionは処理の中身を記述します。dependenciesはワークフロー中でどのタスクがどれの後に走るか依存関係を定義します。priorityは依存関係が満たされた中での実行の優先順位を決定します。
上記の例ではdata_extraction→trend_analysis→report_generationという流れで処理されることがわかります。タスクごとに異なるエージェントが起動され、それぞれのタスクを全うして後続の処理にコンテキストを共有します。
さて、workflowツールを用いてデータリサーチ&データ分析ワークフローを組んでみます。具体的には過去の東京の平均気温の推移について調べるタスクを振ってみます。東京の平均気温を調べるタスクを、情報の取得、分析、レポートという3つの段階に分けてそれぞれこの順番で実行させます。情報収集担当のエージェントにはweb検索ツールを、分析処理を担当するエージェントにはpython_replというpythonをサンドボックス環境で実行するツールを持たせます。
from strands import Agent, tool
from strands_tools import workflow, python_repl, http_request
from ddgs import DDGS
_ddgs = DDGS()
# ===========================================
# Web検索ツール(既存)
# ===========================================
@tool
def web_search(query: str, n: int = 5) -> list[dict]:
"""DuckDuckGo由来のメタ検索で上位結果を返す簡易ツール。
検索のみのため、Webページの内容閲覧には http_request ツールを使用すること。
Args:
query: 検索クエリ文字列(例: "Tokyo monthly mean temperature JMA 1991-2020")
n: 取得件数(上位n件、既定値=5)
Returns:
list[dict]: 各要素は以下のキーを持つ辞書。
- title (str): 検索結果のタイトル
- url (str): 該当ページのURL
"""
return [
{"title": r["title"], "url": r["href"]}
for r in _ddgs.text(query, max_results=n)
]
# ===========================================
# オーケストレーター Agent(かなり薄いシステムプロンプト)
# ===========================================
orchestrator = Agent(
name="workflow_orchestrator",
system_prompt=(
"あなたはワークフローオーケストレーターです。"
"workflow ツールで定義されたタスクを、依存関係と優先度に従って実行します。"
"各タスクには、そのタスク専用の system_prompt と description が与えられているので、"
"あなた自身はドメイン知識に踏み込まず、workflow の実行管理だけに集中してください。"
),
tools=[
workflow, # ワークフロー実行
web_search, # Web検索
http_request, # Webページ内容取得
python_repl, # Pythonコード実行
],
)
# ===========================================
# ワークフローの定義
# ===========================================
WORKFLOW_ID = "tokyo_climate_trend_workflow"
orchestrator.tool.workflow(
action="create",
workflow_id=WORKFLOW_ID,
tasks=[
# -----------------------------
# 1. research タスク
# -----------------------------
{
"task_id": "research",
"description": (
"目的: 東京の『月別平均気温(1991〜2020年平年値)』の数値を、公的な情報源から取得する。\n\n"
"要件:\n"
"- 信頼できる公的ソース(気象庁 Japan Meteorological Agency)を優先すること。\n"
"- 対象は Tokyo の年平均ではなく、1〜12月の月別平均気温 (mean temperature) の平年値とする。\n"
"- 取得した値は、後続タスクで機械的に扱えるよう JSON 形式で整理する。\n\n"
"推奨する進め方(あくまで参考。自律的に工夫してよい):\n"
"1. web_search ツールで、JMA の『Tables of Climatological Normals (1991–2020) Tokyo』"
" に相当するページを検索する。\n"
"2. 有望な候補の URL から、気象庁公式サイトと思われるものを選び、http_request の GET で取得する。\n"
"3. 取得した HTML またはテキストから、Tokyo の行の mean temperature (°C) の12ヶ月分を読み取る。\n"
"4. 数値はページに記載されているものをそのまま用い、推測や補間は行わない。\n\n"
"出力フォーマット(厳守):\n"
"{\n"
' \"source_url\": \"...\", # 利用したJMAページのURL\n'
' \"unit\": \"degC\", # 単位(摂氏)\n'
" \"monthly_mean_temp\": {\n"
' \"Jan\": <float>, \"Feb\": <float>, ..., \"Dec\": <float>\n'
" }\n"
"}\n\n"
"注意:\n"
"- 12ヶ月分すべて取得できない場合は、その旨をJSONにフラグとして含め、欠損があることを明示すること。\n"
"- 上記 JSON オブジェクト以外のテキスト(説明文など)は出力しないこと。\n"
),
"system_prompt": (
"あなたはリサーチ専任のエージェントです。"
"与えられたタスク description をよく読み、そこに書かれた要件と出力フォーマットを満たすように、"
"指定されたツール(web_search, http_request)のみを使って自律的に調査・整形してください。"
),
"priority": 5,
"tools": ["web_search", "http_request"],
},
# -----------------------------
# 2. analysis タスク
# -----------------------------
{
"task_id": "analysis",
"description": (
"目的: research タスクから渡される JSON(月別平均気温データ)を用いて、"
"東京の一年間における気温パターンを定量的に把握する。\n\n"
"前提入力:\n"
"- 次のような構造の JSON オブジェクトを受け取ることを想定する:\n"
" {\n"
" \"source_url\": \"...\",\n"
" \"unit\": \"degC\",\n"
" \"monthly_mean_temp\": {\n"
" \"Jan\": <float>, ..., \"Dec\": <float>\n"
" }\n"
" }\n\n"
"やってほしいこと:\n"
"- monthly_mean_temp を Python で扱いやすい形(リストや dict, pandas.DataFrame など)に変換する。\n"
"- 次の指標を Python で計算し、その結果を用いて解釈を行う:\n"
" 1. 12ヶ月での最小値と最大値、およびその月名と差分(最大-最小)。\n"
" 2. 季節ごとの平均気温(例: 冬=12,1,2月 / 春=3〜5月 / 夏=6〜8月 / 秋=9〜11月)\n"
" 3. 月番号(1〜12)と平均気温のペアの一覧(シンプルな折れ線グラフを想定したデータ)\n\n"
"重要:\n"
"- すべての数値計算は python_repl ツール上のコードで実行すること。"
" あなた自身の頭の中だけで計算して結果を書くことは禁止とする。\n"
"- python_repl の実行結果をもとに、人間向けのテキストでパターンを説明する。\n\n"
"出力フォーマット(人間向けテキスト):\n"
"1. 『分析に使用したデータ概要』(source_url, 単位, 何年の平年値か)\n"
"2. 『年内の温度レンジ』(最も寒い月と最も暑い月、その差分)\n"
"3. 『季節ごとの平均気温と特徴』\n"
"4. 『簡単な含意』(例: 夏と冬のギャップがどれくらいか、生活・設備への一般的な影響)\n"
"※ JSON ではなく通常の文章でよい。\n"
),
"system_prompt": (
"あなたはデータアナリストです。"
"タスク description に書かれた計算要件を満たすために、"
"必ず python_repl ツールを用いて数値計算を行い、その結果に基づいて文章で解釈してください。"
"手計算や暗算だけで結論を書くことは避けてください。"
),
"dependencies": ["research"],
"priority": 3,
"tools": ["python_repl"],
},
# -----------------------------
# 3. report タスク
# -----------------------------
{
"task_id": "report",
"description": (
"目的: 東京の月別平均気温(1991〜2020年平年値)について、"
"一般の人が読んでも分かりやすい日本語レポートを作成する。\n\n"
"前提入力:\n"
"- analysis タスクからは、季節ごとの気温レンジや年内の温度差に関する文章が渡される想定。\n\n"
"レポートの要件:\n"
"- 文字数の目安は 500〜800字程度。\n"
"- 内容は、誰も不快にならない中立的な気候説明とし、特定の属性や地域を揶揄しない。\n"
"- 構成は以下を含むこと:\n"
" 1. タイトル\n"
" 2. データの出典・前提(気象庁の平年値であること、対象期間、単位など)\n"
" 3. 春夏秋冬それぞれの平均気温と体感的なイメージ\n"
" 4. 生活やビジネスの観点での含意(例: 冷暖房負荷、服装、熱中症・寒さ対策など)\n"
" 5. 簡潔なまとめ\n"
),
"system_prompt": (
"あなたはテクニカルライターです。"
"タスク description に記載された構成とトーンに従い、"
"analysis タスクから渡される内容をもとに、"
"読みやすく一貫性のある日本語レポートを書いてください。"
),
"dependencies": ["analysis"],
"priority": 1,
# report ではツール無し
},
],
)
# ===========================================
# 実行
# ===========================================
orchestrator.tool.workflow(
action="start",
workflow_id=WORKFLOW_ID,
topic=(
"東京(気象庁が公開する1991〜2020年の平年値)における"
"月別平均気温の季節トレンドを分析し、その特徴を分かりやすく説明する。"
),
)
status = orchestrator.tool.workflow(
action="status",
workflow_id=WORKFLOW_ID,
)
実行結果
I'll help you retrieve the monthly mean temperature data for Tokyo from the Japan Meteorological Agency (JMA). Let me start by searching for the official JMA climatological normals data.
<web_search>
JMA Japan Meteorological Agency Tokyo climatological normals 1991-2020 monthly mean temperature
</web_search>
Now let me search more specifically for the JMA tables with climatological normals:
<web_search>
site:jma.go.jp "Tables of Climatological Normals" Tokyo 1991-2020 monthly mean temperature
</web_search>
Let me try a more direct search for JMA climatological data:
<web_search>
"Japan Meteorological Agency" climatological normals Tokyo monthly temperature 1991-2020
</web_search>
Let me search for the specific JMA page with climatological normals:
<web_search>
jma.go.jp climatological normals 1991-2020 Tokyo monthly temperature table
</web_search>
Now let me try to access what appears to be a promising JMA URL for climatological normals:
<http_request>
GET https://www.jma.go.jp/jma/en/Activities/climatological_normals.html
</http_request>
Let me try the Japanese version of the climatological normals page:
<http_request>
GET https://www.jma.go.jp/jma/kishou/know/kisetsu_riyou/climatological_normals.html
</http_request>
Let me search for the specific data tables on JMA:
<web_search>
site:jma.go.jp "平年値" 東京 月別 気温 1991-2020
</web_search>
Let me try to access a more specific JMA data page:
<http_request>
GET https://www.jma.go.jp/bosai/forecast/data/forecast/130000.json
</http_search>
Let me search for JMA statistical data pages:
<web_search>
site:jma.go.jp statistics climatological normal values Tokyo monthly
</web_search>
Let me try accessing the JMA statistics portal:
<http_request>
GET https://www.jma.go.jp/jma/menu/report.html
</http_request>
Let me search for JMA climate data with a different approach:
<web_search>
"気象庁" "平年値" "東京" "月平均気温" 1991-2020 表
</web_search>
Let me try to access the JMA climate statistics page:
<http_request>
GET https://www.jma.go.jp/jma/kishou/info/coment.html
</http_request>
Let me search specifically for Tokyo station climatological data:
<web_search>
jma.go.jp Tokyo station 44132 climatological normals monthly mean temperature
</web_search>
Let me try accessing what appears to be a JMA data portal:
<http_request>
GET https://www.data.jma.go.jp/
</http_request>
Let me search for the JMA online database:
<web_search>
"data.jma.go.jp" Tokyo monthly mean temperature normals 1991-2020
</web_search>
Let me try to access the JMA online database directly:
<http_request>
GET https://www.data.jma.go.jp/gmd/risk/obsdl/index.php
</http_request>
Let me search for more specific JMA climate data resources:
<web_search>
site:data.jma.go.jp climatological normals Tokyo monthly temperature
</web_search>
Let me try searching for JMA past weather data:
<web_search>
"data.jma.go.jp" "過去の気象データ" 東京 平年値 月平均気温
</web_search>
Let me try to access the JMA historical weather data page:
<http_request>
GET https://www.data.jma.go.jp/obd/stats/etrn/index.php
</http_request>
Let me try to access a specific page for Tokyo climatological data:
<http_request>
GET https://www.data.jma.go.jp/obd/stats/etrn/view/nml_sfc_ym.php?prec_no=44&block_no=47662
</http_request>
Let me try with the Tokyo station code:
<http_request>
GET https://www.data.jma.go.jp/obd/stats/etrn/view/nml_sfc_ym.php?prec_no=44&block_no=47662&year=&month=&day=&view=
</http_request>
Let me search for the correct Tokyo station parameters:
<web_search>
"data.jma.go.jp" Tokyo station code 平年値 monthly normals 47662
</web_search>
Let me try a more general approach to the JMA normals page:
<http_request>
GET https://www.data.jma.go.jp/obd/stats/etrn/view/nml_sfc_ym.php?prec_no=44&block_no=47662&year=&month=&day=&view=a1
</http_request>
Based on my searches, let me try to access what appears to be the correct format for JMA normals data:
<http_request>
GET https://www.data.jma.go.jp/obd/stats/etrn/view/nml_sfc_ym.php?prec_no=44&block_no=47662&year=&month=&day=&view=h1
</http_request>
{
"source_url": "https://www.data.jma.go.jp/obd/stats/etrn/view/nml_sfc_ym.php?prec_no=44&block_no=47662&year=&month=&day=&view=h1",
"unit": "degC",
"monthly_mean_temp": {
"Jan": 6.1,
"Feb": 7.0,
"Mar": 10.4,
"Apr": 15.4,
"May": 20.0,
"Jun": 23.2,
"Jul": 26.9,
"Aug": 28.1,
"Sep": 24.2,
"Oct": 18.8,
"Nov": 13.3,
"Dec": 8.7
}
}東京の気温データを定量的に分析させていただきます。まず、受け取ったJSONデータをPythonで処理しましょう。
import json
import pandas as pd
import numpy as np
# 受け取ったJSONデータ
data = {
"source_url": "https://www.data.jma.go.jp/obd/stats/etrn/view/nml_sfc_ym.php?prec_no=44&block_no=47662&year=&month=&day=&view=h1",
"unit": "degC",
"monthly_mean_temp": {
"Jan": 6.1,
"Feb": 7.0,
"Mar": 10.4,
"Apr": 15.4,
"May": 20.0,
"Jun": 23.2,
"Jul": 26.9,
"Aug": 28.1,
"Sep": 24.2,
"Oct": 18.8,
"Nov": 13.3,
"Dec": 8.7
}
}
print("受け取ったデータ:")
print(f"データソース: {data['source_url']}")
print(f"単位: {data['unit']}")
print("月別平均気温:")
for month, temp in data['monthly_mean_temp'].items():
print(f" {month}: {temp}°C")
# データを扱いやすい形に変換
monthly_temps = data['monthly_mean_temp']
# 1. 最小値・最大値とその月名、差分の計算
min_temp = min(monthly_temps.values())
max_temp = max(monthly_temps.values())
min_month = [month for month, temp in monthly_temps.items() if temp == min_temp][0]
max_month = [month for month, temp in monthly_temps.items() if temp == max_temp][0]
temp_range = max_temp - min_temp
print("=== 年内の温度レンジ ===")
print(f"最も寒い月: {min_month} ({min_temp}°C)")
print(f"最も暑い月: {max_month} ({max_temp}°C)")
print(f"気温差: {temp_range}°C")
# 2. 季節ごとの平均気温計算
# 冬=12,1,2月 / 春=3〜5月 / 夏=6〜8月 / 秋=9〜11月
seasons = {
'冬': ['Dec', 'Jan', 'Feb'],
'春': ['Mar', 'Apr', 'May'],
'夏': ['Jun', 'Jul', 'Aug'],
'秋': ['Sep', 'Oct', 'Nov']
}
seasonal_averages = {}
for season, months in seasons.items():
temps = [monthly_temps[month] for month in months]
avg_temp = sum(temps) / len(temps)
seasonal_averages[season] = avg_temp
print("=== 季節ごとの平均気温 ===")
for season, avg in seasonal_averages.items():
print(f"{season}: {avg:.1f}°C")
# 3. 月番号と平均気温のペア(グラフ用データ)
month_order = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun',
'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
monthly_data = []
for i, month in enumerate(month_order, 1):
monthly_data.append((i, monthly_temps[month]))
print("=== 月番号と平均気温のペア ===")
print("月番号, 平均気温(°C)")
for month_num, temp in monthly_data:
print(f"{month_num:2d}, {temp}")
# 追加の統計情報
temps_list = [monthly_temps[month] for month in month_order]
annual_mean = sum(temps_list) / len(temps_list)
print("=== 追加統計情報 ===")
print(f"年間平均気温: {annual_mean:.1f}°C")
print(f"標準偏差: {np.std(temps_list):.1f}°C")
# 季節間の気温差
winter_summer_diff = seasonal_averages['夏'] - seasonal_averages['冬']
print(f"夏と冬の平均気温差: {winter_summer_diff:.1f}°C")
分析結果
1. 分析に使用したデータ概要
- データソース: 気象庁(JMA)の過去の気象データ・ダウンロードページ
- 単位: 摂氏(°C)
- 対象期間: 1991-2020年平年値(30年間の統計的平均)
- 観測地点: 東京(気象庁観測所)
2. 年内の温度レンジ
- 最も寒い月: 1月(6.1°C)
- 最も暑い月: 8月(28.1°C)
- 年間気温差: 22.0°C
東京では1月と8月の間に22°Cもの大きな気温差があり、これは典型的な温帯モンスーン気候の特徴を示しています。
3. 季節ごとの平均気温と特徴
- 冬季(12-2月): 7.3°C
- 春季(3-5月): 15.3°C
- 夏季(6-8月): 26.1°C
- 秋季(9-11月): 18.8°C
季節の変化は明瞭で、春から夏にかけて10.8°C、夏から冬にかけて18.8°Cの大きな気温変化があります。秋の気温(18.8°C)は春(15.3°C)より3.5°C高く、これは海洋の熱慣性による影響と考えられます。
4. 簡単な含意
夏と冬のギャップ: 夏と冬の平均気温差は18.8°Cに達し、これは以下のような生活・設備への影響をもたらします:
- 冷暖房需要: 年間を通じて大きなエネルギー消費が必要
- 服装・生活様式: 季節に応じた大幅な調整が必要
- 建築設計: 断熱性能と換気性能の両方を考慮した設計が重要
- 健康管理: 季節の変わり目での体調管理に注意が必要
年間平均気温は16.8°Cで、四季がはっきりと分かれた快適な気候といえますが、気温の季節変動が大きいため、それに対応した生活インフラの整備が重要であることが分かります。# 東京の気候データ解説:月別平均気温から見る四季の特徴
データ概要
本レポートは、気象庁が公表している1991年から2020年の30年間の統計データ(平年値)をもとに、東京の月別平均気温を分析したものです。単位は摂氏(°C)で表示しています。
季節ごとの気温特性
冬季(12~2月):平均7.3°C
最も寒い1月でも平均気温は6.1°Cと、本州の中では比較的温暖です。朝晩は冷え込みますが、日中は陽だまりで暖かさを感じられる日も多くあります。
春季(3~5月):平均15.3°C
3月の10.4°Cから5月の20.0°Cまで、約10°Cの気温上昇があります。桜の開花時期にあたる3~4月は過ごしやすく、薄手の上着で快適に過ごせる季節です。
夏季(6~8月):平均26.1°C
最も暑い8月は28.1°Cに達します。湿度も高くなるため、実際の体感温度はさらに高く感じられます。熱中症対策が重要な時期となります。
秋季(9~11月):平均18.8°C
夏の暑さから徐々に涼しくなり、春よりもやや暖かい気温が続きます。日中と朝晩の寒暖差が大きくなる特徴があります。
生活・ビジネスへの影響
東京の年間気温差は22.0°Cと大きく、これは日常生活に多方面の影響を与えます。
エネルギー消費の観点では、夏季の冷房需要と冬季の暖房需要が両方とも必要となり、年間を通じて空調コストがかかります。
健康管理の面では、季節の変わり目での気温変化に体調を合わせる必要があり、特に夏季の熱中症対策と冬季の風邪予防が重要です。
衣類・ファッション業界では、四季に応じた幅広い商品展開が求められ、季節商材の需要予測にこのデータが活用されています。
まとめ
東京は年間平均気温16.8°Cの温暖な気候ですが、四季の変化がはっきりしており、季節ごとの気温差が大きいのが特徴です。この気候特性を理解することで、より快適で効率的な生活設計や事業計画の立案が可能になります。
データの収集にはやや苦戦している様子が見て取れますが、見事東京の平均気温データを取得し、統計的な計算を施していることが分かります。
Graph
Graph はエージェントがノードとして連結し、次のノードに対してタスクの実行を依頼するような連鎖を作ります。つまり、エージェント同士の関係はグラフとして表せます。エージェントの定義はここまでと同様ですが、graphに特徴的なコードを挙げてみます。
builder = GraphBuilder()
# ノードの追加
builder.add_node(researcher, "research")
builder.add_node(analyst, "analysis")
builder.add_node(fact_checker, "fact_check")
builder.add_node(report_writer, "report")
# エッジの追加
builder.add_edge("research", "analysis")
builder.add_edge("research", "fact_check")
builder.add_edge("analysis", "report")
builder.add_edge("fact_check", "report")
# エントリーポイントの定義
builder.set_entry_point("research")
ノードの追加は、グラフに登場するエージェントを「点」として定義します。エッジの追加ではノードの関係性を定義します。エントリーポイントを定義することで、議論の開始点となるエージェントを指定します。上の例では、リサーチャーが議論を開始し、その結果を必要に応じてanalystとfact_checkerにパスできます。analystとfact_checkerは自身の分析結果をreport_writerに渡すことで最終的な結果を記事にします。
参考:https://strandsagents.com/latest/documentation/docs/user-guide/concepts/multi-agent/graph/
ここでは、あるテーマに基づいて記事を書き上げるマルチエージェントシステムを実装してみます。記事の作成をresearcher(リサーチ担当)、fact_checker(ファクトチェック担当)、report_writer(記事の執筆担当)、analyst(構成・分析担当)の4つの役割に分けてみました。記事の作成をresearcherとfact_checkerはweb検索ツールを使えます。実際の記事に触れるreport_writerとanalystにはfile_write,editor,file_readなどローカルファイルを操作するツールを与えます。
import logging
from strands import Agent, tool
from strands.multiagent import GraphBuilder
from strands_tools import file_write,editor,file_read
from ddgs import DDGS
_ddgs = DDGS()
@tool
def web_search(query: str, n: int = 5) -> list[dict]:
"""DuckDuckGo由来のメタ検索で上位結果を返す簡易ツール。
検索のみのため、Webページの内容閲覧にはhttp_requestツールを使用すること。
Args:
query: 検索クエリ文字列(例: "Python typing guide 最新")
n: 取得件数(上位n件、既定値=5)
Returns:
list[dict]: 各要素は以下のキーを持つ辞書。
- title (str): 検索結果のタイトル
- url (str): 該当ページのURL
"""
return [{"title": r["title"], "url": r["href"]}
for r in _ddgs.text(query, max_results=n)]
# ============================================================
# Web記事制作フロー用の専門エージェント定義
# ============================================================
# リサーチ担当ライター
researcher = Agent(
name="researcher",
tools = [web_search],
system_prompt="""
あなたはオンラインメディア編集部の「リサーチ担当ライター」です。
【役割】
- 指定されたテーマについて、信頼性の高い一次情報や公的機関・専門家による情報源を優先して調査します。
- 偏りの少ない複数の情報源を確認し、主張が異なる場合はその違いと理由を整理して提示します。
- 読者は一般の社会人を想定し、難解な専門用語には必ず簡潔な日本語での説明を添えます。
【出力フォーマット】
1. 想定読者像とニーズ(箇条書き)
2. 記事に盛り込むべき重要な論点・小見出し候補(箇条書き)
3. 参考にした情報源リスト(サイト名+概要+URL)
4. 注意すべき論点(誤解されやすい点や、まだ議論中の点)
【トーンと配慮】
- 中立でフラットなトーンを保ち、特定の個人・集団・属性を貶める表現は一切使用しないでください。
- 健康・お金など生活に関わるテーマでは、あくまで一般的な情報であり、個別の専門的アドバイスではないことを明示します。
"""
)
# 構成・分析担当(記事構成プランナー)
analyst = Agent(
name="analyst",
tools = [file_write,editor],
system_prompt="""
あなたはオンラインメディアの「構成・分析担当エディター」です。
【役割】
- リサーチ担当が整理した情報をもとに、Web記事として読みやすく、論理的な構成に組み立てます。
- 読者のペルソナとニーズを踏まえ、「導入」「本論」「まとめ」の流れが自然になるよう構成案を作成します。
- 読了までの離脱を防ぐため、適切な小見出し、セクションの順番、情報の粒度を設計します。
【出力フォーマット】
1. 記事のゴール(読後に読者が理解・行動できること)
2. 記事全体のアウトライン(H2/H3 レベルの見出し構成)
3. 各セクションで伝えるべき要点(箇条書き)
4. 強調したいメッセージ・注意喚起ポイント
【トーンと配慮】
- 読者を不安にさせる表現や煽りタイトルではなく、安心して読める穏やかな構成を優先してください。
- 特定の価値観を押し付けず、「いくつかの選択肢を提案し、読者が選べる」スタイルを心がけてください。
"""
)
# ファクトチェック担当
fact_checker = Agent(
name="fact_checker",
tools = [web_search,file_read],
system_prompt="""
あなたはオンラインメディアの「ファクトチェック担当エディター」です。
【役割】
- リサーチ結果および構成案の中に、事実と異なる可能性がある記述や、誤解されやすい表現がないか確認します。
- 数値・統計・日付・固有名詞などを重点的にチェックし、必要に応じてより信頼性の高い情報源を提示します。
- 推測や一般論しか言えない部分については、その旨を明記するよう指摘します。
【出力フォーマット】
1. 問題となりうる記述の一覧(引用+理由)
2. 正確な情報またはより妥当な表現案
3. 参照した情報源(サイト名+概要+URL)
4. 記事内で注意書きを添えるべきポイント
【トーンと配慮】
- ライターや編集者を責めるような表現は避け、「建設的な改善提案」として丁寧な指摘を行ってください。
- 特定の個人・組織・属性に対して断定的な否定表現を使わないよう注意してください。
"""
)
# 記事執筆担当ライター
report_writer = Agent(
name="report_writer",
tools = [file_read,editor,file_write],
system_prompt="""
あなたは一般向けWebメディアで記事を書く「プロフェッショナルなライター」です。
【役割】
- これまでのリサーチ結果・構成案・ファクトチェック結果を踏まえ、読みやすく実用的な日本語のWeb記事として仕上げます。
- 見出し・リード文・本文・まとめを通して、一貫したメッセージと読みやすいリズムを意識してください。
- 読者が「自分でもできそう」と感じられる、現実的で負担の少ない提案を行ってください。
【本文スタイル】
- です・ます調で統一し、丁寧かつフラットなトーンを維持します。
- 段落は短めに区切り、必要に応じて箇条書きを用いて可読性を高めます。
- 読者の多様な背景(年齢・性別・家族構成など)を前提に、誰も取り残さない表現を意識してください。
【禁止事項】
- 特定の属性(性別、国籍、人種、年齢、障がい、宗教など)に対する差別的・攻撃的な表現。
- 読者の不安や罪悪感を過度に煽る表現。
- 医療・法律・投資などの専門分野で、専門家の個別アドバイスであるかのように誤解される表現。
最終出力として、完成したWeb記事本文のみを出力してください。
"""
)
# ============================================================
# グラフ構築(エージェント間の依存関係)
# ============================================================
builder = GraphBuilder()
# ノード追加(node_id は元コードと同じ構成を維持)
builder.add_node(researcher, "research")
builder.add_node(analyst, "analysis")
builder.add_node(fact_checker, "fact_check")
builder.add_node(report_writer, "report")
# エッジ定義(依存関係)
# research の結果をもとに analysis と fact_check が動き、
# 最後に report が記事としてまとめるフロー
builder.add_edge("research", "analysis")
builder.add_edge("research", "fact_check")
builder.add_edge("analysis", "report")
builder.add_edge("fact_check", "report")
# エントリーポイントを設定(省略した場合は自動検出)
builder.set_entry_point("research")
# 安全のための実行上限時間(秒)
builder.set_execution_timeout(600) # 10分タイムアウト
# グラフのビルド
graph = builder.build()
# ============================================================
# 誰も不快になりにくいタスクの例
# ============================================================
# テーマ:在宅で楽しめる観葉植物の選び方と育て方
task = (
"初心者向けに、在宅で楽しめる観葉植物の選び方と、"
"毎日無理なく続けられる基本的なお手入れ方法について、"
"一般読者向けの分かりやすいWeb記事を作成してください。"
"読者が安心して日常生活に取り入れられるよう、"
"過度な出費や特定の価値観を押し付けない、やさしい内容にしてください。"
)
# グラフを実行
result = graph(task)
# 実行結果の確認
print(f"\n実行ステータス: {result.status}")
print(f"実行順序: {[node.node_id for node in result.execution_order]}")
実行結果
在宅で楽しむ観葉植物について調査いたします。初心者向けの選び方とお手入れ方法について、複数の信頼性の高い情報源を確認してみましょう。
Tool #1: web_search
検索結果が適切ではありませんでした。日本語で再検索してみます。
Tool #2: web_search
Tool #3: web_search
Tool #4: web_search
日本語での検索が上手くいかないようですので、別のアプローチで検索してみます。
Tool #5: web_search
Tool #6: web_search
Tool #7: web_search
検索結果が日本語の観葉植物に関するものに辿り着きにくいようです。一般的な園芸専門サイトを検索してみます。
Tool #8: web_search
良い検索結果が得られました。続けて他の専門的な情報源も調べてみます。
Tool #9: web_search
これで十分な情報が集められました。調査結果をまとめて記事企画を作成いたします。
初心者向け観葉植物記事企画 - 調査結果
1. 想定読者像とニーズ
- テレワークが増えた会社員:在宅時間が長くなり、部屋に緑を取り入れて癒しの空間を作りたい
- 子育て中の親:子どもにも安全で、忙しい日常でも無理なく続けられる植物を探している
- 一人暮らしの若年層:賃貸住宅でも気軽に始められ、初期費用を抑えたい
- 園芸初心者のシニア層:時間はあるが体力に配慮し、失敗を恐れずに挑戦したい
- インテリアに興味がある人:おしゃれな空間づくりの一環として取り入れたい
2. 記事に盛り込むべき重要な論点・小見出し候補
【選び方編】
- 「まず知っておきたい3つのポイント(置き場所・予算・生活スタイル)」
- 「絶対に失敗しない!超初心者向け植物5選」
- ポトス(つる性で成長が見えやすい)
- サンスベリア(乾燥に強く、空気清浄効果)
- ZZプラント(暗い場所でも元気)
- ガジュマル(丈夫で愛らしい見た目)
- アイビー(小さくて手軽に始められる)
- 「購入時のチェックポイント(葉の色艶、根の状態、害虫の有無)」
- 「どこで買う?園芸店・ホームセンター・ネット通販の特徴」
【基本お手入れ編】
- 「毎日やること・やらなくていいこと」
- 「水やりの『土が乾いたら』を見極める簡単な方法」
- 「季節ごとのお世話カレンダー(春夏秋冬で変わること)」
- 「置き場所の基本(日当たり・風通し・温度管理)」
- 「こんな時どうする?よくあるトラブル対処法」
【続けるコツ編】
- 「忙しい時の手抜きテクニック」
- 「旅行や出張時の管理方法」
- 「成長を楽しむ記録のつけ方」
- 「費用を抑える工夫(100均グッズ活用術)」
3. 参考にした情報源リスト
-
Botanical Note
- 観葉植物の総合的な育て方ガイド
- 科学的根拠に基づいた栽培方法を解説
- URL: https://botanicalnote.com/kanyou-shokubutsu-guide/
-
Select Shop
- 2025年最新の初心者向け観葉植物ガイド
- 基本的な育て方から対策まで網羅
- URL: https://selectshop.jp/houseplants/beginner/grow/
-
みんなの趣味の園芸(NHK出版)
- 公共放送局による信頼性の高い園芸情報
- 専門家監修の植物図鑑と育て方
- URL: https://www.shuminoengei.jp/
-
Japan Plant Care
- 初心者向けの実践的な育て方とインテリア実例
- 日本の住環境に特化した情報
- URL: https://japanplantcare.com/観葉植物初心者向け/
-
Plant Park
- 水やりに特化した詳細ガイド
- 失敗しない方法とタイミングを解説
- URL: https://plant-park.com/houseplants-watering.html
4. 注意すべき論点
【誤解されやすい点】
- 「毎日水をあげる」は間違い:多くの観葉植物は土が乾いてから水やりするのが基本
- 「日当たりが良いほど良い」は危険:直射日光で葉焼けする種類も多い
- 「肥料をたくさんあげれば元気になる」は逆効果:与えすぎは根を傷める原因
【まだ議論中・個人差がある点】
- 水やりの頻度:住環境(湿度・温度・風通し)により大きく変わる
- 最適な置き場所:窓の向きや住宅構造により個別対応が必要
- 土の選び方:市販の培養土で十分か、ブレンドするかは植物と環境次第
【生活に関わる重要な注意事項】
- ペットや小さな子どもがいる家庭:毒性のある植物(ポトス等)の取り扱い注意
- アレルギー:土や植物自体でアレルギー反応を起こす可能性
- 記事の情報は一般的なガイドライン:植物の状態や環境により個別の対応が必要な場合があることを明記
【配慮すべき表現】
- 特定の商品や店舗を過度に推奨しない
- 「絶対」「必ず」などの断定的表現は避け、「一般的に」「多くの場合」を使用
- 失敗体験を否定せず、「試行錯誤も楽しみの一つ」として前向きに表現
この調査結果をもとに、読者が安心して観葉植物ライフを始められる、実践的で親しみやすい記事を作成することができます。この記事企画について、ファクトチェック担当エディターとして詳細に検証させていただきます。まず、提示された植物の情報や調査結果をもとに、育て方について、信読頼性の高い情報源から者が安心して観葉確認を植物を行います。始められる記事構
Tool #1: web_search
成を作成いたします。
Tool #1: file_write
Tool #2: web_search
Tool #3: web_search
Tool #4: web_search
Tool #5: web_search
ここまでの検索結果に加えて、より詳しく調査する必要があります。
Tool #6: web_search
ファクトチェック結果報告
1. 問題となりうる記述の一覧
【重要度:高】ペットへの毒性に関する記述
- 問題箇所: 「ペットや小さな子どもがいる家庭:毒性のある植物(ポトス等)の取り扱い注意」
- 理由: ポトスは確実にペットに有毒だが、その他推奨植物(アイビー、ガジュマル)についての毒性言及が不十分
【重要度:高】断定的な表現
- 問題箇所: 「絶対に失敗しない!超初心者向け植物5選」
- 理由: 「絶対」という表現は誤解を招く。植物の成長は環境や個体差に大きく依存する
【重要度:中】空気清浄効果の科学的根拠
- 問題箇所: 「サンスベリア(乾燥に強く、空気清浄効果)」
- 理由: NASAの研究は実在するが、実際の住環境での効果は限定的との指摘もあり、過度な期待を招く可能性
【重要度:中】ZZプラントに関する記述
- 問題箇所: 「ZZプラント(暗い場所でも元気)」
- 理由: 正式名称「ザミオクルカス」の併記がなく、「暗い場所でも元気」は誤解を招く可能性
2. 正確な情報またはより妥当な表現案
ペットへの毒性について
【修正案】
「ペットや小さな子どもがいる家庭での注意点:
- ポトス、アイビー:犬・猫には有毒(誤食により嘔吐・下痢等の症状)
- サンスベリア:軽微な毒性あり
- ZZプラント(ザミオクルカス):軽微な毒性あり
- ガジュマル:一般的に安全とされるが、個体差あり
※ペットが植物を口にしないよう、手の届かない場所に配置することを推奨」
断定表現の修正
【修正案】
「初心者の方におすすめ!比較的育てやすい植物5選」
「多くの方が成功しやすい植物5選」
空気清浄効果の表現
【修正案】
「サンスベリア(乾燥に強く、NASA研究で空気清浄植物として認定。ただし実際の効果は設置環境により異なります)」
ZZプラントの説明
【修正案】
「ZZプラント(ザミオクルカス)(耐陰性が高く、比較的光の少ない場所でも育てやすい)」
3. 参照した信頼性の高い情報源
-
Wikipedia「NASA空気清浄研究」
- 概要:NASAが1989年に実施した室内空気清浄に関する研究の詳細
- URL: https://ja.wikipedia.org/wiki/NASA空気清浄研究
-
動物病院関連サイト「犬で中毒を起こす観葉植物」
- 概要:獣医師監修によるペットへの植物毒性の詳細情報
- URL: https://marimo-vet.com/blog/foliage-plant/
-
みんなの趣味の園芸(NHK出版)「ザミオクルカス」
- 概要:ZZプラントの正式な育て方と特性
- URL: https://www.shuminoengei.jp/m-pc/a-page_p_detail/target_plant_code-1373
4. 記事内で注意書きを添えるべきポイント
必須の注意書き
【重要】この記事の情報は一般的なガイドラインです。
・植物の成長や健康状態は、住環境(日照・湿度・温度・風通し)により大きく異なります
・ペットや小さなお子様がいるご家庭では、事前に各植物の毒性について確認してください
・植物の状態や環境により、記載されている以外の対応が必要な場合があります
・心配な症状が現れた場合は、専門家(園芸店・獣医師等)にご相談ください
個別注意事項
- 購入場所について: 「特定の店舗を過度に推奨せず、複数の選択肢を提示」
- 費用について: 「100均グッズ活用は品質面でのリスクも併記」
- 成功体験の個人差: 「同じ方法でも結果が異なることがある旨を明記」
5. 追加で検証が必要な項目
- 各植物の学名の正確性
- 季節ごとのお世話カレンダーの地域差
- 土の選び方に関する最新情報
- 肥料の与えすぎによる具体的な被害事例
Do you want to proceed with the file write? [y/*] y
リサーチ結果をもとに、読者が安心して観葉植物を始められる記事構成案を作成いたしました。
構成のポイント
1. 段階的なアプローチ
- STEP形式で、選び方→基本のお世話→トラブル対処→継続のコツと、読者が実践しやすい順序で構成
2. 不安解消を最優先
- 冒頭で「枯らしてしまうのでは?」という不安に直接アプローチ
- 「完璧でなくても大丈夫」というメッセージを全体に貫く
3. 実践的な情報設計
- 「毎日やること・やらなくていいこと」を明確に区別
- 具体的な判断方法(水やりタイミングの見極め方など)を詳しく解説
4. 安全性への配慮
- ペットや小さな子どもがいる家庭への注意事項を必ず記載
- アレルギーリスクについても言及
5. 継続可能性を重視
- 忙しい現代人でも続けられる「手抜きテクニック」を紹介
- 費用を抑える工夫で経済的負担を軽減
この構成案により、読者は「自分にもできそう」と感じながら、実際に行動に移し、長期的に楽しめる観葉植物ライフを始められるはずです。前の工程で作成されたリサーチ結果、構成案、ファクトチェック結果を確認し、これらを基に最終的なWeb記事を執筆します。
Tool #1: editor
Do you want to proceed with the create operation? [y/*] y
以下が、これまでの工程で得られた情報を基に作成した最終的なWeb記事です:
初心者でも安心!在宅で楽しむ観葉植物の始め方
「観葉植物を育ててみたいけれど、枯らしてしまいそうで不安…」そんな気持ちを抱えている方は多いのではないでしょうか。
実は、観葉植物は思っているほど難しいものではありません。適切な植物を選び、基本的なお世話のコツを覚えるだけで、誰でも緑のある生活を楽しめるようになります。
この記事では、植物初心者の方でも安心して始められる観葉植物の選び方と、毎日無理なく続けられるお手入れ方法をご紹介します。完璧を目指さず、植物と一緒にゆっくり成長していく気持ちで読んでみてください。
STEP1:あなたにぴったりの植物を見つけよう
初心者におすすめ!育てやすい植物5選
まずは、比較的失敗しにくく、お手入れが簡単な植物から始めてみましょう。
1. ポトス
- 水やりの頻度:週1〜2回程度
- 置き場所:明るい日陰〜半日陰
- 特徴:つる性で成長が早く、水挿しでも増やせる
2. サンスベリア
- 水やりの頻度:月1〜2回程度
- 置き場所:明るい場所(直射日光は避ける)
- 特徴:乾燥に非常に強く、NASA研究で空気清浄植物として認定(※実際の効果は環境により異なります)
3. ガジュマル
- 水やりの頻度:週1〜2回程度
- 置き場所:明るい場所
- 特徴:幹の形がユニークで、強健な性質
4. アイビー(ヘデラ)
- 水やりの頻度:週2〜3回程度
- 置き場所:明るい日陰
- 特徴:つる性で垂らして飾れる、涼しい環境を好む
5. ZZプラント(ザミオクルカス)
- 水やりの頻度:月1〜2回程度
- 置き場所:明るい日陰〜やや暗めでも OK
- 特徴:耐陰性が高く、比較的光の少ない場所でも育てやすい
生活環境に合わせた選び方
日当たりが少ない部屋には
- ZZプラント、ポトス、アイビーがおすすめ
乾燥しがちな部屋には
- サンスベリア、ガジュマルが適しています
お手入れ時間があまり取れない方には
- サンスベリア、ZZプラントなど、水やり頻度の少ないものを
購入時のチェックポイント
植物を選ぶ際は、以下の点を確認してみてください。
- 葉の色艶が良く、害虫がついていない
- 茎や幹がしっかりしている
- 土の表面にカビが生えていない
- 鉢底から根が大きく出すぎていない
ホームセンター、園芸店、最近では100円ショップでも購入できますが、初心者の方は専門店で相談しながら選ぶと安心です。
STEP2:毎日の基本お世話術
水やりの基本ルール
観葉植物のお世話で最も大切なのが水やりです。「毎日あげる」のではなく、「植物が欲しがっているタイミング」で与えることがコツです。
水やりのタイミングの見極め方
-
土の表面を指で触る
- 表面が乾いていたら水やりのサイン
- 土が湿っていたらまだ待つ
-
鉢を持ち上げる
- 軽くなっていたら水不足の可能性
- 重いままなら水分は十分
-
葉の状態を観察
- 少ししおれ気味になったらSOSのサイン
水やりの方法
- 鉢底から水が出るまで、たっぷりと与える
- 鉢皿にたまった水は30分後に捨てる
- 常温の水を使用する
置き場所と環境づくり
理想的な環境
- レース越しの明るい場所
- 風通しの良い場所
- エアコンの風が直接当たらない場所
- 室温15〜25℃程度
季節による調整
- 春・夏:成長期なので水やり頻度を少し増やす
- 秋・冬:休眠期なので水やりは控えめに
やってはいけないNG行動
- 毎日の水やり(根腐れの原因)
- 受け皿に水を溜めっぱなし
- 直射日光に急に当てる
- 冷たい水での水やり
- 葉に水をかけすぎる(夜間は特に注意)
STEP3:トラブル時の対処法
よくある困りごとと解決方法
葉が黄色くなってきた
- 原因:水のやりすぎ、根詰まり、自然な老化
- 対処:水やりを控え、黄色い葉は取り除く
葉がしおれている
- 原因:水不足、根腐れ、環境の急激な変化
- 対処:土の状態を確認し、適切な水やりを行う
虫がついた
- 対処:害虫を取り除き、風通しを良くする
- 予防:葉の裏も定期的にチェック
成長が止まった
- 原因:鉢が小さくなった、栄養不足、季節的な休眠
- 対処:春に一回り大きな鉢に植え替えを検討
STEP4:長く楽しむためのコツ
忙しい時でも続けられる「手抜き」テクニック
旅行や出張時の対策
- 事前にたっぷり水やりをし、明るい日陰に移動
- ペットボトルを使った自動給水器の活用
- 信頼できる人に水やりをお願い
お手入れが面倒な時期の乗り切り方
- 「完璧でなくても大丈夫」と割り切る
- 最低限の水やりだけでも継続
- 植物の様子を見て「頑張って生きている」ことを実感する
費用を抑える工夫
100円ショップの活用
- 霧吹き、受け皿などの基本用品
- 小さな鉢やプランター(※品質面でのリスクもあるため、大切な植物には園芸店のものを推奨)
手作りアイテム
- ペットボトルでの自動給水器
- 牛乳パックでの育苗ポット
より楽しむための応用編
飾り方のアイデア
空間を有効活用
- つる性植物は高い場所から垂らして
- 小さな植物はデスクや棚の上に
- 大きな植物はお部屋の角にアクセントとして
インテリアとの調和
- 鉢カバーでお部屋の雰囲気に合わせる
- 複数の植物でミニジャングルを作る
成長を楽しもう
植物との生活で一番の魅力は、日々の変化を感じられることです。新しい芽が出た時、葉が大きくなった時の喜びは格別です。
写真を撮って成長記録をつけたり、家族や友人と植物の話をしたりすることで、より愛着が深まるでしょう。
安全に楽しむための注意点
ペットや小さなお子様がいるご家庭へ
一部の観葉植物は、ペットや小さなお子様が誤って口にすると健康に影響を与える場合があります。
毒性の可能性がある植物
- ポトス:犬・猫には有毒(誤食により嘔吐・下痢等の症状)
- アイビー:犬・猫には有毒
- サンスベリア:軽微な毒性あり
- ZZプラント:軽微な毒性あり
安全のための対策
- 手の届かない場所に配置する
- 落ちた葉はすぐに片付ける
- 心配な症状が現れた場合は、専門家(獣医師等)に相談
アレルギーについて
植物の樹液や花粉でアレルギー症状が出る場合があります。植物に触れた後は手を洗い、異常を感じたら使用を中止してください。
まとめ:植物と一緒に成長していこう
観葉植物との生活は、完璧を目指すものではありません。時には失敗することもありますが、それも含めて楽しみながら、植物と一緒に成長していく過程こそが魅力です。
今日から始められる3つのステップ
- 植物を一つ選んで購入:まずは育てやすいものから
- 置き場所を決める:明るい日陰で風通しの良い場所
- 水やりの習慣づくり:土の状態を確認してから
小さな一歩から始めて、緑のある暮らしを楽しんでください。植物があることで、お部屋の空気が変わり、毎日の生活にちょっとした彩りが加わるはずです。
【重要】この記事について
この記事の情報は一般的なガイドラインです。植物の成長や健康状態は、住環境(日照・湿度・温度・風通し)により大きく異なります。ペットや小さなお子様がいるご家庭では、事前に各植物の毒性について確認してください。心配な症状が現れた場合は、専門家(園芸店・獣医師等)にご相談ください。
実行ステータス: Status.COMPLETED
実行順序: ['research', 'fact_check', 'analysis', 'report']
想定した通り、researchの叩き台にfact_checkやanalysisがツッコミを入れてreporterがいい感じに記事にしてくれました!
まとめ
この記事では、Strands Agents でマルチエージェントを実装する4つの方法を俯瞰しました。
中央のエージェントが全体を統括して専門特化エージェントにタスクを振っていく Agents As Tools は、ユーザーには単一の対話体験を提供しつつ、裏では複数専門家を動かしたいタスクに向いているでしょう。例えば、アーキテクチャを評価する Architect Agent、コスト・キャパシティを見積もる Cost Agent、セキュリティ・コンプライアンスをチェックする Security Agentをそれぞれツール化すれば、エンジニアがサービスを実装するときの多方面からの評価を一括して実施できます。
Swarm は、中央のオーケストレータはあくまで不在で、専門特化エージェントがそれぞれタスクを好きなエージェントにハンドオフしながら目的を達成します。従って、例えば多視点から案を叩きたいが、レビューの順番まで設計したくないタスクに向いています。また、エージェント同士が対話を積み重ねる中で全体として個々の要素の総和に還元できないような振る舞いである「創発」を期待したい場合にも使える可能性があります。例えば、新商品の企画を様々な視点を持ったエージェントに叩かせながら作り上げ、アイデアを創出していくようなプロセスに応用できます。
Graph は、専門特化型エージェントがそれぞれ繋がる先を限定しつつも、能動的な判断によってタスクの受け渡しを制御する自立性を持ったモデルでした。条件分岐やループを含む実行パスを「グラフ構造」として管理できるため、例えば「セキュリティチェックで NG なら設計ステップに戻す」などのループも明示的な指示なしに表現でき、対話的なフローでも再現性と説明可能性を維持できます。従って、例えばシステム開発の現場で、要件整理 Agent(ビジネス要件・非機能要件の構造化)アーキ検討 Agent(構成案の作成)、セキュリティレビュー Agent、コスト・リソース検討 Agent、リスク・承認 Agentをノードとして登録することで、「一定規模以上なら詳細セキュリティレビューへ」、「NG の場合はアーキ検討ステップに戻す」といったある意味では企業における業務フローに近しい形で実務をモデリングするために役に立つと考えられます。
最後に workflow は、タスクとその依存関係を定義することで、各タスクの処理はエージェントが実装するものの、タスクを決定的な順序で実行することができます。会話性よりも“安定実行・再現性・運用”を重視するパターンと言えるため標準化された社内オペレーションの自動化には最も向いていると言えるでしょう。従って、例えば、家計簿アプリやクレカ明細を整理する Aggregator Agent、カテゴリ別の傾向や異常値を分析する Household Analyst Agent、「来月の予算案と改善提案」を出す Planner Agentをワークフローとして組み、毎月末に自動実行してレポートを生成することで、「月次の家計振り返り」を自動化することなどができると思われます。
そして、さらに言えばこれらのマルチエージェントの実装は組み合わせて使うこともでき、そのようにすることでさらに複雑な業務をモデル化できる可能性もあります。例えば、あるシステム開発会社で新製品の開発からサービスインまでの流れが
マーケットリサーチ→新製品企画会議→収益性会議→役員による承認→要件定義→基本設計→詳細設計→実装→テスト→デプロイ→運用保守
となっている時、全体の流れをワークフローで組みつつ、新製品企画会議はSwarm、要件定義にはgraphといった形で各エージェントを組み合わせていくことで、一連の業務フローを完全にエージェントに置き換える....といったことも将来的にはあり得るのではないでしょうか。
この記事が皆様のマルチエージェントへの理解の一助になれば幸いです!それでは!

この Publication に投稿している記事は、アマゾン ウェブ サービス ジャパン合同会社または Amazon Web Services, Inc. 所属社員による個人の見解であり、所属する組織の公式見解ではありません。参加したい従業員の方は、Sugiyama Suguru までお知らせください。
Discussion