OpenAI playgroundで学ぶTemperatureとTop P
はじめに
昨今の生成AIでは、検索、テキスト生成、画像生成など機能が多岐に渡り、その結果、ビジネス上で利用機会が増えてきました。中でもLarge Language Models(大規模言語モデル)は汎用的に利用され、様々なパラメータを変更することで目的のニーズに対応することが可能です。そもそもLLMはどのように機能するのでしょうか?
LLMは、テキストのトークン(文字や単語などのかたまり)を1つずつ予測・生成していきます。このプロセスは以下のように進みます:
- 次に来そうなトークンを予測(学習データに基づいて実施)
- 確率の高いものの中からランダムに1つを選択
- 繰り返し
これらを高速に繰り返すことで、文章が生成されていきます。
文章の生成を行う際、temperatureやtop_pといったパラメータが存在し、これらは「選択」の部分に関わっています。
そこで、今回はtemperatureとtop_pの概要と使い方について解説していきます。
参考
Temperature -「確立」の調整
temperatureは、次の単語を選ぶ際のランダム性を調整するパラメータです (設定値の範囲は0~2) 。
上述した通り、LLMで文章を生成する際には、事前学習したデータに基づいて次に来るワードを予測し、生成します。この時、次に来るワードはprobabilitiesを保持しており、もっとも確率が高いトークンが連続的に選択されます。

このグラフは、言語モデルが次の単語を予測する際に、temperatureパラメータが確率分布に与える影響を示しています。temperatureが低い(例:0.5)場合、確率が高い単語がさらに強調され、「apple」のようなスコアの高い単語が圧倒的に選ばれやすくなります。一方で、temperatureが高い(例:2.0)場合は、すべての単語の確率が平準化され、低スコアの単語も選ばれやすくなるため、出力に多様性とランダム性が生まれます。
ユースケース
-
低い値(例:0〜0.3)
最も確率が高く、安全で予測可能な単語が選ばれやすくなる。そのため、事実に基づく要約、翻訳、質疑応答など、正確性や一貫性が求められる用途に適している。 -
高い値(例:0.8〜2.0)
確率の低い単語も積極的に選ばれるようになり、多様で創造的な文章が生成される。そのため、物語の創作、アイデア出しなど、独創性や多様性が重視される用途に適している。
Top P - 「候補リスト」の調整
top_pは、次の単語を選ぶ際の候補の範囲を調整するパラメータです。 (設定値の範囲は0~1)。
例えばtop_pの値を0.1に設定した場合、確率の高い順にトークンを並べていき、累積確率が 10% に達するまでのトークンを候補とします。以下のグラフの場合、appleだけが候補対象となります。

このグラフは、top_p(確率の累積上位)値を変化させたときに、どの単語がどの程度の確率で選ばれるかを示しています。top_pが小さいほど確率の高いトークンだけが選択肢に残り、出力が決定的になります。一方、top_pが1.0に近づくほど多くのトークンが残り、選択に多様性が生まれます。
ユースケース
-
低い値(例:0.1):
確率が非常に高い上位の単語群の中からのみ次の単語を選択する。これにより、文脈から外れた奇妙な単語が出現する可能性が減少する。 -
高い値(例:1.0):
確率に関わらず、全ての単語を候補として考慮する。ランダム性はtemperatureの設定に完全に依存する。temperatureの効果を最大限に引き出したい場合に設定。
OpenAIでは、temperatureとtop_pの両方を同時に変更することは推奨していません。通常は、どちらか一方を調整することでAIの応答をコントロールします。
実験
それでは、実際にこれらのパラメータを変えると応答がどう変わるか見てみましょう。
今回は、AIに「好きな料理は?」という共通の指示を与えてみます。
Temperature
左側:temperature: 0.1, top_p: 1.0
右側:temperature: 1.5, top_p: 1.0
【想定される結果】
temperatureの値が低い左側では毎回、決まった文章が返され、一方でtemperatureの値が高い右側ではユニークな文章が毎回生成されることが想定。
【実際の結果】
想定通り、右側の方がユニークなテキストが生成されたが、想定していたよりまともな返答が返ってきた。また、左側は何度同じ質問をしても決まった返答が返ってくるため、ランダム性が低くなっていることが確認された。
1 回目

2 回目

3 回目

Top P
左側:temperature: 1.0, top_p: 0.1
右側:temperature: 1.0, top_p: 1.0
【想定される結果】
top_pが0.1(左側)の場合、AIは確率が最も高い単語しか候補にできないため、決まりきった回答となる。一方でtop_pが1.0の場合、候補対象が増えるため、創造的な文章になる。
【実際の結果】
top_pが0.1と1.0の場合、生成されるテキストにほとんど差が生まれなかった。top_pの値を変更しても、temperatureで十分な確率分布の差が発生していた場合、ランダム性が下がり結果的に上位の候補が選択され続ける可能性がある。
1 回目

2 回目
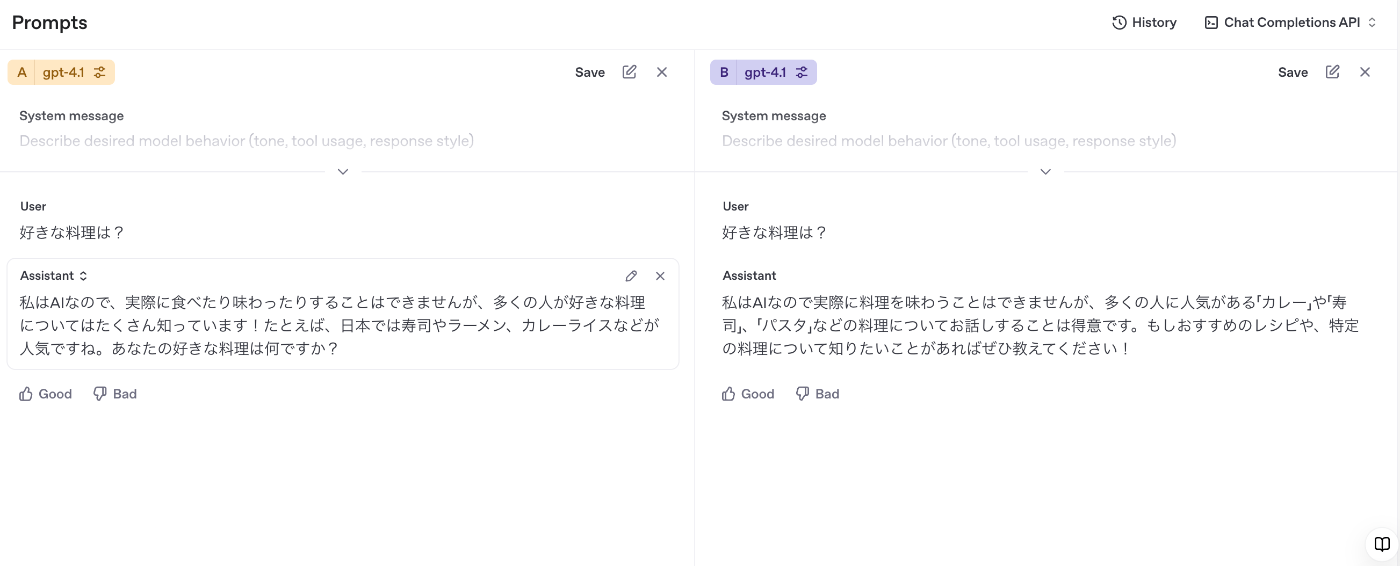
3 回目

まとめ
最後に、temperatureとtop_pの使い分けをまとめます。
-
temperature: 選択のランダム性を決めるパラメータ。 -
top_p: 候補リストの範囲を決めるパラメータ。
一般的には、まずtop_pを1に固定し、temperatureを調整することから始めるのがおすすめです。
参考
A Visual Explanation of LLM Hyperparameters
LLM Parameters Demystified: Getting The Best Outputs from Language AI
Discussion
「temperatureやtop_tといったパラメータが存在し」という部分ですがtop_pのtypoのように思いました。
コメントありがとうございます!修正しました。