🚫
Pythonの2次元リストの初期化ではまった話
はじめに
有名な話のようだが、Pythonの2次元リストの初期化で推奨されない方法を使ってはまってしまった。
具体的には *演算子を使ってこんな感じにしてしまった。
a = [[0] * 3] * 3
*演算子は同じものを繰り返すので、期待しているものを違うものができてしまう。
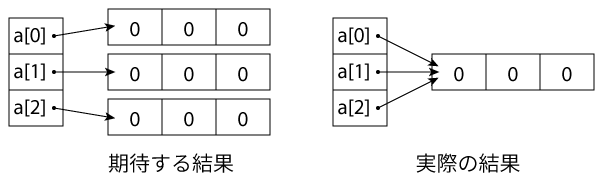
そうすると、とある値を変更した時、他の箇所まで変更してしまう
a[0][0] = 1
print(a)
出力結果
[[1, 0, 0], [1, 0, 0], [1, 0, 0]]
対処方法としては、内包表現を使う。そうすればこの問題は発生しない。
b = [[0 for _ in range(3)] for _ in range(3)]
b[0][0] = 1
print(b)
出力結果
[[1, 0, 0], [0, 0, 0], [0, 0, 0]]
1次元リストでも問題になるのか?
*演算子は同じものを繰り返すのだとすると、1次元のリストでも問題になりそうな気はする。例えばクラスを使った以下のような例
from dataclasses import dataclass
@dataclass
class A:
value: int
if __name__ == "__main__":
a = [A(0)] * 3
print(a)
a[0] = A(1)
a[1].value = 2
print(a)
出力結果
[A(value=0), A(value=0), A(value=0)]
[A(value=1), A(value=2), A(value=2)]
リストaの要素はすべて同じオブジェクト(インスタンス)を指しているので、a[1]のようにオブジェクトのメンバ変数に代入すると他の位置のものも変更される(ように見える)。a[0]のように別のオブジェクトに置き換えれば問題ない。
Pythonではid()関数でオブジェクトに付与された識別子を出力できる。そうすると内包表現では、リストに入っているのは同じA(0)であるが、全部異なるオブジェクトであることがわかる。
a = [A(0)] * 3
print(list(map(id, a)))
b = [A(0) for _ in range(3)]
print(list(map(id, b)))
出力結果
[4331858704, 4331858704, 4331858704]
[4330629040, 4331565520, 4331563168]
内包表現じゃだめなのか?
じゃぁ紛らわしいのになぜ*演算子での行列初期化法があるのか?理由としては「速いから」らしい。
start = time.perf_counter()
a = [0] * N
print(time.perf_counter() - start)
start = time.perf_counter()
a = [0 for _ in range(N)]
print(time.perf_counter() - start)
実行結果
0.008868749951943755
0.11417754192370921
10倍以上の差がでてしまっている。しかし、上述のようなクラスを生成する場合だけでなく、整数が並ぶリストでも速くなるものだろうか?実は内包表現で初期化した場合、同じ0に見えるけど違ったりするのだろうか?
if __name__ == "__main__":
a = [0] * 3
print(list(map(id, a)))
b = [0 for _ in range(3)]
print(list(map(id, b)))
出力結果
[4310421912, 4310421912, 4310421912]
[4310421912, 4310421912, 4310421912]
確認してみたが、整数のリストの場合、内包と*演算子でもidは同じであった。おそらくメモリ確保の方法とかが異なるのではないかとは思う。
まとめ
速度をそこまで気にする必要がないなら、内包表現の方がいいような気がする。特にクラスや多次元リストを使う人は。
Discussion