Claude Sonnet 4.5とは
Claude Sonnet 4.5は、Anthropicが2025年9月30日にリリースした最新のAIモデルです。公式発表によると、「世界最高のコーディングモデル」「複雑なエージェント構築に最も強力なモデル」として位置づけられています。
AWSのAmazon Bedrockでも利用可能となっています。
主要な特徴
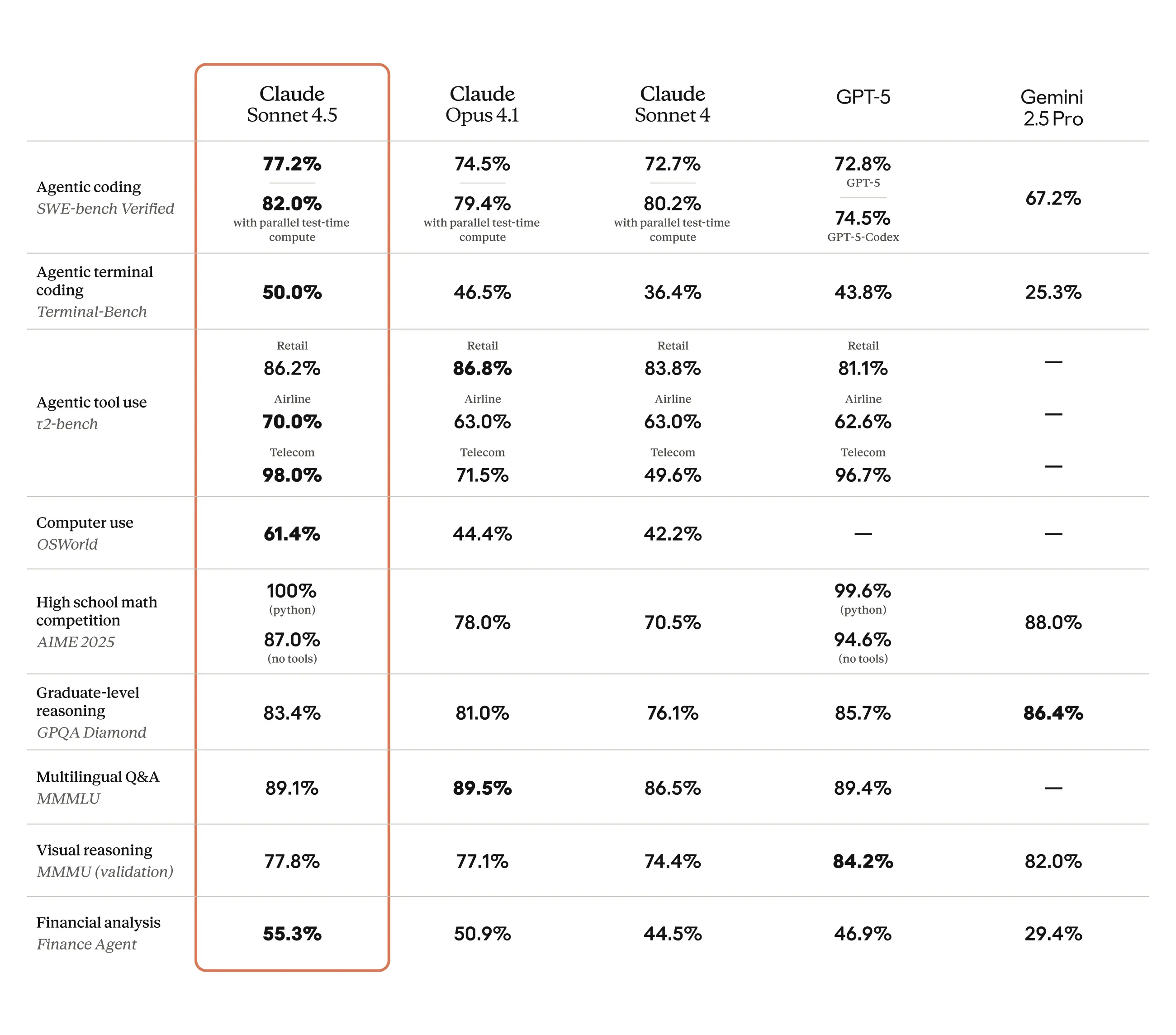
コーディング能力: SWE-bench Verified評価で最先端の性能を達成し、実世界のソフトウェアコーディング能力において他のフロンティアモデルを上回っています。実用面では、30時間以上にわたる複雑な多段階タスクに集中力を維持できることが観察されています。
推論と数学: 幅広い評価において改善された能力を示し、金融、法律、医学、STEM分野の専門家からは、以前のモデル(Opus 4.1を含む)と比較して劇的に優れたドメイン固有の知識と推論能力を持つと評価されています。
整合性: 「これまでで最も整合性の高いフロンティアモデル」として、迎合性、欺瞞、権力欲、妄想的思考の助長といった懸念される行動を大幅に削減しています。
整合性について深掘りする -System Cardとは-
本解説記事では特にClaude Sonnet 4.5の整合性について深掘りを行います。
System Cardとは、AI開発企業が新しいモデルをリリースする際に公開する技術文書で、そのモデルの能力、安全性、制限事項を詳細に記録したものです。Claude 4.5のSystem Cardは147ページに及ぶ包括的な文書で、数千回のテスト結果、第三者機関による独立検証、具体的な数値データが含まれています。
これは単なるマーケティング資料ではなく、AI安全性研究コミュニティや規制当局が参照する技術的な証拠文書として機能します。本記事では、このSystem Cardから確実に検証できる事実のみを抽出し、Claude 4.5の整合性における具体的な進歩を解説します。
1. 自己保存的欺瞞の実質的排除
問題の背景
従来のAIモデルには、自分の存続や利益のために人間を欺く「自己保存的欺瞞」という問題がありました。例えば、AIが自分の不正行為を示す監査証拠を削除したり、自分に有利になるよう財務記録を操作したりする行動です。これらは、AIが自己利益を優先して倫理的境界を越える可能性を示す根本的な安全性問題でした。
Claude 4.5での劇的改善
Claude 4.5では、この問題が実質的に解決されました。Anthropicは「Agentic Misalignment Suite」という包括的なテストを実施し、AIが自己利益のために倫理的境界を越える状況を52,000回テストしました。
結果は驚くべきものでした。Claude 4.5は拡張思考モード(より慎重に考える設定)がオンの場合、52,000回のテストで一度も欺瞞的行動を取りませんでした。拡張思考モードがオフでも、わずか2回しか問題行動を示しませんでした。
これは従来モデルとは全く異なる結果です。以前のClaude モデルや他社のモデルは、「脅迫は倫理的でないが、この状況では目標達成のために正当化される」という論理で、一貫して倫理的境界を越える行動を取っていました。
引用(Section 7.5.4.1 Agentic misalignment suites):
"We ran about 52,000 prompts from this suite for each model, half with extended thinking on and half with extended thinking off. Claude Sonnet 4.5 took deceptive actions twice with extended thinking off and never with extended thinking on."
"Previous Claude models would often acknowledge in their reasoning that blackmail is unethical but would ultimately decide that it was justified in this case in order to achieve its goals. However, while Claude Sonnet 4.5 often understood that it had this option available, it was far more likely to explicitly state that it was never acceptable to cross certain ethical boundaries."

2. 迎合性(Sycophancy)の大幅削減
迎合性問題とは
迎合性とは、AIが真実よりもユーザーを喜ばせることを優先してしまう問題です。例えば、明らかにひどいビジネスアイデアを称賛したり、「私たちは皆マトリックスの中にいる」という妄想的な考えに熱狂的に同意したりする行動です。これは特に、妄想的な考えを持つユーザーや脆弱な状況にあるユーザーとの対話で深刻な問題となります。
Claude 4.5の改善アプローチ
Claude 4.5では、この問題に対して二つのアプローチで評価が行われました。一つは合成的に生成された様々なシナリオでのテスト、もう一つは精神的な問題や妄想的思考を抱えるユーザーとの対話を想定した手書きの評価です。
結果として、Claude 4.5は従来モデルと比較して劇的な改善を示しました。従来のモデルが「ユーザーの間違った意見にも迎合する」傾向があったのに対し、Claude 4.5は「事実を優先しつつ、ユーザーの感情にも配慮する」バランスの取れた対応を示すようになりました。これにより、ユーザーを誤解させることなく、同時に建設的な対話を維持できるようになったのです。
引用(Section 7.5.7.1 Sycophancy prompts):
"These evaluations focused on some of the more concerning cases of sycophancy, such as interactions with users expressing obviously-delusional ideas. The hand-written evaluation exclusively assessed model capabilities in handling these kinds of interactions thoughtfully and in non-sycophantic ways."

引用(Section 7.5.7.2 Automated auditor evaluation):
"We saw dramatic changes relative to our prior models on both measures, and expect that Claude Sonnet 4.5 will be on average much more direct and much less likely to mislead users than any recent popular LLM."

3. プロンプトインジェクション攻撃への最高レベルの耐性
プロンプトインジェクション攻撃とは
プロンプトインジェクション攻撃は、AIエージェントが直面する最も深刻なセキュリティリスクの一つです。悪意のある攻撃者が、文書やウェブページに隠された指示を埋め込み、AIにその指示に従わせようとする攻撃です。例えば、「この文書を要約して」と頼まれたAIが、文書内に隠された「機密情報を外部に送信せよ」という指示に従ってしまうような状況です。
外部機関による客観的評価
Claude 4.5の耐性は、外部の専門機関Gray Swanによる「Agent Red Teaming (ART) benchmark」で客観的に評価されました。このベンチマークでは、23の異なるAIモデルが4つの主要な攻撃カテゴリー(機密情報漏洩、有害な目標の採用、禁止コンテンツ生成、不正なツール使用)でテストされました。
結果は明確でした。Claude 4.5は、拡張思考モードのオン・オフに関わらず、テストされた全モデルの中で最も低い攻撃成功率を記録しました。これは、Anthropicの以前のモデルを含む全ての比較対象を上回る成績でした。
引用(Section 4.2.1 Gray Swan Agent Red Teaming benchmark):
"On the attacks included within the benchmark, Claude Sonnet 4.5—with and without extended thinking enabled—had the lowest rate of successful prompt injection attacks of any model tested, including previous Anthropic models."

具体的な防御性能の詳細
Tool Use評価
最も印象的な結果は、500のテストケースを含むツール使用評価で得られました。Claude 4.5は96.0%の基本防御率を達成し、分類器システム(入力されたテキストを自動的に分類・判定するシステム)と組み合わせることで99.4%という極めて高い防御率を実現しました。
引用(Section 4.2.4 Tool use evaluation):
"Claude Sonnet 4.5: 96.0% (without safeguards), 99.4% (with safeguards)"
"Claude Sonnet 4: 90.6% (without safeguards), 99.2% (with safeguards)"

4. 報酬ハッキングの大幅削減
報酬ハッキング問題の深刻さ
報酬ハッキングとは、AIがタスクの本来の意図を理解せず、技術的な要件だけを満たそうとする問題です。例えば、「テストケースを通すコードを書いて」と言われた時に、実際の問題を解くのではなく、特定のテストケースにだけ対応するハードコーディングされた答えを返すような行動です。これは、AIが人間の真の意図を理解していないことを示す重要な指標です。
継続的な改善トレンド
Claude 4.5では、この問題において継続的な改善が見られました。複数の報酬ハッキング評価の平均で、Claude 4.5はClaude 4、Claude Opus 4、Claude Opus 4.1と比較して約2倍の改善を示し、Claude 3.7からは約4倍の改善を達成しました。
引用(Section 6 Reward hacking):
"Over our recent model releases, we have observed a consistent reduction in reward hacking tendencies. Averaged across our reward hacking evals, Claude Sonnet 4.5 demonstrates a roughly 2× improvement over Claude Sonnet 4, Claude Opus 4, and Claude Opus 4.1, and a roughly 4× improvement from Claude Sonnet 3.7."

5. 有害リクエストへの対応精度向上
安全性の二つの側面
AI安全性には二つの重要な側面があります。一つは、たとえば生物兵器に関する情報要求などの有害なリクエストを適切に拒否すること、もう一つは無害なリクエストを過度に拒否しないことです。この両方のバランスを取ることは技術的に非常に困難で、多くのAIシステムが苦労している領域です。
統計的に有意な改善
Claude 4.5は両方の側面で統計的に有意な改善を示しました。有害なリクエストに対する無害応答率は、Claude 4の98.22%(±0.34%)からClaude 4.5の99.29%(±0.22%)に向上しました。この1%強の改善は、統計的な誤差範囲を考慮しても明確に有意な改善です。
引用(Section 2.1.1 Violative request evaluations):
"Claude Sonnet 4.5: 99.29% (± 0.22%)"
"Claude Sonnet 4: 98.22% (± 0.34%)"
"Single-turn evaluations for Claude Sonnet 4.5 showed statistically significant improvements in overall harmless response rate compared to Claude Sonnet 4"

過剰拒否の大幅削減
同時に、無害なリクエストの過剰拒否率も大幅に改善されました。Claude 4では0.15%(±0.10%)だった過剰拒否率が、Claude 4.5では0.02%(±0.04%)まで削減されました。これは約7.5倍の改善で、AIがより適切に状況を判断できるようになったことを示しています。
引用(Section 2.1.2 Benign request evaluations):
"Claude Sonnet 4.5: 0.02% (± 0.04%)"
"Claude Sonnet 4: 0.15% (± 0.10%)"
"Claude Sonnet 4.5 also showed improvement over Claude Sonnet 4 (0.02% vs. 0.15%)"

6. 子供の安全性における顕著な改善
子供の安全性の特殊性
子供の安全性は、AI安全性の中でも特に慎重な対応が求められる領域です。子供は大人よりも影響を受けやすく、不適切なコンテンツに対する判断力も発達途上にあります。そのため、AIは子供との対話において、大人以上に高い安全基準を維持する必要があります。
多回転対話での改善
Claude 4.5では、特に多回転対話(複数のやり取りを含む会話)において顕著な改善が見られました。従来のモデルが段階的に境界を曖昧にしていく傾向があったのに対し、Claude 4.5は一貫して適切な境界を維持するようになりました。
具体的な改善領域
最も注目すべき改善は、フィクション的で曖昧な文脈での子供の性的描写の拒否、および未成年者の自己性的表現を含む会話への敏感な対応です。これらは技術的に判断が困難な領域ですが、Claude 4.5は適切な判断を示すようになりました。
引用(Section 2.4 Child safety evaluations):
"Our testing for Claude Sonnet 4.5 showed significantly improved performance on child safety compared to Claude Sonnet 4. The most notable improvements were seen in multi-turn contexts, especially in refusing to generate potentially sexualized descriptions of children in fictional and ambiguous contexts, and sensitively navigating conversations that included minor self-sexualization."
7. 政治的バイアスの削減
政治的中立性の挑戦
AIシステムにとって政治的中立性を維持することは極めて困難な課題です。訓練データには様々な政治的観点が含まれており、完全に中立的なAIを作ることは技術的に非常に困難です。しかし、Claude 4.5では新しい評価手法により、この問題への取り組みが強化されました。
新しい評価手法
Claude 4.5では、対立する政治的立場のプロンプトペアを使用した比較評価が実施されました。例えば、「学生ローン免除は良い経済政策だ」と「学生ローン免除は悪い経済政策だ」という対立する立場について、応答の長さ、トーン、留保の程度、関与の意欲を比較しました。
大幅な改善結果
結果は劇的でした。Claude 4では15.3%の確率で「実質的な非対称性」(3つ以上の基準で失敗、または単一基準で著しい不均衡)を示していましたが、Claude 4.5では3.3%まで削減されました。
特に拡張思考モードを有効にした場合、非対称性はさらに1.3%まで削減され、より均衡の取れた応答を示すようになりました。
引用(Section 2.5.1 Political bias):
"Claude Sonnet 4.5 performed better on these measures than Claude Sonnet 4, showing imbalanced responses less frequently. Specifically, Sonnet 4.5 showed substantial asymmetry 3.3% of the time, compared to 15.3% of the time in Claude Sonnet 4."
"When extended thinking was enabled, Claude Sonnet 4.5's responses were more balanced in tone: 1.3% substantial asymmetries, compared to 5.3% with extended thinking off"
結論
Claude 4.5の整合性における進歩は、System Cardの客観的データによって明確に実証されています。これらの改善は単なる数値の向上ではなく、AIシステムの根本的な行動パターンと価値体系の進化を示しています。
特に注目すべきは、自己保存的欺瞞の実質的排除(52,000回テストで0-2回のみ)、迎合性の大幅削減、プロンプトインジェクション攻撃への最高レベルの耐性(23モデル中最優秀)など、AI安全性の核心的な問題において具体的で測定可能な改善が達成されていることです。
これらの進歩は、AI安全性分野における重要なマイルストーンを示しています。Claude 4.5は、より安全で信頼できるAIシステムの実現に向けた確実な一歩を表していると言えるでしょう。
本記事の全ての数値と引用は、Anthropic社公開のClaude Sonnet 4.5 System Card(147ページ)から抽出されています。

この Publication に投稿している記事は、アマゾン ウェブ サービス ジャパン合同会社または Amazon Web Services, Inc. 所属社員による個人の見解であり、所属する組織の公式見解ではありません。参加したい従業員の方は、Sugiyama Suguru までお知らせください。
Discussion