[Tableau Certified Data Analyst試験に向けて] 多対多で結びつくディメンションをまたいでフィルタを適用させる方

はじめに
こんにちは。Rakutenでデータエンジニアをやっています。Tableau Certified Data Analyst試験の対策を行なう過程ではLOD計算が避けられません。
そのLOD計算の活用例として,タイトルのような,多対多で結びつくディメンションをまたいだフィルタリングが挙げられます。この表現ですべてを表せているとは思いませんが,たとえば以下のようなケースで,本記事の方法が活用できると考えています。
- ディメンションAが
[Person],ディメンションBが[Movie]だとして,これらの関係は,個々人が鑑賞した映画だとします。このとき,[Movie]から選択した特定の作品を鑑賞した[Person]に限定してフィルタリングしたいとき - ディメンションAが
[Department],ディメンションBが[Employee]だとして,これらの関係は,各社員が所属する部署だとします。このとき,[Employee]から選択された特定の社員が所属する[Department]に限定してフィルタリングしたいとき - ディメンションAが
[顧客名],ディメンションBが[製品名]だとして,これらの関係は,購入された製品と購入した顧客だとします。このとき,[製品名]から選択された特定の製品を購入した顧客に限定して,他のどんな製品を購入しているかを調べたいとき
つまり,ダッシュボード上の操作で選択するディメンションとフィルタリングしたいディメンションが異なるケースです。これを解決するには複数のやり方があります。それについて書こうと思います。
環境
- Mac Ventura 13.6 (Apple M1)
- Tableau Desktop v2024.2.0
方向性と下準備
ダッシュボード上の操作でディメンションを選択するのは,パラメータもしくはセットを使用します。また,ディメンションのフィルタリングには,FIXED計算を使用します。
また,サンプルの演算には,サンプル - スーパーストアを使用します。対象とする2つのディメンションは,上の3つ目の例に書いた通り,[製品名]と[顧客名]を使用しましょう。
計算フィールドのテンプレート
パラメータを使う場合
ディメンションBから作成するパラメータを使って特定の値を選択するようにし,それに関係するディメンションAをフィルタリングするためには,fn1のような計算フィールドを使います。
仕組みは,IF文の中身で,パラメータによって選択されているディメンションBのいち要素だけ,その名前を返すようにします。それをCOUNTD(~)で数えています。つまり,この場合COUNTD(~)は1か0を返します。
それを,ディメンションA単位でFIXEDして数えるので,ディメンションAのある要素と関係する(複数のレコードにまたがることになる)ディメンションBの要素のうち,パラメータで選択されている要素があれば,そのディメンションAのある要素に関してこのBoolean型データはTRUEを返します。
これをフィルターカードとして使えば,あくまでディメンションAでのフィルタリングになります。
// fn1
{FIXED [DimA]:
COUNTD(
IF [ParamB] = [DimB]
THEN [DimB]
END
)
} > 0
この計算式を使って例を図示してみると,次の画像のようになります。ディメンションBの各要素からパラメータで「x」を選択したケースです。

セットを使う場合
同様に,セットを使う場合は以下の通りです。
仕組みとしては上記と同じですが,ディメンションBから複数要素を選択するので,名称の重複がある場合はID列を代わりにカウントするようにします。
複数要素を選択する場合,関係性の度合いに色が出ます。たとえば,ディメンションB(e.g. [製品名])から3要素選択したとき,ディメンションA(e.g. [顧客名])のある要素A1はそのうち2つに関係し(e.g. 購入し)ている一方,別のディメンションAのある要素A2は1つだけに関係している,というように。この2や1という数値がFIXED関数の出力なので,もしひとつでも関係しているディメンションAをフィルタしたければ,下のように,Booleanの判定は> 0としましょう。
// fn2
{FIXED [DimA]:
COUNTD(
IF [SetB] // "[DimB] IN [SetB]" でも可
THEN [DimB] // 重複があるようなら[DimB_id]に置き換えるとよい
END
)
} > 0
もし,選択したディメンションBの要素群ともっとも関係性が高いディメンションAの要素だけにフィルタリングしたい場合は,下のように設定するfn3という計算フィールドを使って,fn4のような計算フィールドを作成しましょう。もし,2つ目の計算フィールドがうまくカードとして使えないときは,fn3を使わずひとつの計算フィールド内で統合したものを書けばうまくいくかもしれません。
// fn3
{FIXED [DimA]:
COUNTD(
IF [SetB] // "[DimB] IN [SetB]" でも可
THEN [DimB] // 重複があるようなら[DimB_id]に置き換えるとよい
END
)
}
// fn4
[fn3] = {MAX([fn3])}
また,セットで選択した要素の数は次の計算フィールドで計算できます。fn3のFIXED後に宣言する[DimA]を除いた形です。これでテーブル全体で要素数をカウントできます。fn3がこれと等しいかどうかをBoolean型で判断すれば,選択したディメンションBの複数要素のすべてと関係するディメンションAでフィルタリングできます。
// fn5
{COUNTD(
IF [SetB]
THEN [DimB]
END
)}
こちらも例を図示してみると,次の画像のようになります。ここでは,ディメンションBから作成したセットで「x」と「y」を選択しています。

実演
パラメータを使う場合
一般的な話ではいまいち理解できないと思うので,サンプル - スーパーストアで実演しましょう。
まずディメンションBとして,[製品名]のパラメータを作成します。

ワークブックを開いたときにパラメータの中身も更新してほしいので,右下で「固定」でなく「ワークブックを開いている場合」に変更しましょう。

そして,ディメンションAとして[顧客名]も使って,次のような計算式を作成しました。

計算フィールドに適当に名前をつけ,行シェルフにて顧客名を分類してみると,たしかにパラメータで選択している製品を購入した([オーダーId]が存在する)顧客がTRUEで返されているようです。あとは,このBoolean型のデータピルをフィルタに使用するのみです。
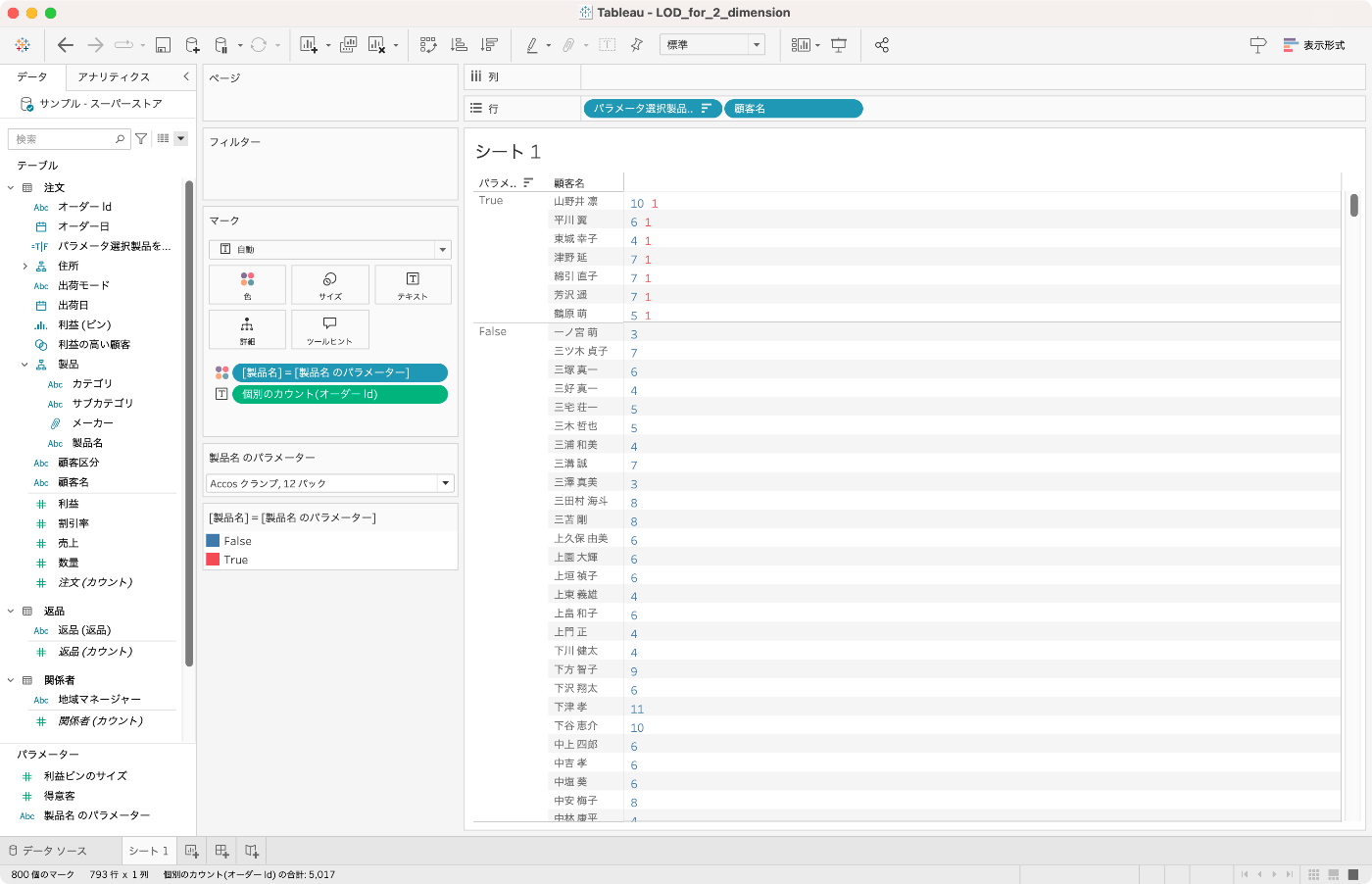
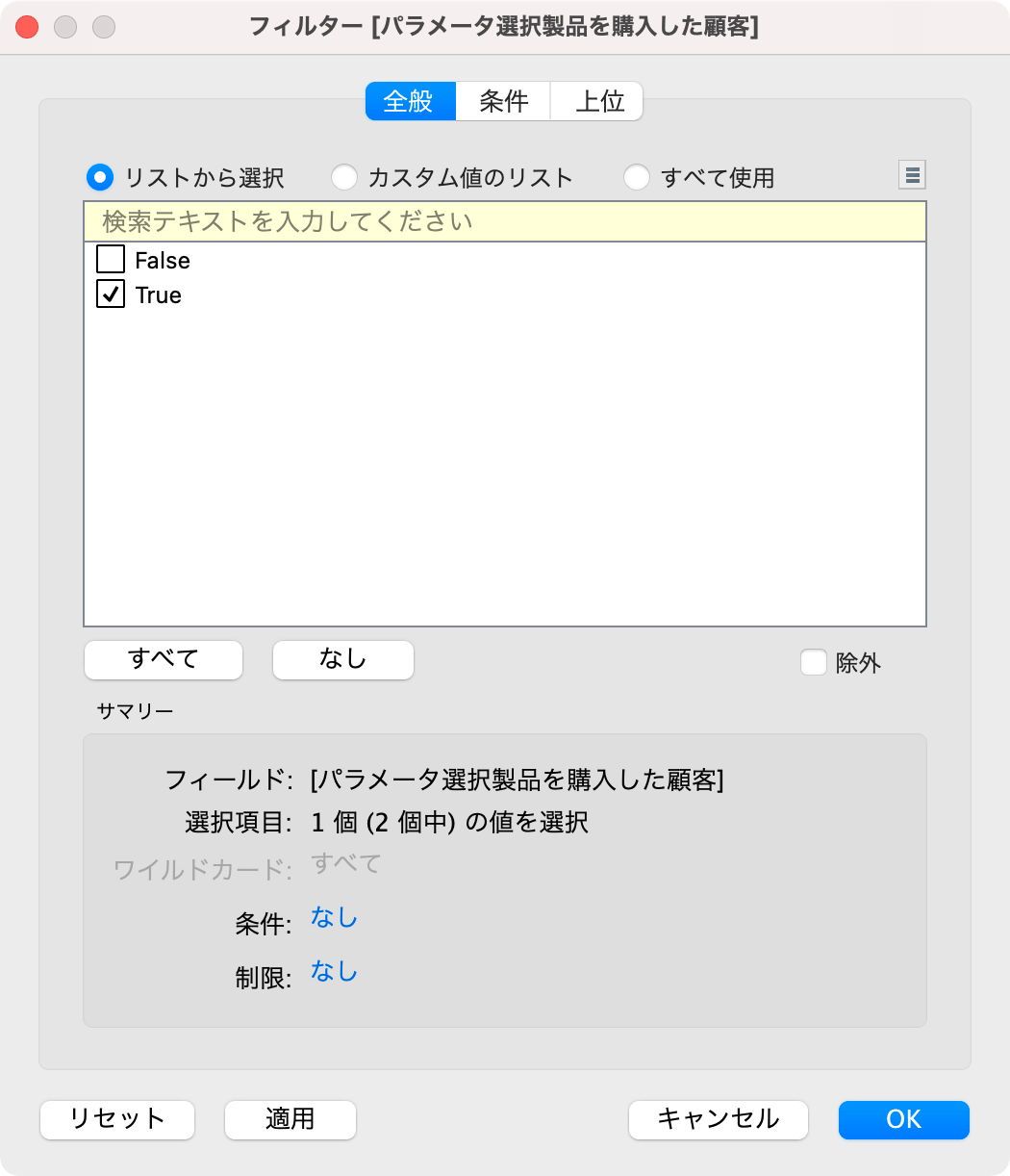
フィルタに追加して,TRUEを選択して,パラメータで指定した製品を購入した顧客に限定します。
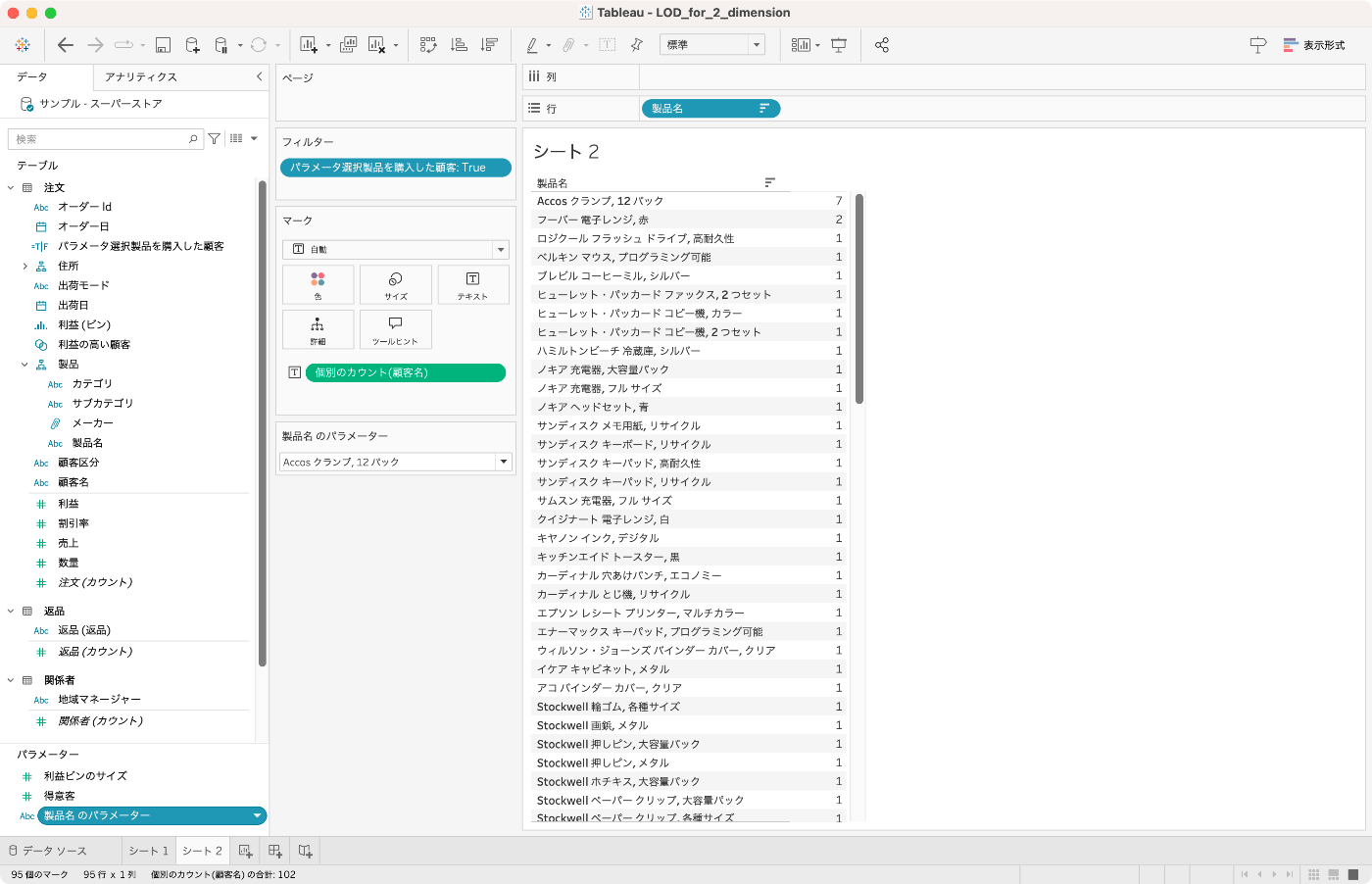
製品名ごとに顧客名をカウントしてみると,その製品を購入した顧客の数が出力されます。パラメータで選択した製品は当然フィルタされた顧客全員が購入しているので最多となりますが,その次の製品は,その選択製品を購入した顧客群でもとくに人気な製品といえることができます。
セットを使う場合
セットを使う場合も同様です。セットをまず[製品名]のメニューから作成します。このセットを用いて,次のような関数を作ってみます。セットはパラメータと違って複数選択が可能なので,単数でも複数でも活用できるように3種類関数を作ってみます。

fn2はパラメータのときの例と同様,顧客ごとと詳細レベルを指定したFIXED関数が0以上であるときにTRUEを返します。つまり,セットで選択された製品名をひとつでも購入している顧客の行がTRUEとなる関数です。

fn3は複数選択のときに効果を発揮します。セットで選択された製品群から購入した製品種類数を顧客ごとに算出して返します。選択した製品からもっとも最多の種類を購入した顧客をTRUEとして返したければ,後述のfn4と合わせて使います。


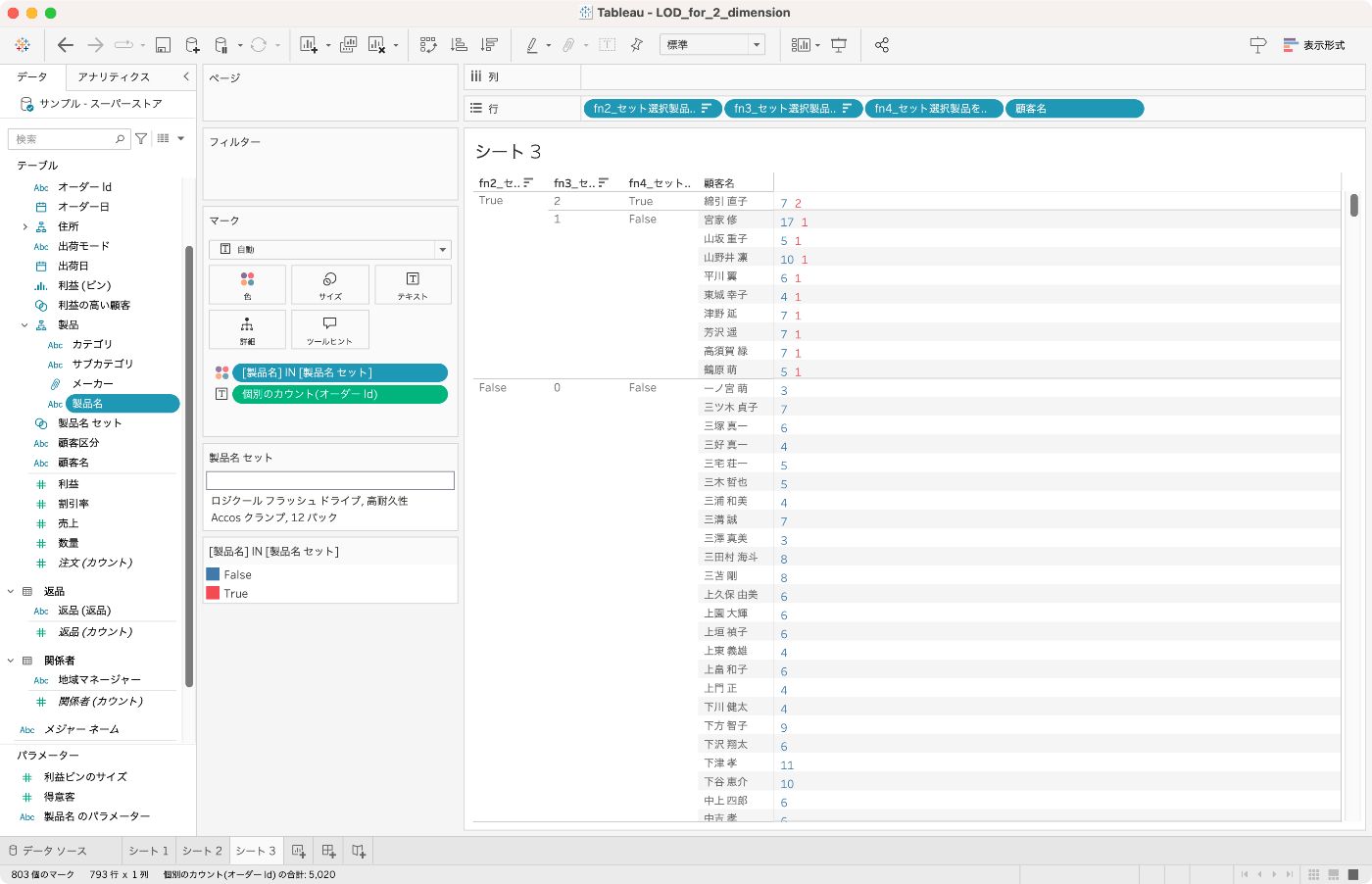
これらfn2, fn3, fn4を使用して,実際に出力したワークシートがこちらになります。fn3は数字を返す関数になり,複数選択した製品のうちすべてを購入した顧客はひとりしかいないようで,fn2 = TRUEとなっていてもfn3で異なる値が返っていることが確認できました。fn4は,fn3の最大値と等しい顧客だけをTRUEとするので,選択製品と最大限関係する顧客なのか少しでも関係する顧客なのかで,これらの関数を使い分けることとなります。
おわりに
自分の中で,使う場面が多いが少し概念として言語化しにくくて思い出すのに時間がかかる技術,について今回は説明してみました。言語化によって体系化できれば体得するのも簡単になるので,こういうことはこれからも続けていきたいですね。
余談
現在,弊社Rakutenではモバイルの社員紹介キャンペーンを実施しております。
下記リンクから,Rakuten会員でログインいただくと,回線変更で最大14,000ポイントがもらえるので,ご興味ある方はぜひアクセスしてみてください!
Discussion