【論文メモ】Instance Segmentation with Cross-Modal Consistency


| タイトル | Instance Segmentation with Cross-Modal Consistency |
|---|---|
| リンク | https://arxiv.org/abs/2210.08113 |
| 著者 | Alex Zihao Zhu, Vincent Casser, Reza Mahjourian, Henrik Kretzschmar, Sören Pirk |
| 投稿日付 | 2022/10/14 |
1. どんな論文か?
リアルワールドでの個々の物体の識別とセグメンテーションはロボティクス、自動運転にとって重要かつチャレンジングなタスク。自動運転など安全性が重要なシステムでは環境を認識するために複数のセンサー(カメラ、LiDARなど)から補完的な情報を得ている。
一方で各センサーは適切な条件下でのみ機能(カメラは光、LiDARは天候の影響を受ける)し、これらの時系列データは自然と生成はできるが、ラベル付けが困難という課題もある。
この論文は、
- RGB画像と点群の一貫したインスタンス埋め込み表現を得るために新しいクロスモーダルコントラスト損失を提案した。
- オプティカルフローを使用して動画から疑似GTを生成する方法を提案し、クロスモーダルコントラスト損失を部分的にラベル付けされたデータセットに拡張できるようにした。
2. 先行研究と比べてどこがすごいか?
- ロボティクスの文脈でマルチモーダルアプローチの先行研究はあったが、マルチモーダルセンサーアプローチはなかった。
- KITTI-360およびCityscapesベンチマークでの実験では、RGBとRGB+時間軸を比較すると最大1.9mAP、RGBとLiDAR+時間軸を比較すると最大1.7mAP、インスタンスセグメンテーションの品質が改善した。
マルチモーダルアプローチの先行研究
3. 技術や手法の要旨
提案手法のoverview

処理が複雑だが要約すると各モダリティ、時間軸上でも一貫したインスタンス埋め込み表現を得られるように対照学習をしている。
ただ、単純には適用できないので疑似GTの生成などを行なっている。
- RGB画像とLiDAR画像用にそれぞれネットワークを用意する(本論文ではPanoptic DeepLabを改良したもの)。ネットワークはピクセル毎に32チャネルの埋め込み表現を出力する。
- Panoptic DeepLabはPanoptic-DeepLab:A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic SegmentationをベースとしてバックボーンにXception-71を使用し、decoderのインスタンスセンター予測とインスタンスセンター回帰の代わりにASPP(Atrous Spatial Pyramid Pooling)とインスタンス埋め込み予測(32チャネル予測)用のdecoderモジュールを追加している。
- 対照学習で同じインスタンスとの埋め込み表現の距離は近く、異なるインスタンスとの埋め込み表現の距離は離れるように学習する。
- フレーム毎に全てのインスタンスに分散させた8192ポイントの埋め込みをランダムにサンプリングする。同じインスタンスのものは正例、それ以外は負例となる。
- インスタンスセグメンテーションの損失にはA Simple Framework for Contrastive Learning of Visual RepresentationsのNT-Xentを使用。また、安定した結果を得るために埋め込みのノルムに正則化損失も追加した。
- 各モダリティ、時間軸上で一貫したラベルIDを持っていれば、1-2を全ての入力データに適用できるがそうではないデータセットがほとんどなので、オプティカルフローを使った疑似GT生成を行う。
- 個別の入力にラベルが与えられている場合では、事前学習されたオプティカルフローを使って隣接フレームにラベルの情報を移動させて最近傍リサンプリングを適用する。具体的にはOcclusion Aware Unsupervised Learning of Optical Flowに従っているらしい。
- セマンティックセグメンテーションでは各フレームのマスクを予測する。背景をフィルターし、インスタンス内のセマンティックセグメンテーション予測の多数決により、クラスター化された各インスタンスにクラスを割り当てる。また、平均スコアを使用して、各マスクの信頼度を生成する。
- 推論時にはSemantic Instance Segmentation with a Discriminative Loss Functionで提案された平均シフトアルゴリズムの変形を適用することで、ピクセルごとの埋め込みをクラスター化する。
- 埋め込み空間内のポイントをランダムにサンプリングし、サンプリングされたポイントからしきい値 m (=0.1)未満の ([0, 1] 内にスケーリングされた) コサイン距離を持つすべてのポイントを見つける。
- 次にサンプリングされたポイントを先ほど見つけたポイントの集合の平均にシフトすることで反復し、収束または反復の最大数に達するまで繰り返す。すべてのピクセルがクラスター化されるまでこのプロセスを繰り返す。
- この方法ではマスク間のトランジションで誤ったマスクが生成され、境界に沿って薄いアーティファクトが生成されることがわかったため、これを補うために面積と周長の比率がしきい値 r (=4未満)のマスクを除外する。この方法だと画像全体の距離を計算するため、各マスクの接続性に関する仮定がないため、任意に分散したインスタンスを検出できる。
4. どのように検証したか
データセット
- KITTI-360 Dataset
- カメラ、LiDAR、時間軸上で一貫したラベルを持ったデータセット
- LiDARでモデルを学習する際は、Range Conditioned Dilated Convolutions for Scale Invariant 3D Object Detectionで提案された点群の距離画像表現を使用。64×2048の画像から、カメラの視野に対応する中央の64×512パッチをトリミングし入力とする。
- 検証データが提供されていないため、学習データを分割してアブレーションスタディを実施。
- Cityscapes Dataset
- 一貫したラベルIDがないデータセット
- 疑似GTのためにWaymo Open Datasetで学習したWhat Matters in Unsupervised Optical Flowで提案されたUFlowを使用して、各フレームのラベルを時間軸上に移動させていく。オクルージョンやその他のエラーなどをフィルター処理するために、フローモデルによって生成されたオクルージョンマップを使用。
- クラスIDを割り当てるため、Cityscapesで事前学習したPanoptic Deeplab(Xception-71)を使用している。検証でのmIOUは68.8%であった。
入力データ
- フル解像度の入力を使用。
- カメラ画像はランダムに反転、スケーリング、トリミング or パディングした。さらにランダムなガウシアンブラー、ジッターの明るさ、コントラスト、彩度、色相を使用。
- 時系列データについては、画像の各ペアに同じ拡張を適用した。
- LiDARデータの拡張は反転のみを適用し、反転がカメラ画像と一致するようにした。
学習
- Adam
- 5エポックの線形ウォームアップ
- 2.5e-4の初期学習率と10エポックごとに減衰係数1.2の指数関数的減衰
- KITTI-360データセットはバッチサイズ128。
- Cityscapesデータセットはバッチサイズ32。
全ての実験で推論時のTTAは行なっていない。
KITTI-360での結果

アブレーションスタディ用の小さなデータセットなのでmAPはテストデータで見る値よりも小さくなる。
対照学習のためにモダリティや時間方向の情報を追加していくとmApが改善されていく。観察できた全体的な傾向は、自転車、オートバイ、ライダー、トラックなどの稀なクラスが大幅に改善され、主要なクラスの自動車が僅かに劣化した。
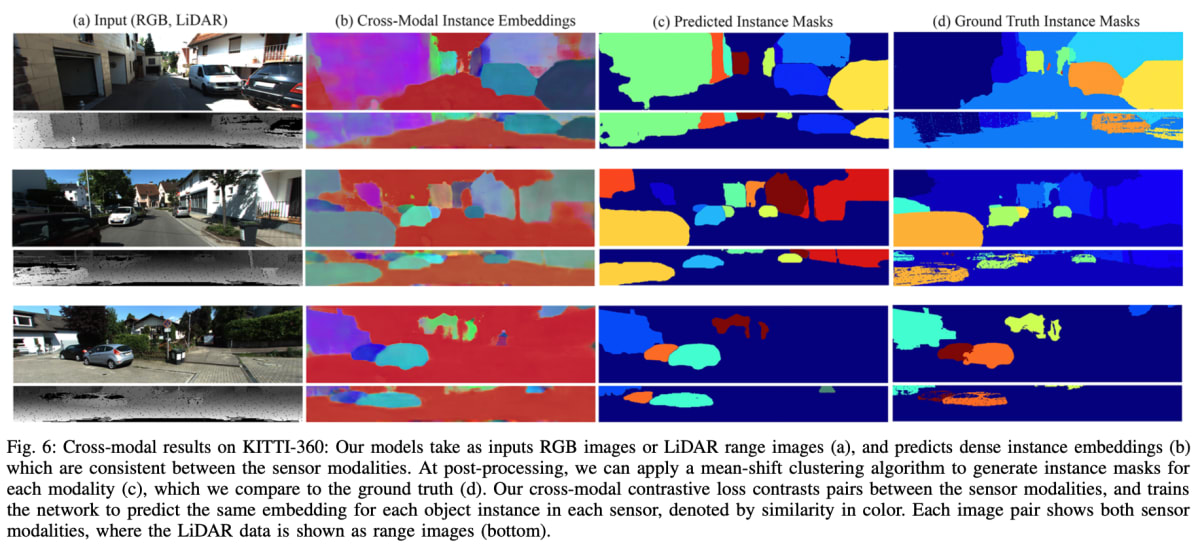
定性的な例として、↑では各モダリティで一貫した埋め込みを予測できている。

3D LiDARのインスタンスセグメンテーションでは対照学習によってmAPは改善しなかった。著者らは対照学習に必要な2Dラベルは3Dラベルを射影してCRFを適用することで生成されるため、通常の3Dラベルよりもノイズが多くなり、有用な信号を提供できていないと分析。

Mask-RCNNをベースラインとして比較。著者らは執筆時点で同じ検証セットを利用できなかったが、同じ分割であればより良い結果を得られると述べている。
Cityscapesの結果

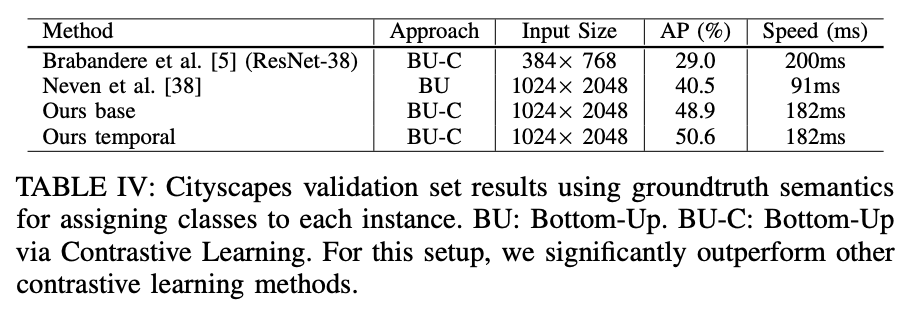
TABLE IVにあるように、提案手法が含まれるボトムアップアプローチの中ではパフォーマンスは優れた結果となった。一方でTABLE ⅢにあるようにトップダウンアプローチのPanoptic DeepLabに比べると精度、速度共に劣る結果となっている。著者らはPanoptic DeepLabはインスタンスセンターの予測が必要で、インスタンスが識別可能なセンターと何らかの形式のNMSが要求する手法であると述べている。

定性的な例として、↑では頑健に正確な表現が得られている。
5. 感想
やっていることが複雑で要約しながらも処理が正確に理解できない部分が多々あった。そしていまいちありがたさがわからない論文でもあった。関連論文を読んで理解を深めたい。
6. 次に読むべき論文は?
引用されていた関連論文たちを読む。
Discussion