論文解説|LinkGAN: Linking GAN Latents to Pixels for Controllable...



LinkGAN: Linking GAN Latents to Pixels for Controllable Image Synthesis
1. はじめに

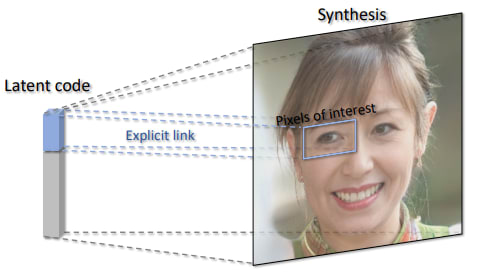
本論文は、生成敵対ネットワーク(GAN)[1]の訓練において、潜在空間の特定の軸を合成画像の特定の部分にリンクさせるフレームワークを提案しています。上の画像のように目にリンクさせた潜在ベクトルをいじるとその部分の画像を変換できます。近年はStable Diffusionの登場であまりGANが注目されていませんが、GANは潜在空間と生成画像の結びつきがより明示的なのでDiffusionよりも簡単に制御できるというものです。
2. 事前知識
2.1 GAN[1]
GANの構造については既に知っているという前提で解説します。
一応GANの解説に関するおすすめ記事を載せておきます。
初学者向け記事(数式なし)
中級者向け記事(損失関数メイン)
2.2 StyleGAN[2]
StyleGANは2018年に発表された当時非常に高解像度に画像を生成できるモデルです。従来のGANと最も違う部分は潜在変数をそのまま画像として使うのではなく、生成画像のスタイルとして使用するところです。下画像に従来のGAN(Traditional)とStyleGAN(Style-based generator)の概要を示しています。正規分布から生成された
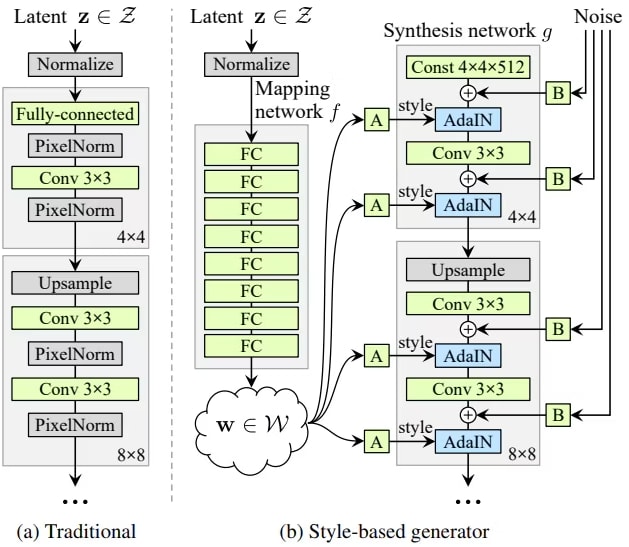
StyleGANから引用
詳しい解説はこの記事がおすすめです。
2.3 LDBR[3]
こちらの論文はGANの潜在空間を生成画像とリンクさせるSpatially Stochastic Networks(SSNs)という手法を提案しています。GANにおいて局所的な部分を変えると全体の画像の一貫性が失われるという問題点があります。そこでLDBRではSSNsというモジュールを追加することによって全体に与える影響を少なくする正則化を行っています。
この変更部分の悪影響を他の部分に与えないという考え方は本論文でも使用されています。
3. 提案手法
この論文ではLinkGANという潜在空間の特定の箇所を生成画像の特定の部分とリンクさせ、簡単に編集できるフレームワークを提案しています。
LinkGANの手法は非常に簡単でLDBRのように複雑なモジュールは必要なく、StyleGANを使うだけでうまくいくようです。
StyleGANのジェネレーターを
変更したい部分の潜在ベクトルを
生成画像
次に、摂動を起こすために潜在ベクトル
変更したくない部分に摂動を加えた生成画像
これらの摂動部分を変えた画像を用いてLinkGANは学習を以下のように行います。
ここで
このような単純な構造によって局所的に潜在ベクトルを変更しても他の領域は変わらない事を保証しています。実装コードがないので詳細は分かりませんが、論文だけみると画像を変更するたびに再度学習をし直す必要はなさそうです。
4. 実験結果
GAN系の実験結果は画像が多いので今回はそれを抜粋して紹介します。

上の画像はオリジナルの画像の赤い四角で囲まれた部分を変更したIn-Regionとそれ以外の部分を変更したOut-Regionを示しています。またその時の画素の変化量を示した物がヒートマップになっています。これを見ると確かに変更したい部分だけを変更できており、編集能力が高いことが分かります。

また、上の画像のようにbboxではなくセグメンテーションマスクを適用できるので活用の幅は広いのではないかと思います。

あとはモデルによっては3Dも生成できるのでモデリングの際の仕様変更にも強いかもしれません。
5. まとめと感想
LinkGANは、2Dおよび3D GANモデルの空間的制御性を向上させることができるフレームワークを提案しています。従来法よりも単純な方法で精度向上を達成しており、簡単に実装できるそうです。実装コードが待ち遠しいですね。最近はDiffusionが非常に多いですがGANの研究も面白いため解説してみました。今のところ局所的変更が簡単にできるのはGANの強み(多分diffusionでもできる)ですので使い分けて行くのがいいのかなと思いました。
6. 論文のリクエスト
解説してほしい論文のリクエストを受け付けています!
リクエストから2週間程度で記事を作成したします。
どなたでもお気軽にリクエストしてください!
参考文献
[1]
Goodfellow, Ian, et al. "Generative adversarial nets." Advances in neural information processing systems 27 (2014).
[2]
Karras, Tero, Samuli Laine, and Timo Aila. "A style-based generator architecture for generative adversarial networks." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
[3]
Hong, Sarah, et al. "Low distortion block-resampling with spatially stochastic networks." Advances in Neural Information Processing Systems 33 (2020): 4441-4452.
Discussion