論文解説|SVDiff: Compact Parameter Space for Diffusion Fine-Tuning




SVDiff: Compact Parameter Space for Diffusion Fine-Tuning

はじめに
この論文はstable Diffusion[1]を効率的にfine-tuningする方法を提案しています。
最近話題の拡散モデルは、テキストから高品質な画像を生成できますが、モデルをfine-tuningする際には限界があり、多くのパラメータを持つためモデルの保存が非効率です。本論文では、重み行列の特異値のみを再学習することで、過学習と言語の摂動による悪影響を減らし、よりコンパクトで効率的なパラメータ空間を実現する新しいアプローチを提案しています。さらに、複数の被写体の画像生成の品質を向上させるために、Cut-Mix-Unmixというデータ拡張技術と、シンプルなテキストベースの画像編集フレームワークも提案されています。
また上の画像のように複数の画像からスタイルを選択できるようです。(画像の一番上は形とスタイルをカオナシとクマに変更している。)
事前知識
拡散モデルの基礎として、Stable Diffusion[1]というモデルが使用されています。stable diffusionについてはまた今度記事にまとめたいと思います。
高解像度な画像を生成できるStableDiffusionですが、筆者曰く複数の概念を同時に学習させたときにスタイルが混在してしまう問題があるようです。
下の図では、入力画像

また、本論文ではFSGAN[2]の手法を使って学習を効率よく行っています。
詳しくはこちらをご覧ください。
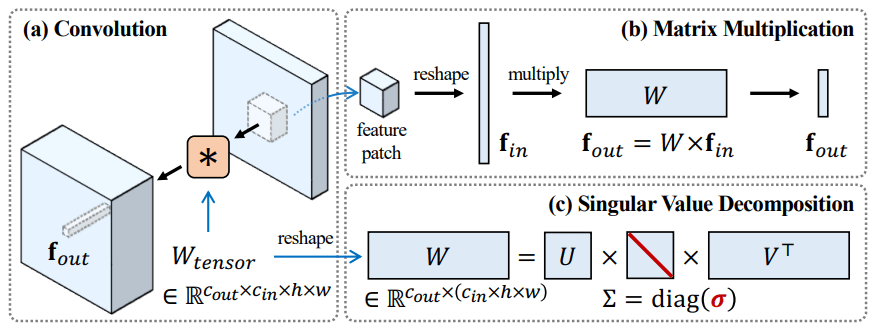
簡単に解説をすると、モデルの重みに特異値分解(SVD)を行い、特異値のみを学習するという手法です。このようにすることでモデルの大体の特性を保持しつつ細かい特性をfine-tuningできるようです。
さらにNaviGAN[3]ではこのパラメータ空間(特異値のこと)における意味的な方向性を発見したようです。これも記事として書きたいですね…。
提案手法
提案されたSVDiff手法は2つあります。
- FSGAN[2]の特異値学習を用いた効率的なfine-tuning(スペクトラルシフト)。
- Cut-Mix-Unmixでdata augmentationを行い、複数の画像を入力した際にスタイルを混在させてしまう問題を解決。
- 単一画像を簡単に編集できるCoSINE(Compact parameter space for SINgle image Editing)というフレームワークを提案。これにより直感的なテキストプロンプトで思い通りの画像が生成可能になります。
スペクトラルシフト
スペクトラルシフトはNaviGAN[3]とほぼ同じです。まず、モデルの重み
ここで
そして
FSGAN[2]では特異値にスカラー
本当は詳しい理論があります。詳細は論文をご覧ください…。
スペクトラルシフトのすごいところは他で学習したスペクトラルシフトを組み合わせることができるところです。下の画像では特異値分解(SVD)を用いて"dog"や"sculpture"を学習した
SVDの行はスペクトラルシフトを使用した場合、Fullは使用せずに重み全体を学習した際の可視化です。

Cut-Mix-Unmix
Cut-Mix-Unmixは複数の概念(例えば異なる被写体)を同時に学習する際に、モデルがそれらのスタイルを混在させるのを防ぐことを目的としています。
手法の概要を下の図に示します。手法はCut-Mixをベースとしています。画像内の"Target Images"が今回学習させたい画像で、"Prior Images"が以前に学習した画像です。
手順は以下の通りです。
- 2つの画像のCut-mixを行います(通常のCut-Mixように一部分とかではなく、2つの画像を左右に合体させる)。
- その画像にあったテキストプロンプトを生成します。
- テキストと画像のAttention mapをそれぞれ同一のものに注視するように制御します。画像にはラベルとして"dog"や"panda"などのクラスがあります。それを利用し"panda"のテキストにはパンダ以外の画像領域に注意がいかないように制限します。
このようにAttention mapを制限することによって他の画像に注意がいかなくなり、各画像の影響を受けにくくなります。そのため複数の概念のスタイルを混在させないようにできます。

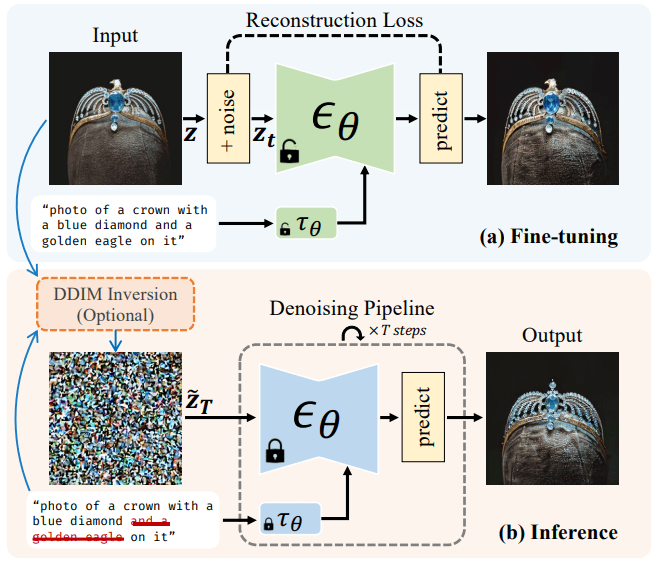
CoSINE(Compact parameter space for SINgle image Editing)
今やプロンプトエンジニアなどの職業があるように、テキストプロンプトの設定は難しいです。この論文では変換したい画像が用意できればそれを簡単に変換できるフレームワークを提案してます。下画像の例では鷲の王冠の"鷲"というスタイルを削除しています。手法は簡単で、まず変換したい画像をスペクトラルシフトを用いて学習します。その後、新しいテキストプロンプトと入力画像を潜在空間に変換し、学習されたdiffusionを用いて生成します。すると生成された画像は新しいテキストプロンプトを正しく反映できるようになります。あまりプロンプトによる画像変化のない場合はこれだけでうまく生成できますが、大きな変化の場合はノイズの摂動を大きくするように球面線形補間[4]という補正を行うようです。
実験結果
実験結果では定性評価が主にされており全部紹介すると、とても量が多くなってしまいますので一部抜粋して紹介します。
下の画像はCut-Mix-Unimixの定性評価です。(g)の画像が一番わかりやすいと思います。w/o Cut-Mix-Unimixでは犬とパンダが一体化していますが、提案手法を使えばちゃんとそれぞれが固有のスタイルを維持したまま生成ができます。

下の画像ではCoSINEの評価を行っています。画像上段の右から二番目がわかりやすいでしょうか。犬の伏せをさせるようなプロンプトに変更していますが、Full(全体学習)では立ったままになっており提案手法ではちゃんと伏せをしています。

他にも面白い画像があるのでぜひ論文をお読みください!
まとめと感想
SVDiffは、拡散モデルの微調整において、コンパクトなパラメータ空間スペクトラルシフトを提案しました。またCut-Mix-Unmixというデータ拡張技術も提案しており、複数画像のスタイル混在の問題を解決しています。diffusionの論文を読んでいると定性評価ばかりで少し評価が難しいなと感じました。(なんとも言えない画像が結構あった。)ただ、簡単に画像を変換できるCoSINEは結構面白いのではないかと思いました。僕は普段異常検知をやっているので疑似異常生成など他の分野にも応用できそうだなと感じました。
6. 論文のリクエスト
解説してほしい論文のリクエストを受け付けています!
リクエストから2週間程度で記事を作成したします。
どなたでもお気軽にリクエストしてください!
参考文献
[1]
Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
[2]
Robb, Esther, et al. "Few-shot adaptation of generative adversarial networks." arXiv preprint arXiv:2010.11943 (2020).
[3]
Cherepkov, Anton, Andrey Voynov, and Artem Babenko. "Navigating the gan parameter space for semantic image editing." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
[4]
Song, Jiaming, Chenlin Meng, and Stefano Ermon. "Denoising diffusion implicit models." arXiv preprint arXiv:2010.02502 (2020).
Discussion