書籍の内容を深く理解するためにLLMのファインチューニングをする
目的
既存のLLM(大規模言語モデル)を使用して書籍の内容でファインチューニングを行い、書籍の理解を深める方法を探る。
ただし、その前提としてあくまで個人的な利用範囲に留めること。
ということで、いってみましょー
当然、どこいつ時なんであれ軋轢を生みたいわけじゃないしね!
つってすでにちょっと始めちゃってはいるんですよね
まずは共通で必要になるであろう、書籍をOCRするとこから始めます。
手順
まずはLLMをファインチューニングする手順を示します。
いきなりChatGPTの返答になって手抜き感パないけどこんな感じ。
プロンプトは以下。
目的は「大規模言語モデルを一冊の本でファインチューニングし、その本に対する質問に正確に回答できるようにすること」です。
次に、条件を示します。
基本的にはローカル環境で実装を行いたいです。
GPUは1つ、GeForce RTX 4090 です。
予算は50ドル前後に収めたいと考えています。
実装にかけられる時間は断続的に20時間程度です。
これらの条件を満たすために、どのような方法が考えられるでしょうか。
条件は割りと適当。
対するChatGPT-4 による回答は以下。(Markdown が適用されるよう、コードブロックにしてません)
-
モデル選択:
- 質問応答タスクに対しては、事前学習済みのBERTやT5のようなトランスフォーマー型モデルが適しています。これらのモデルは、Hugging FaceのTransformersライブラリで利用可能です。
-
ファインチューニング:
- Hugging FaceとDeepSpeedの組み合わせを使用することで、ローカル環境でのファインチューニングが簡単かつ効率的に行えます。DeepSpeedは、メモリ使用量を削減し、計算効率を向上させるための技術を提供しています。
-
データ準備:
- ファインチューニングのために、本のテキストデータと、それに対する質問と回答のペアを準備する必要があります。これにより、モデルは質問に対する正確な回答を生成する方法を学習します。
-
コスト管理:
- 予算が50ドル前後と限られているため、クラウドベースのリソースは避け、ローカルのGPUリソースを利用することが重要です。また、オープンソースのライブラリとツールを利用することで、コストを抑えることができます。
-
時間管理:
- 20時間の実装時間が設定されているため、効率的な実装とテストを行うための計画が必要です。また、可能な限りシンプルな実装を選ぶことで、時間を節約することができます。
-
実装のサポート:
- 日本語のドキュメントやチュートリアルが利用可能であるため、Hugging FaceとDeepSpeedを使用する方法が選択肢として適しています。
-
ハードウェアの利用:
- GeForce RTX 4090 GPUは高性能であるため、ローカル環境でのファインチューニングに適しています。
ってことでLongLoRAとか様々やりたい衝動を抑えつつ、まずは言いなりに 「Hugging FaceとDeepSpeed」でやっていく。
データを準備する
一旦 「Hugging FaceとDeepSpeed」でやっていくと決めたので、ファインチューニングするためのデータ準備をする。
今回は電子書籍ですね。
電子書籍をテキストデータに変換する
考えうる選択肢がいくつかありますね。
- Kindle 電子書籍を〇〇〇してOCRする。
- PDFで提供されている電子書籍をOCRする。
- ネットで公開されている電子書籍(的なもの)をスクレイピングする。
1 はAmazonからBANされそうなので全力で回避します。
2か3でやってみることにしましょう。「PDFからOCR」この需要は抑えておきたい。
前提の通りあくまでも個人利用です。
ただ Kindle の電子書籍をPDF化する手順のリンクだけはおいてお...かないことにします。どうしてもやりたければ検索してください。
基本的にKindleも楽天ブックスもDRM解除の方向では現状無理と考えてもらって良いです。
別のアプローチを取る必要があることだけいい添えておきます。
題材選び
「A Philosophy of Software Design」にしました。
日本語訳がなく、要約はチラホラ見かけますが詳細な質問にも答えられるようにしてみたかったためです。
PDFは検索して拾います。「Bingが検索結果に出してる」をエクスキューズに追加しておきます。
PDF ファイルを OCR する
Google の OCR のやつとか tesseract とか色々試したんですが、Adobe の Acrobat Reader が一番手軽で精度が良さげでした。自動化するなら python で書くのが一番良い。でも今回は Acrobat Reader でやります。
本来はこの OCR の精度を計測、共有するべきなんでしょうが、今は昔、覚えてない。
今回は Acrobat Reader での OCR 手順だけで勘弁してつかぁさい。
手順です。
- Acrobat Reader で PDF を読み込む。
- 「スキャンとOCR」を選択
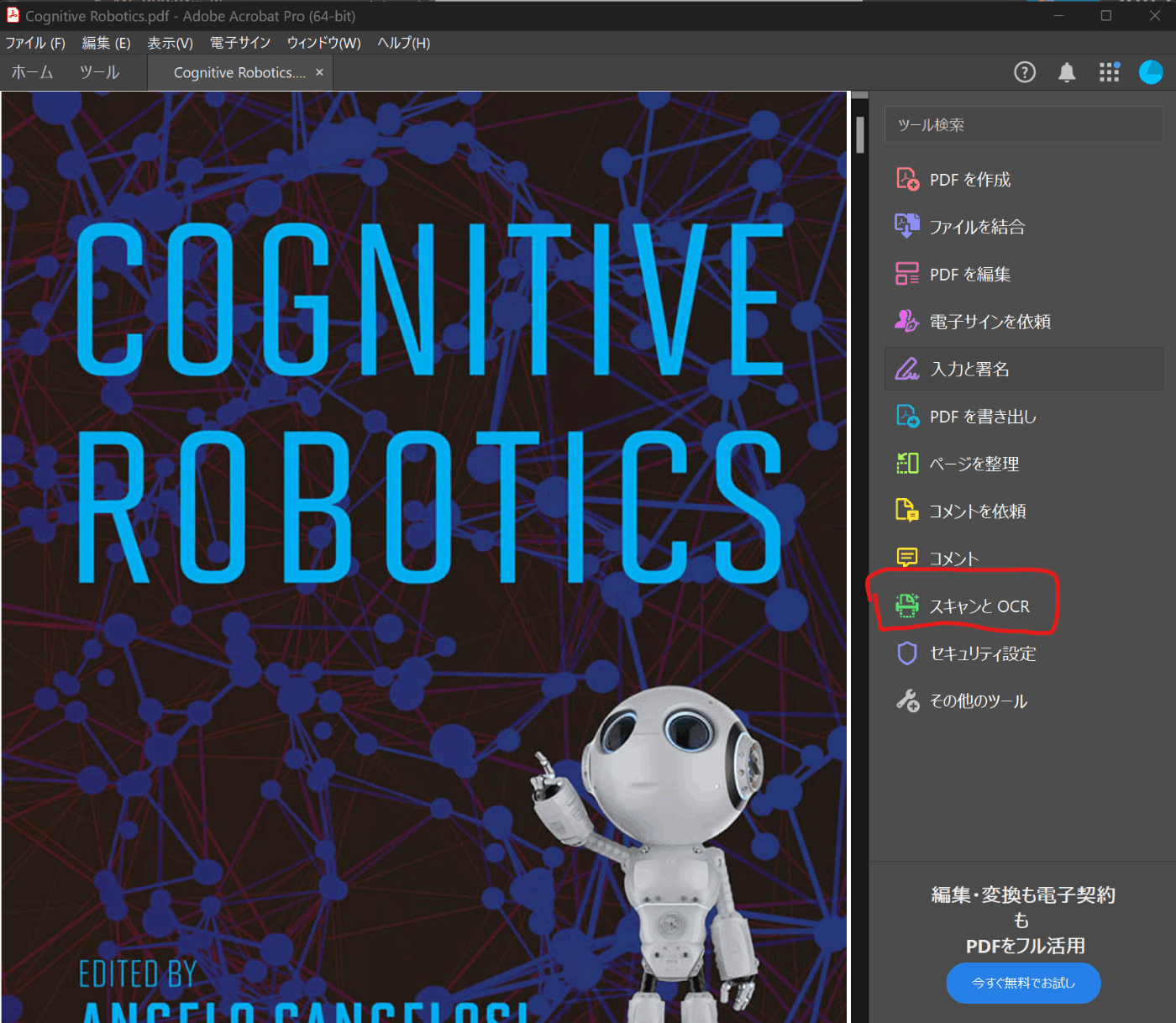
- 番号をつけた赤枠の設定を行う。1「テキスト認識」→ 2「言語を英語に設定」
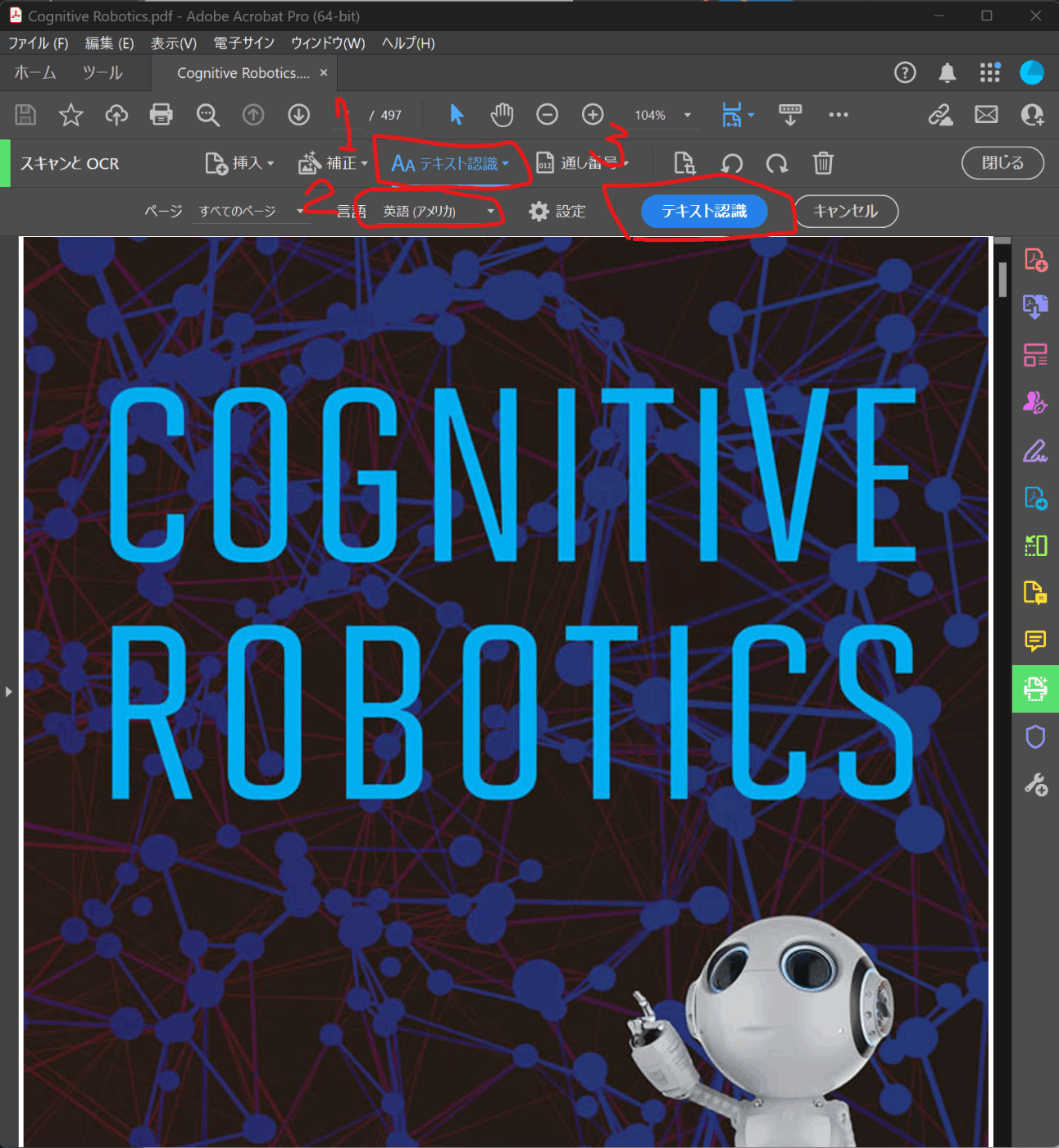
- 上図の3の「テキスト認識」を押して待機してください。PDFのサイズによって10分くらいかかることもあります。マシンのメモリなどにも依存するでしょう。
- 終わったら全選択してテキストファイルに保存します。この時点では意味不明な単語が混ざっているはずです。次でそれを修正していきます。
※ 画像で読み込んでるのが 「A Philosophy of Software Design」でないのは気にしないでください。MITの教科書を読み込もうとして失敗したやつです。
※ この手順を踏まずにPDFを全選択して文字列なりを取得することも可能だしできるならそちらのほうがいい ですが、それができないケースを想定してます。
閑話休題
Cursor すごすぎない??