LangchainとLlamaIndex周り
両方ともGroqを使える。
LangchainとLlamaIndexへの雑感
どちらもOllamaを使えば無料である程度動くが、それではローカルで遊ぶレベルを超えない。
多くの人に使ってもらえるものを作るなら、OpenAI等のお金がかかるAPIを叩く必要がある。
そうするとユーザーからの課金が必要になる。
でも同じ課金をするなら、すでにChatgptがあるので、Chatgptを超える利便性を出す必要がある。
それは現状とても難しい感じがする。
社内向けのRAGとかなら道が在るような気がする。
しかし、それでもこれまでのキーワード検索でもそこそこ上手くはいっていたわけで、わざわざ意味検索を入れる必要があるかと言われると苦しい。
と思ったが、notionのキーワード検索とかかなり使いづらいことを思い出した。やっぱりキーワード検索と意味検索のハイブリッドがあったほうがいいかも。
LlamaIndexのllama-index-networks面白そう。
ざっとしか見てないけど、他の人が作ったRAGシステムを使うことができるっぽい。
新聞社や出版社とかがRAGシステムを公開してくれれば、それを使えるようになる。
RAGのマーケットプレイスが作られる日も近い。
langchainのStructured Output
出力の形を規定できる。最近Groqにも使えるようになった。
from langchain_core.pydantic_v1 import BaseModel, Field
class Joke(BaseModel):
setup: str = Field(description="The setup of the joke")
punchline: str = Field(description="The punchline to the joke")
model = ChatGroq()
model_with_structure = model.with_structured_output(Joke)
model_with_structure.invoke("Tell me a joke about cats")
# 出力結果
Joke(setup="Why don't cats play poker in the jungle?", punchline='Too many cheetahs!')
langchain
Llama3
Ollama経由のLlama3を利用したLangGraph。
Ollamaにはwith_structured_outputを使えないから、出力の形はpromptで制御するしかない。だからpromptが異常に長い。
Mistral
mistralを利用したLangGraph .
with_structured_outputで出力の形を制限できるから、Llama3のものと比べてpromptが短い。
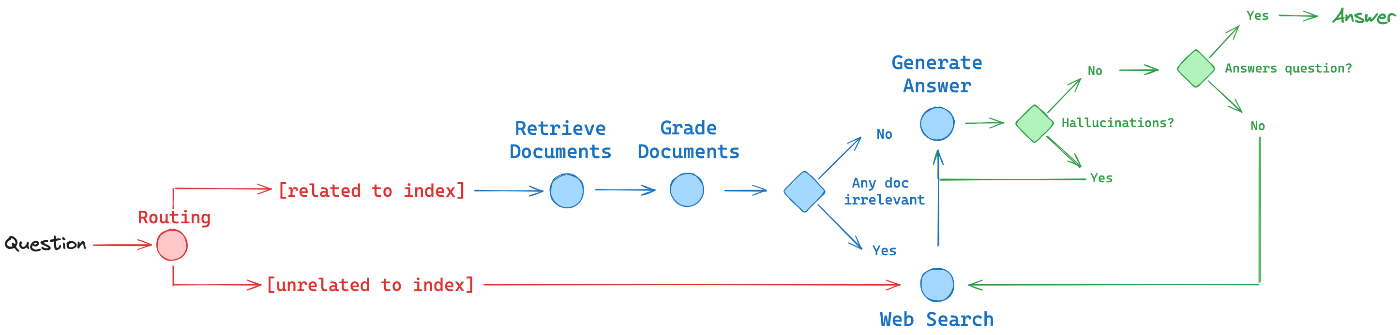
RAG
これのLangGraphの中では、3つのRAGのテクニックが使われている。
- Corrective-RAG (CRAG) paper uses self-grading on retrieved documents and web-search fallback if documents are not relevant.(検索されたドキュメントに対する自己評価を行い、ドキュメントが質問に関連していない場合はウェブ検索にフォールバックする)
- Self-RAG paper adds self-grading on generations for hallucinations and for ability to answer the question.(生成された回答が幻覚(hallucinations)を含んでいないか、また質問に適切に答えられているかを評価します。)
- Adaptive RAG paper routes queries between different RAG approaches based on their complexity.(質問の難易度に応じて、最適なRAG手法を選択する)
langchain
gradio, ollama(llama3), langchainを用いた簡易的なRAGアプリ