[Tableau Certified Data Analyst試験に向けて] Tableauの関数全部見た話
はじめに
こんにちは。
いま社内の有志で,Tableau Certified Data Analystという認定試験を倒す会を立ち上げました。といっても個々人で勉強していくだけですが。
その勉強中に,Tableauで使うことができる関数のおさらいをやりました。ここでは自分が気になった部分とか,まとめておいたほうがいいなと思った部分をメモ的に残しておくことにします。
あとたまに公式ドキュメントの記述が間違っている部分があったので,もしなにかご存知のことがあればコメントいただけますと嬉しいです。よろしくお願いいたします。
更新履歴
- 2024/07/16:
## 日付型関数の引数についてを追記。 - 2024/08/16: 内容を少し補足。
公式ドキュメント
こちら。
気になった関数
文字列系
- 文字コード
-
ASCII(string)とCHAR(string)は逆関数。ASCII()は引数の最初の文字のASCIIコードだけを返す
-
- 大文字小文字操作:
LOWERUPPER-
PROPER- 頭文字は大文字,それ以外は小文字にする。
- 空白文字操作:
-
LTRIM,RTRIM:TRIMは両端の空白とる。真ん中は取らない。-
LTRIM_THISはBigQueryのみ。
-
-
SPACE(number): number分の文字数の空白を返す
-
-
FIND,FINDNTH:- 見つからない時は0を返す。返りは整数
-
FINDの3つ目の引数は,その指定番目以降に初めて出現する文字の位置,これは任意。 -
FINDNTHの3つ目の引数は,その指定番目に出現する文字の位置,これは必須。
-
SPLIT(string, delimiter, token number):-
<delimiter>を使用して<string>をトークンの並びに分割して(delimiter自身は消える),<string>の部分文字列を返します。 <token number>がマイナスなら後ろから遡った順に指定番目の文字が返る
-
-
STARTSWITH,ENDSWITH: 先頭末尾の空白が無視される。返りはBoolean。 -
MID(string, start, [length]): 長さを指定しない場合は指定番目の文字以降全部が返る
論理系
-
CASE-
ELSEで既定値を定められる。これが書かれてなければNULLがELSEで返る
-
-
IN:[Fields] IN [Set]という書き方もできる
数値系
-
ZN: 引数に文字列を指定するとエラーになる。IFNULLならなんでも食える。 -
MAX,MIN: 「引数と同じデータ型、または引数の一部が Null の場合NULL。」と書かれているが,指定したデータ列の一部がNULLであった場合は単に無視される。一方,MAX(1, NULL)はNULLになる。 -
AVG,MEDIAN,COUNT: NULL値は無視される -
SIGN:符号を返す。正なら1, ゼロなら0, 負なら-1 - 切り上げ切り捨て系
-
CEILING,FLOOR,ROUND: 切り上げ,切り捨て,四捨五入 -
INT:引数を整数としてキャストする。引数が式の場合、この関数は結果をゼロに最も近い整数に丸めます。INT(8/3) = 2INT(-9.7) = -9
- このあたり,なんかグラフ書いたら綺麗に見えたのでTableau PublicにPublishしてみた。これについては別記事で。
-
-
CORR,WINDOW_CORR- ピアソン相関係数
-
COT: コタンジェント -
COVAR: 標本共分散 -
RADIANSとDEGREESは逆関数 -
POWER: 累乗 -
DIV:- 割り算の商、整数部分
- ただし負の数については,
-5 = 3 * (-2) + 1ではなく,-5 = 3 * (-1) - 2のように,余りが負の形で計算される。 - また,MOD関数はTableauに存在しない。ここについて別記事にしようかなと思う。
-
PERCENTILE関数、百分位数の計算で使うっぽい
日付型データを返す系
-
DATE(),DATEPARSE(),MAKEDATE()- 認識パターン(フォーマット)を指定しない:
DATE()-
DATEは多くの標準的な日付形式を自動的に認識するため、認識パターンを指定する必要はない。しかし認識しない場合はDATEPARSEを使ってみること
-
- 認識パターン(フォーマット)を指定する:
DATEPARSE(),MAKEDATE()-
MAKEDATEは年月日でしか指定できない。「MAKEDATE(2020,4,31) = May 1, 2020のように日付が調整される」と書かれているが正確ではない。v2022.3とv2024.1だとNULLになる。 -
DATEPARSEはいくつかフォーマットがある。下記ドキュメント参照。
-
- 逆関数は
DATEPART(整数出力),DATENAME(文字列出力)
- 認識パターン(フォーマット)を指定しない:
https://help.tableau.com/current/pro/desktop/ja-jp/data_dateparse.htm#dateparse-関数を使用して計算を作成する)
-
NOW(),TODAY()のタイムゾーンが意図していないものになる可能性があるので要注意:
日付型データから整数を返す系,特にISO系
-
ISOQUARTER,ISOWEEK,ISOYEAR,ISOWEEKDAY- 指定された
<date>の ISO8601 週ベースの四半期の部分を整数として返す。 - 対応する関数は
QUARTER(),WEEK(),YEAR()。 - ちなみに
ISOWEEKDAY()はあるがWEEKDAY()はない。
- 指定された
-
ISO8601では週の始まりが月曜とされているので,2023-01-01(日曜)の
ISOWEEKDAY()は7になる。ISOWEEKDAY( 2023-01-02(月曜) )が1。 - また,ISO基準では2023-01-01(日曜)はまだ2022年という判定らしい。
-
DATEPART使う時とDAY使う時の違いがいまいち理解できていない
日付型関数の引数について
模擬試験を解いている最中,DATEPARSE()の引数の順番が違う選択肢があって見事に引っかかったので,あらためて確認してみた。
具体的には,DATEDIFF()などで日数を計算するときの単位とか,DATEPARSE()で指定してあげる書式とかは,一番最初に書く。 下でいう<date_part>, <date_format>の部分ですね。
DATEDIFF(date_part, date1, date2, [start_of_week])DATETRUNC(date_part, date, [start_of_week])DATEPARSE(date_format, date_string)
LOD系関数
- クイックLODなんて操作術あることを知る。便利。二つ目のオプションは新しいバージョンじゃないと厳しそうやけどv2022.3でできることを確認した。
-
EXCLUDEはユーザ指定計算式の中身をみて除外しようとはしない。- たとえば
[My Funciton] = DATEPART(’day’, [Order Date])と登録している場合,{EXCLUDE [My Funciton]:SUM([Profit])}と{EXCLUDE DATEPART(’day’, [Order Date]):SUM([Profit])}は結果が必ずしも一致しない。
- たとえば
- ここの最後の関連ページ、見ておきたい
表計算系関数
-
表計算の場合、すべての基本は
INDEX()なような気がする。RUNNING系もその順番で計算されてそう -
セル位置関係。計算の順序を別途指定する必要あり。
-
FIRST(), LAST()はそのパーティション内の最初(最後)の行「からの距離」。 -
FIRST()+INDEX()= 1 INDEX() + LAST() = SIZE()(固定値)-
INDEX()≥1。一行目が1 -
FIRST()≤0。一行目が0、下(右)に行くほど減る(小さくなる)。一行目が0なのはオフセット値が返るため。 -
LAST()≥0。最終行が0、下(右)に行くほど減る(小さくなる)。最終行が0なのはオフセット値が返るため。 - つまり
INDEX()以外常に上にある行が大きい数字になる。 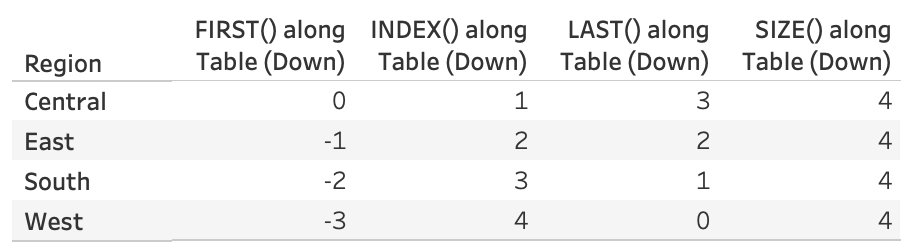
-
-
SUM([Profit]) * PREVIOUS_VALUE(1)は SUM(Profit) の累積積を計算-
PREVIOUS_VALUE()、SQLのLAG()関数みたいなものと認識
-
-
SCRIPT系:pyとかRが絡んできそう
ランク表計算系
-
RANK、既定は降順(降順で並べた時の順位を1から順番につけていく、ということ)。NULLは番号割り当てなし。- ランクをつける順番は1位から数えていくようなイメージ。
expressionを見る順番が既定では降順になるため,大きい数から1位, 2位, と順位付けされる。 - 「
RANK()関数を使用すると、値のセット (6、9、9、14) は (4、2、2、1) とランク付けされます。」だそうで。 -
RANK_DENSE(),RANK_MODIFIED()など,重複数のランク付けのルールが少し異なった関数が存在する。詳しくは下記画像や公式ドキュメントを参照。
- ランクをつける順番は1位から数えていくようなイメージ。
-
RANK_PERCENTILE、(既定では)昇順に並べたときに後ろに並ぶ値が100%に近く判定される。 既定が他ランク関数とは異なり昇順。- 上位のほうが100%だが、百分位数は0からどんどん増やしていって考えるから、ランクをつける順番は昇順になるイメージで記憶した。百分位数や四分位数での分布のしかたがイメージしやすい。ランクといえど分布なので,(既定では)小さいもの順に0%から数えていく。だから昇順。
- 「この関数を使用すると、一連の値 (6、9、9、14) は (0.25、0.75、0.75、1.00) とランク付けされます」と書かれているけど正確ではない。正しくは(0(=0/3), 0.67(=2/3), 0.67(=2/3), 1(=3/3))。 下画像はv2022.3での出力結果。
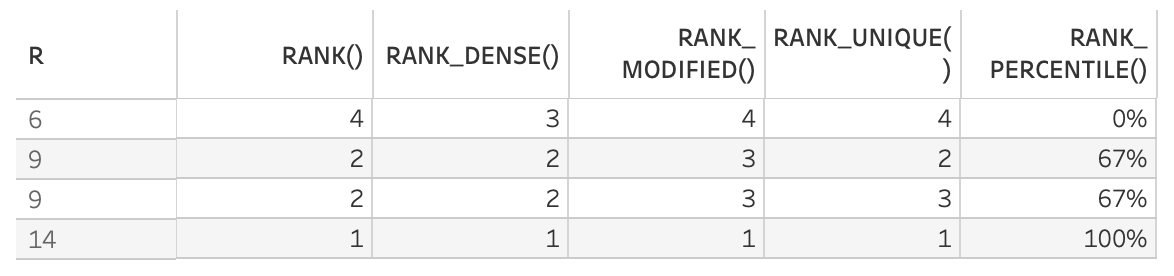
四分位数については,ここの記事が分かりやすいと感じました。
WINDOW系
-
WINDOW_AVG(SUM([Profit]), FIRST()+1, 0)は、2 行目から現在の行までのSUM(Profit)の平均を計算します、らしい。この場合FIRST()+1がstart,0がend。どれだけINDEX()の数値を遡るか。FIRST()+1=-3、つまり序列5位から3位分戻って序列2位がstartになる -
WINDOW_AVG(expression, FIRST(), 0)にするとRUNNING_AVGと一緒になりそう
ユーザー系
-
FULLNAME()- Display Nameが返ってくる
ISFULLNAME(<string>)-
USERNAME()- 登録されたユーザ名(メアドの一部?)が返ってくる。おそらくだがスペースとかは入らない
ISUSERNAME(<string>)-
ISMEMBEROF(<group name>)- サインインしてない時はNULLを返すらしい
USERDOMAIN()-
USERATTRIBUTE('attribute_name')- Tableau Cloudでのみ使用可能
USERATTRIBUTEINCLUDES('attribute_name', 'expected_value')
空間関数(ジオメトリ系)
-
AREA(Spatial Polygon, 'units')- spatial polygonの総表面積
-
LENGTH:2点間の距離? DISTANCEMAKELINE-
MAKEPOINT- これをレイヤーとして指定すれば,円グラフが重ねられる。
OUTLINE-
INTERSECTS:ポリゴン同士が重なっているかどうか
特定データソースにしか使えない系
-
get_json_object、hadoop hiveに接続してる時のみ -
group_concat、BQに接続してる時のみ
モデル系
- 一応表計算系らしい
- どうやらTabPy外部サービス上のモデルで計算されたものを導くらしい
MODEL_EXTENSION_INTMODEL_EXTENSION_STRMODEL_EXTENSION_REALMODEL_EXTENSION_BOOL
- 予測モデル関数ふたつ。これらはTabPy関係ない。
MODEL_PERCENTILEMODEL_QUANTILE
パススルー系関数(RAWSQL)
-
XPATH系(Hiveのみ):xml形式で書かれたものを処理できるっぽい。hiveやとそういうリターンがよくあるんかな - Tableauに関数を認識させずに変数処理を大元(データの上流側)に投げられる気がする
正規系
-
REGEXP関数、正規表現系かな?
その他系
-
HEXBINX,HEXBINY
おわりに
文字面で判断できる部分はいいですが,たとえば既定がどうとか,細かいテクニックとか,やはり知っておくに越したことはないですね。
Discussion