📝
【論文メモ】Depth Estimation Matters Most: Improving Per-Object Depth


タイトルが長いので↑は途中で切り捨てています。正式なタイトルは↓です。
| タイトル | Depth Estimation Matters Most: Improving Per-Object Depth Estimation for Monocular 3D Detection and Tracking |
|---|---|
| リンク | https://arxiv.org/abs/2206.03666v1 |
| 著者 | Longlong Jing, Ruichi Yu, Henrik Kretzschmar, Kang Li, Charles R. Qi, Hang Zhao, Alper Ayvaci, Xu Chen, Dillon Cower, Yingwei Li, Yurong You, Han Deng, Congcong Li, Dragomir Anguelov |
| 投稿日付 | 2022/06/08 |
1. どんな論文か?
最近、単眼カメラ画像からの3D認識が低コスト、省電力、認識範囲の広さなどから期待も高く熱い。一方で、単眼の3D物体検出精度はLiDARに比べると劣ると言われている。
本論文では
- 単眼カメラでの3D物体検出・追跡において物体毎の深度推定精度が物体検出・追跡における精度のボトルネックであることを特定した。
- 2D RGBとpseudo-LiDARを組み合わせて深度推定の精度を向上させた。
- 深度推定の精度が改善されたモデルで3Dの物体検出・追跡をおこなったところ、精度が向上してSOTAとなった。
2. 先行研究と比べてどこがすごいか?
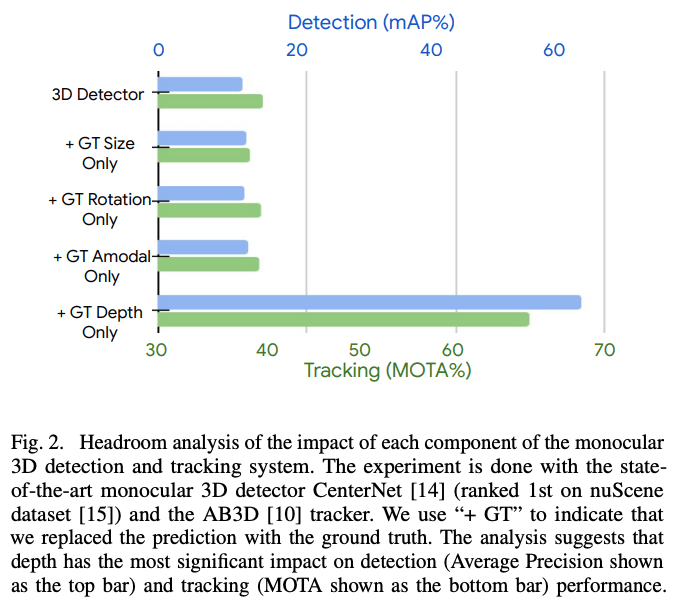
- 3D物体認識のメジャータスクは物体検知と追跡であるが、どのコンポーネントがパフォーマンスに影響を与えているのかわからなかったので現行のSOTAモデルでインパクトを調べた。
- コンポーネントをGTと置き換えながら精度を確認したところ、深度が最もインパクトが大きかった。
- 先行研究では、単眼での3D物体検出にRGBと推定深度マップの両方を活用したものは少なく、かつ深度推定精度の改善に着目したものはなかった。
3. 技術や手法の要旨
提案手法のoverview
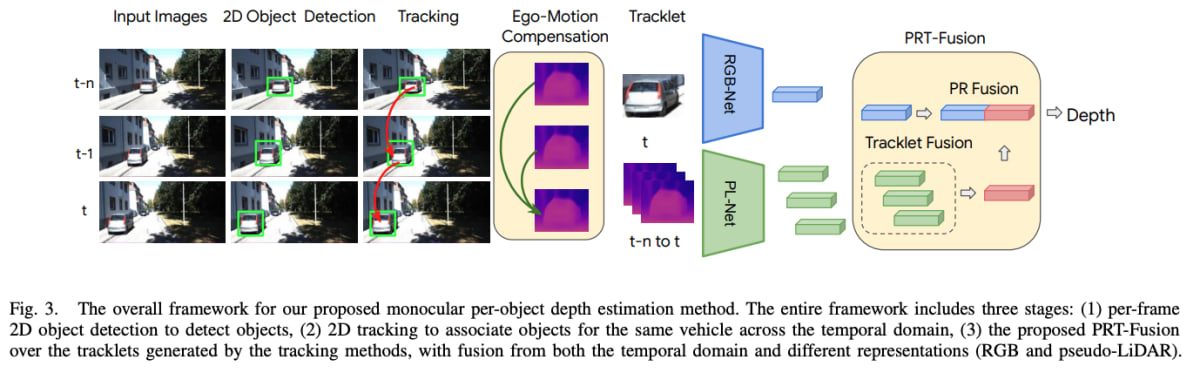
- (事前訓練されたモデルで)2D 物体検出を実行し、フレーム全体で検出物体を追跡して、各物体のTracklet特徴を作成する。
- フレーム全体の物体のpseudo-LiDAR表現と現在のフレームのRGB画像特徴を作成する。
- 各画像で密な深度推定→pseudo-LiDARへ変換(深度マップをカメラモデルで点群へ変換後、物体検出のボックスで切り取る)→ニューラルネットワークでpseudo-LiDAR表現を抽出
- Ego-motion compensationは、各Tracklet特徴内のすべてのpseudo-LiDARパッチに適用され、それらを同じ座標系に変換する。
- 単一画像から深度を直接推定することは難しいので、時間方向の情報(カメラの動き)を使って一貫性を補強する。そして時間ウィンドウで融合する。
- 現在のフレームのRGB画像特徴と時間方向に融合されたpseudo-LiDAR特徴を融合して、物体ごとの深度を推定する。
実際の実装では、
- RGB特徴抽出にはバックボーンがResNet50のCenterNetとCenterTrack(nuScenes datasetでの単眼 3D検出タスクでSOTA)を使用
- Pseudo-LiDAR特徴抽出にはPatchNetを使用
- 2Dトラッキングにはカルマンフィルタを使用(より洗練されたものを使えばさらに精度が改善すると考えている)
4. どのように検証したか
深度推定タスク
- Waymo Open Dataset
- KITTI Detection Dataset
- KITTI MOT Dataset
評価指標
- 既存のベンチマークに従い、平均相対誤差(Abs Rel)、二乗相対誤差 (Sq Rel)、二乗平均平方根誤差(RMSE)、平均 (
log_{10} RMSE_{log} _{i}
実験結果
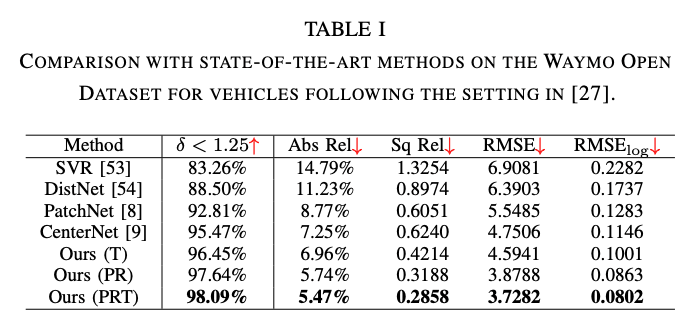
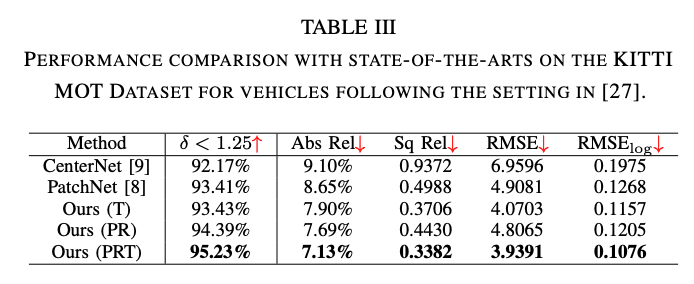
他の手法と比べ、pseudo-LiDAR特徴とRGB特徴を使うアプローチ(PR)は深度推定の精度が向上した。また、Ego-motion compensation(T)は単体でも既存手法より改善し、PRTでさらに精度が向上した。

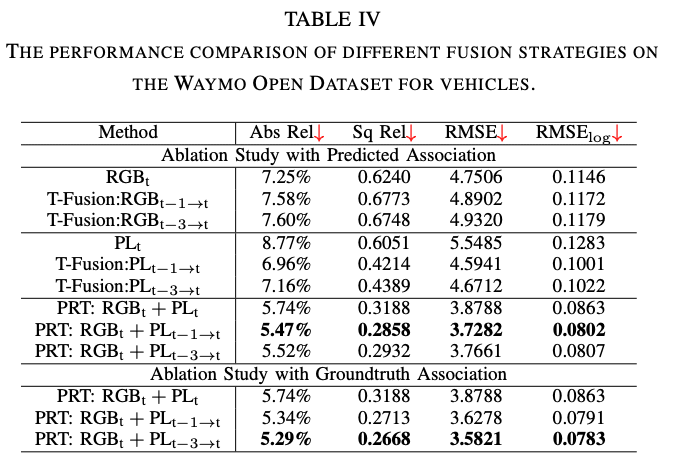
アブレーションスタディ
- RGBのTracklet融合は機能するか(Ego-motion compensationなし)?
- 僅かな改善となった(下表の一番上のグループ)。座標系がずれると一貫性を学習しにくくなるとの見解。
- Tracklet融合は、pseudo-LiDARベースの深度推定をどのように改善するか?
- 下表の2番目のグループ。1フレームだけでも時間方向に融合すると精度が大幅に改善した。時間方向のフレームを増やすことのメリットはなさそう。
- PRTの融合は役に立つか?
- 下表の3番目のグループ。1、2番目の結果と比較しても精度に貢献していることは明らか。ただ、(2D物体検出と追跡の予測にはノイズがあるため)時間方向のフレームを増やしてもパフォーマンスが改善するとは限らない。
- ノイズによってパフォーマンスはどのように影響を受けるか?
- 下表の4番目のグループ。GTの追跡結果を利用すると時間方向のフレームを増やすと精度が改善していく(2D物体検出と追跡の品質が上がればさらに深度推定の精度が上がる可能性がある)。
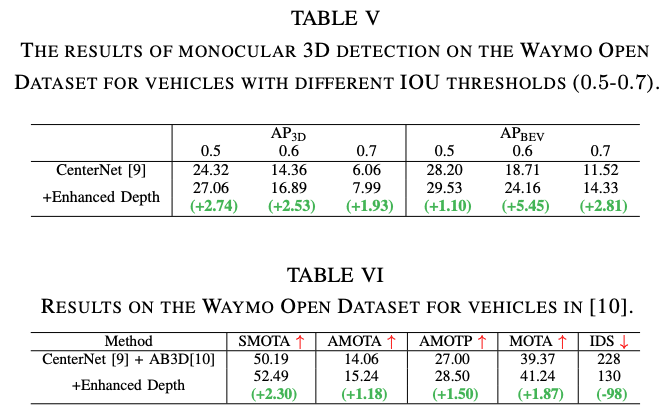
改善した深度推定モデルを使用した単眼3D物体検出と追跡の結果
定量結果
深度推定部分を置き換えて実験した結果が以下となる。改善している。
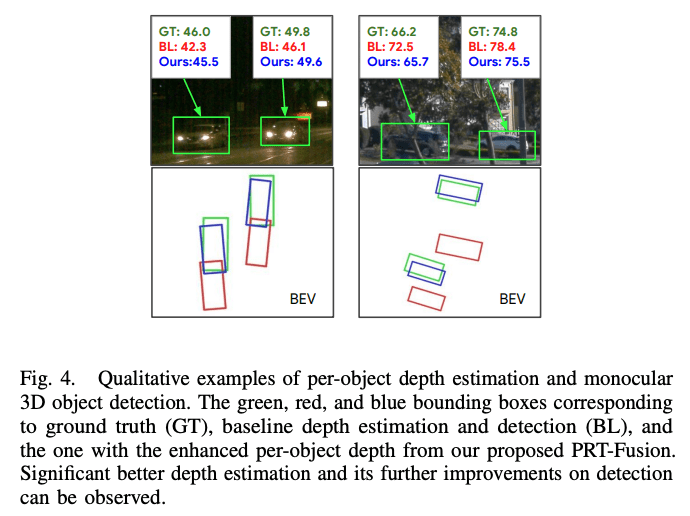
定性結果
視覚化するとベースラインと比較して、深度の推定結果と追跡のIDスイッチエラーが改善していることが確認できた。

5. 感想
Waymo(Google)の論文は検証が丁寧で良い。単眼の深度推定の精度が向上していくとかなり面白いことが起きそうだなと思った。そして、Pseudo-LiDARというアプローチを知ったので以下を読む。
6. 次に読むべき論文は?
- Pseudo-LiDAR論文
Discussion